 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tutorial on ALOS2 SAR Utilization: Dataset Preparation, Self-Supervised Pretraining, and Semantic Segmentation
Mar 16, 2026Masked auto-encoders (MAE) and related approaches have shown promise for satellite imagery, but their application to synthetic aperture radar (SAR) remains limited due to challenges in semantic labeling and high noise levels. Building on our prior work with SAR-W-MixMAE, which adds SAR-specific intensity-weighted loss to standard MixMAE for pretraining, we also introduce SAR-W-SimMIM; a weighted variant of SimMIM applied to ALOS-2 single-channel SAR imagery. This method aims to reduce the impact of speckle and extreme intensity values during self-supervised pretraining. We evaluate its effect on semantic segmentation compared to our previous trial with SAR-W-MixMAE and random initialization, observing notable improvements. In addition, pretraining and fine-tuning models on satellite imagery pose unique challenges, particularly when developing region-specific models. Imbalanced land cover distributions such as dominant water, forest, or desert areas can introduce bias, affecting both pretraining and downstream tasks like land cover segmentation. To address this, we constructed a SAR dataset using ALOS-2 single-channel (HH polarization) imagery focused on the Japan region, marking the initial phase toward a national-scale foundation model. This dataset was used to pretrain a vision transformer-based autoencoder, with the resulting encoder fine-tuned for semantic segmentation using a task-specific decoder. Initial results demonstrate significant performance improvements compared to training from scratch with random initialization. In summary, this work provides a guide to process and prepare ALOS2 observations to create dataset so that it can be taken advantage of self-supervised pretraining of models and finetuning downstream tasks such as semantic segmentation.
Enhanced LULC Segmentation via Lightweight Model Refinements on ALOS-2 SAR Data
Jan 22, 2026This work focuses on national-scale land-use/land-cover (LULC) semantic segmentation using ALOS-2 single-polarization (HH) SAR data over Japan, together with a companion binary water detection task. Building on SAR-W-MixMAE self-supervised pretraining [1], we address common SAR dense-prediction failure modes, boundary over-smoothing, missed thin/slender structures, and rare-class degradation under long-tailed labels, without increasing pipeline complexity. We introduce three lightweight refinements: (i) injecting high-resolution features into multi-scale decoding, (ii) a progressive refine-up head that alternates convolutional refinement and stepwise upsampling, and (iii) an $α$-scale factor that tempers class reweighting within a focal+dice objective. The resulting model yields consistent improvements on the Japan-wide ALOS-2 LULC benchmark, particularly for under-represented classes, and improves water detection across standard evaluation metrics.
Exploring Object-Aware Attention Guided Frame Association for RGB-D SLAM
Oct 30, 2025Attention models have recently emerged as a powerful approach, demonstrating significant progress in various fields. Visualization techniques, such as class activation mapping, provide visual insights into the reasoning of convolutional neural networks (CNNs). Using network gradients, it is possible to identify regions where the network pays attention during image recognition tasks. Furthermore, these gradients can be combined with CNN features to localize more generalizable, task-specific attentive (salient) regions within scenes. However, explicit use of this gradient-based attention information integrated directly into CNN representations for semantic object understanding remains limited. Such integration is particularly beneficial for visual tasks like simultaneous localization and mapping (SLAM), where CNN representations enriched with spatially attentive object locations can enhance performance. In this work, we propose utilizing task-specific network attention for RGB-D indoor SLAM. Specifically, we integrate layer-wise attention information derived from network gradients with CNN feature representations to improve frame association performance. Experimental results indicate improved performance compared to baseline methods, particularly for large environments.
SAR-W-MixMAE: SAR Foundation Model Training Using Backscatter Power Weighting
Mar 04, 2025Foundation model approaches such as masked auto-encoders (MAE) or its variations are now being successfully applied to satellite imagery. Most of the ongoing technical validation of foundation models have been applied to optical images like RGB or multi-spectral images. Due to difficulty in semantic labeling to create datasets and higher noise content with respect to optical images, Synthetic Aperture Radar (SAR) data has not been explored a lot in the field for foundation models. Therefore, in this work as a pre-training approach, we explored masked auto-encoder, specifically MixMAE on Sentinel-1 SAR images and its impact on SAR image classification tasks. Moreover, we proposed to use the physical characteristic of SAR data for applying weighting parameter on the auto-encoder training loss (MSE) to reduce the effect of speckle noise and very high values on the SAR images. Proposed SAR intensity-based weighting of the reconstruction loss demonstrates promising results both on SAR pre-training and downstream tasks specifically on flood detection compared with the baseline model.
Attention-Guided Lidar Segmentation and Odometry Using Image-to-Point Cloud Saliency Transfer
Aug 28, 2023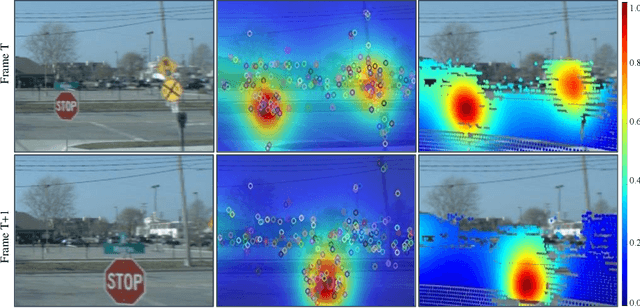

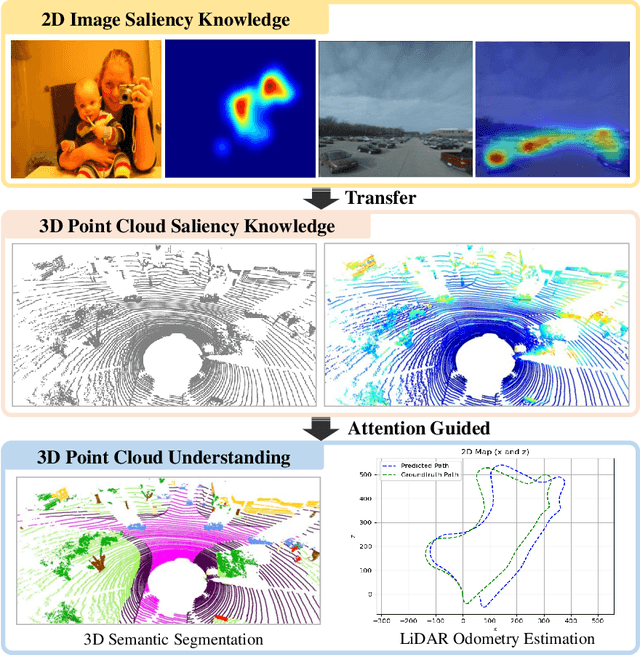
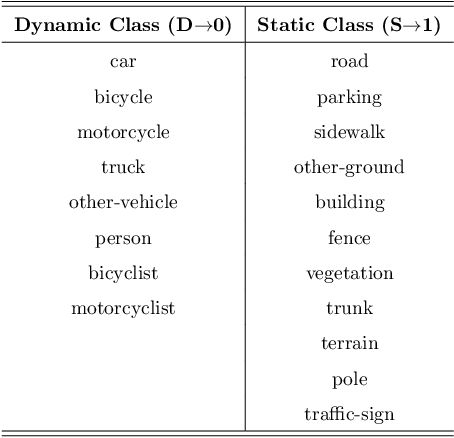
LiDAR odometry estimation and 3D semantic segmentation are crucial for autonomous driving, which has achieved remarkable advances recently. However, these tasks are challenging due to the imbalance of points in different semantic categories for 3D semantic segmentation and the influence of dynamic objects for LiDAR odometry estimation, which increases the importance of using representative/salient landmarks as reference points for robust feature learning. To address these challenges, we propose a saliency-guided approach that leverages attention information to improve the performance of LiDAR odometry estimation and semantic segmentation models. Unlike in the image domain, only a few studies have addressed point cloud saliency information due to the lack of annotated training data. To alleviate this, we first present a universal framework to transfer saliency distribution knowledge from color images to point clouds, and use this to construct a pseudo-saliency dataset (i.e. FordSaliency) for point clouds. Then, we adopt point cloud-based backbones to learn saliency distribution from pseudo-saliency labels, which is followed by our proposed SalLiDAR module. SalLiDAR is a saliency-guided 3D semantic segmentation model that integrates saliency information to improve segmentation performance. Finally, we introduce SalLONet, a self-supervised saliency-guided LiDAR odometry network that uses the semantic and saliency predictions of SalLiDAR to achieve better odometry estimation. Our extensive experiments on benchmark datasets demonstrate that the proposed SalLiDAR and SalLONet models achieve state-of-the-art performance against existing methods, highlighting the effectiveness of image-to-LiDAR saliency knowledge transfer. Source code will be available at https://github.com/nevrez/SalLONet.
RGB-D SLAM Using Attention Guided Frame Association
Jan 28, 2022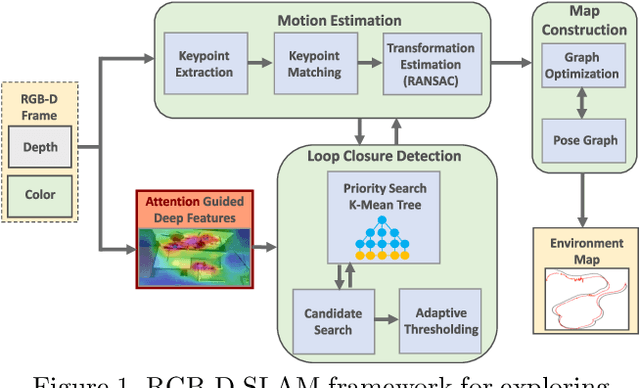
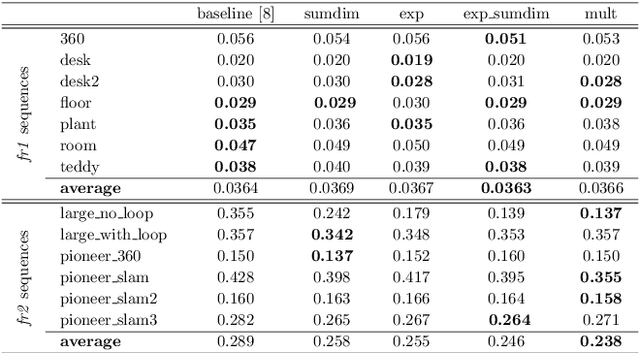
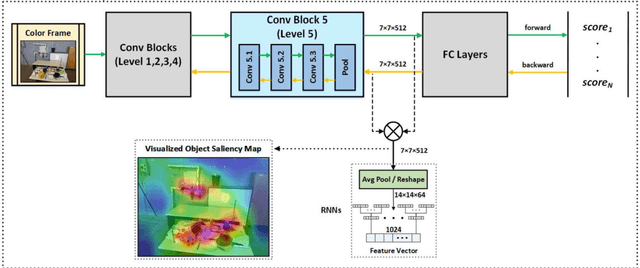
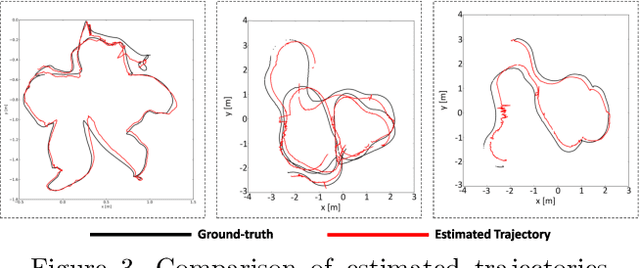
Deep learning models as an emerging topic have shown great progress in various fields. Especially, visualization tools such as class activation mapping methods provided visual explanation on the reasoning of convolutional neural networks (CNNs). By using the gradients of the network layers, it is possible to demonstrate where the networks pay attention during a specific image recognition task. Moreover, these gradients can be integrated with CNN features for localizing more generalized task dependent attentive (salient) objects in scenes. Despite this progress, there is not much explicit usage of this gradient (network attention) information to integrate with CNN representations for object semantics. This can be very useful for visual tasks such as simultaneous localization and mapping (SLAM) where CNN representations of spatially attentive object locations may lead to improved performance. Therefore, in this work, we propose the use of task specific network attention for RGB-D indoor SLAM. To do so, we integrate layer-wise object attention information (layer gradients) with CNN layer representations to improve frame association performance in a state-of-the-art RGB-D indoor SLAM method. Experiments show promising initial results with improved performance.
SalFBNet: Learning Pseudo-Saliency Distribution via Feedback Convolutional Networks
Jan 11, 2022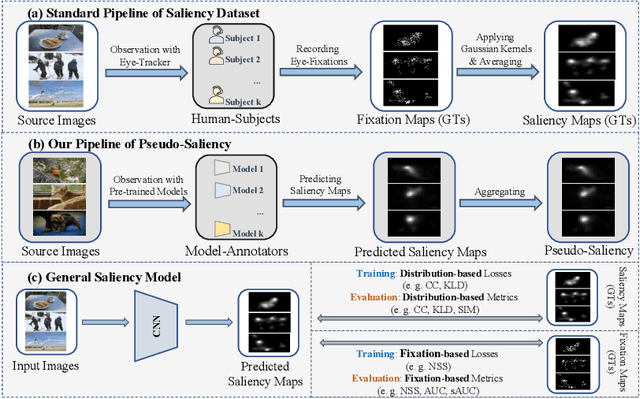
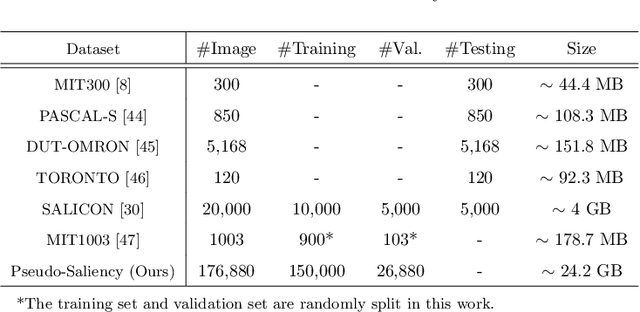
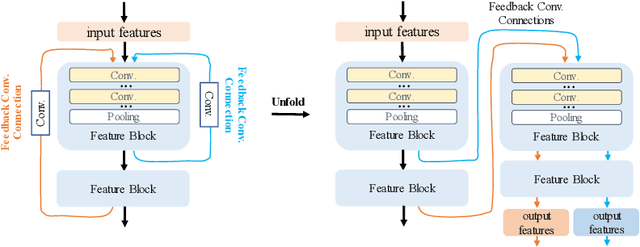
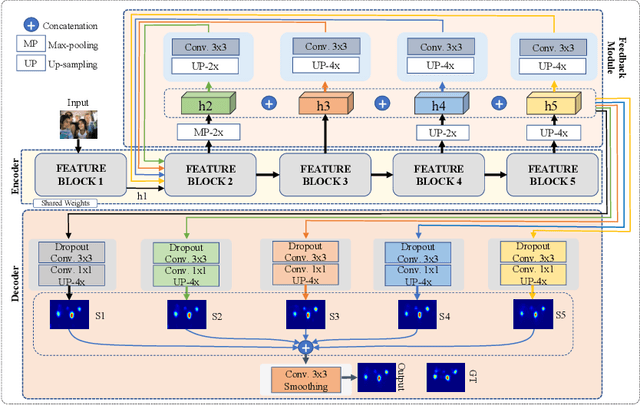
Feed-forward only convolutional neural networks (CNNs) may ignore intrinsic relationships and potential benefits of feedback connections in vision tasks such as saliency detection, despite their significant representation capabilities. In this work, we propose a feedback-recursive convolutional framework (SalFBNet) for saliency detection. The proposed feedback model can learn abundant contextual representations by bridging a recursive pathway from higher-level feature blocks to low-level layer. Moreover, we create a large-scale Pseudo-Saliency dataset to alleviate the problem of data deficiency in saliency detection. We first use the proposed feedback model to learn saliency distribution from pseudo-ground-truth. Afterwards, we fine-tune the feedback model on existing eye-fixation datasets. Furthermore, we present a novel Selective Fixation and Non-Fixation Error (sFNE) loss to make proposed feedback model better learn distinguishable eye-fixation-based features. Extensive experimental results show that our SalFBNet with fewer parameters achieves competitive results on the public saliency detection benchmarks, which demonstrate the effectiveness of proposed feedback model and Pseudo-Saliency data. Source codes and Pseudo-Saliency dataset can be found at https://github.com/gqding/SalFBNet
When CNNs Meet Random RNNs: Towards Multi-Level Analysis for RGB-D Object and Scene Recognition
Apr 26, 2020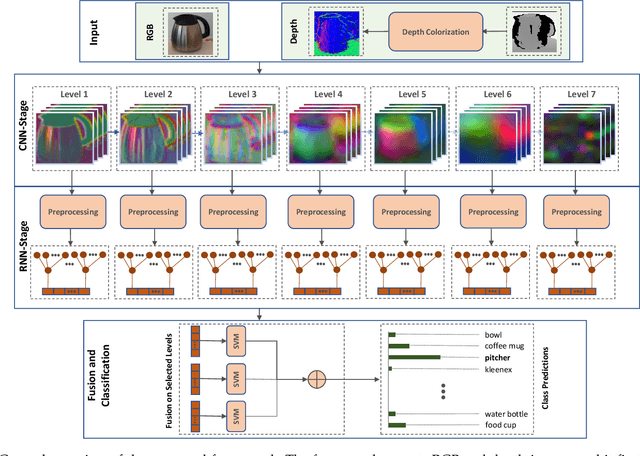

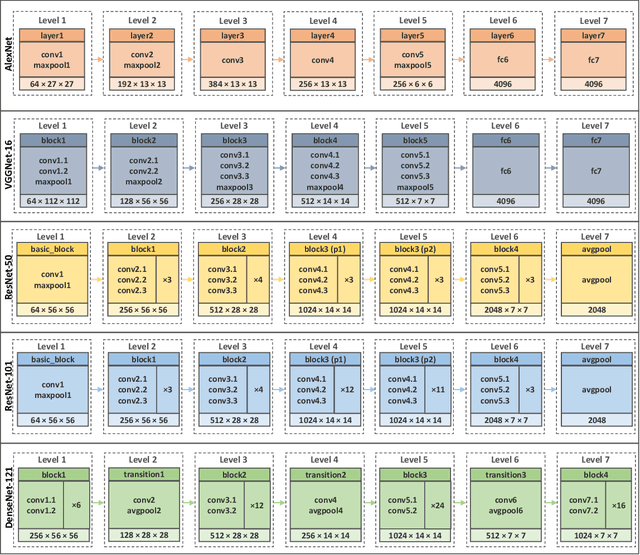
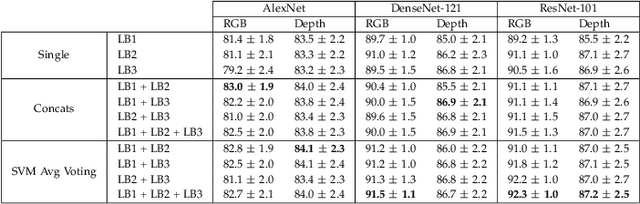
Recognizing objects and scenes are two challenging but essential tasks in image understanding. In particular, the use of RGB-D sensors in handling these tasks has emerged as an important area of focus for better visual understanding. Meanwhile, deep neural networks, specifically convolutional neural networks (CNNs), have become widespread and have been applied to many visual tasks by replacing hand-crafted features with effective deep features. However, it is an open problem how to exploit deep features from a multi-layer CNN model effectively. In this paper, we propose a novel two-stage framework that extracts discriminative feature representations from multi-modal RGB-D images for object and scene recognition tasks. In the first stage, a pretrained CNN model has been employed as a backbone to extract visual features at multiple levels. The second stage maps these features into high level representations with a fully randomized structure of recursive neural networks (RNNs) efficiently. In order to cope with the high dimensionality of CNN activations, a random weighted pooling scheme has been proposed by extending the idea of randomness in RNNs. Multi-modal fusion has been performed through a soft voting approach by computing weights based on individual recognition confidences (i.e. SVM scores) of RGB and depth streams separately. This produces consistent class label estimation in final RGB-D classification performance. Extensive experiments verify that fully randomized structure in RNN stage encodes CNN activations to discriminative solid features successfully. Comparative experimental results on the popular Washington RGB-D Object and SUN RGB-D Scene datasets show that the proposed approach significantly outperforms state-of-the-art methods both in object and scene recognition tasks.