 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeLFusion: Synthesizing Music from Image and Language Cues using Diffusion Models
Paper and Code
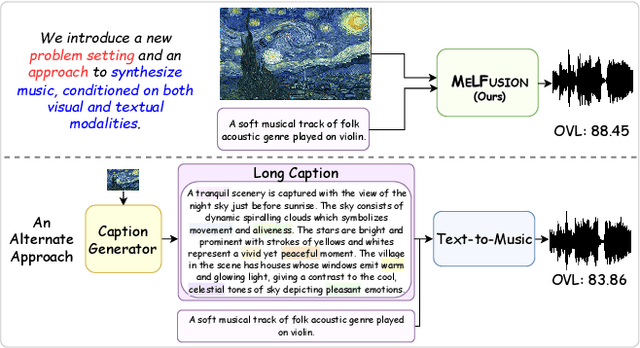
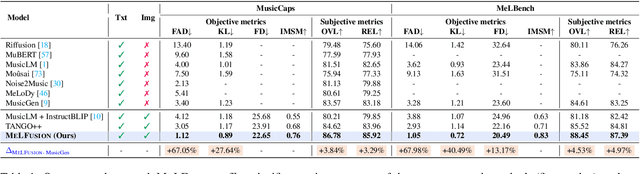
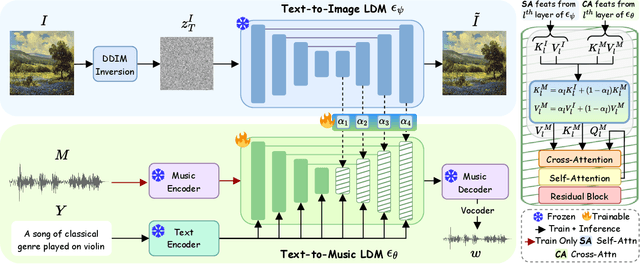
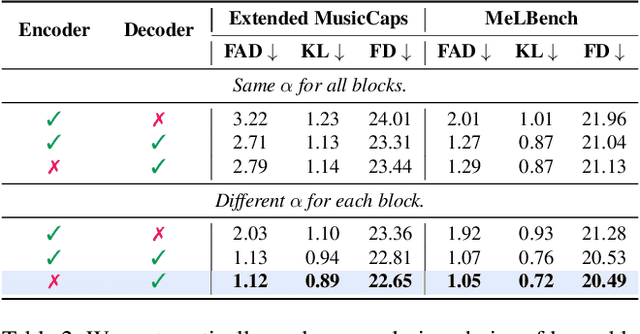
Music is a universal language that can communicate emotions and feelings. It forms an essential part of the whole spectrum of creative media, ranging from movies to social media posts. Machine learning models that can synthesize music are predominantly conditioned on textual descriptions of it. Inspired by how musicians compose music not just from a movie script, but also through visualizations, we propose MeLFusion, a model that can effectively use cues from a textual description and the corresponding image to synthesize music. MeLFusion is a text-to-music diffusion model with a novel "visual synapse", which effectively infuses the semantics from the visual modality into the generated music. To facilitate research in this area, we introduce a new dataset MeLBench, and propose a new evaluation metric IMSM. Our exhaustive experimental evaluation suggests that adding visual information to the music synthesis pipeline significantly improves the quality of generated music, measured both objectively and subjectively, with a relative gain of up to 67.98% on the FAD score. We hope that our work will gather attention to this pragmatic, yet relatively under-explored research area.