 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen CNNs Meet Random RNNs: Towards Multi-Level Analysis for RGB-D Object and Scene Recognition
Paper and Code
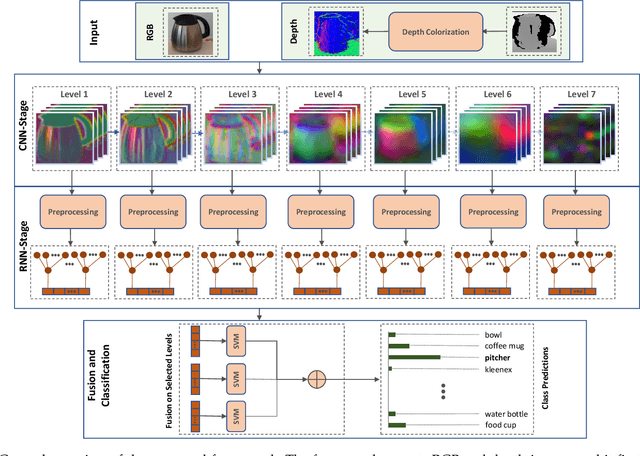

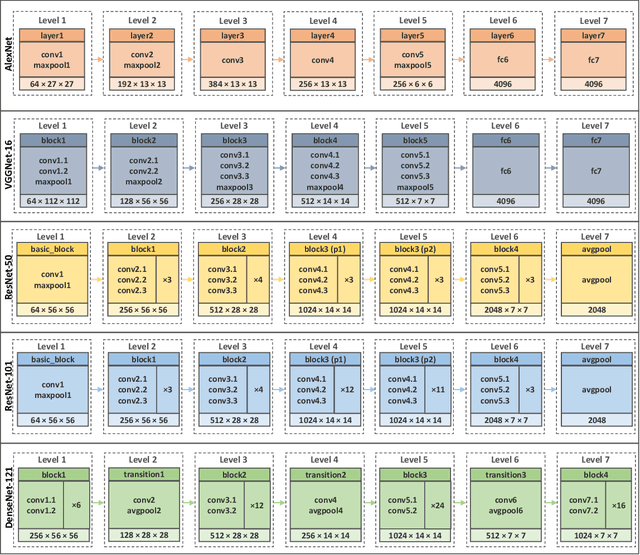
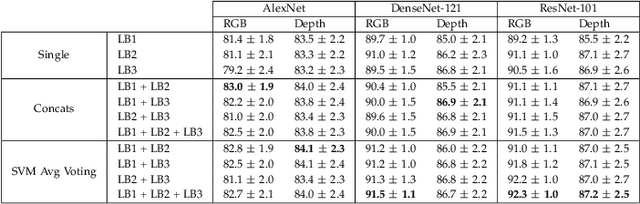
Recognizing objects and scenes are two challenging but essential tasks in image understanding. In particular, the use of RGB-D sensors in handling these tasks has emerged as an important area of focus for better visual understanding. Meanwhile, deep neural networks, specifically convolutional neural networks (CNNs), have become widespread and have been applied to many visual tasks by replacing hand-crafted features with effective deep features. However, it is an open problem how to exploit deep features from a multi-layer CNN model effectively. In this paper, we propose a novel two-stage framework that extracts discriminative feature representations from multi-modal RGB-D images for object and scene recognition tasks. In the first stage, a pretrained CNN model has been employed as a backbone to extract visual features at multiple levels. The second stage maps these features into high level representations with a fully randomized structure of recursive neural networks (RNNs) efficiently. In order to cope with the high dimensionality of CNN activations, a random weighted pooling scheme has been proposed by extending the idea of randomness in RNNs. Multi-modal fusion has been performed through a soft voting approach by computing weights based on individual recognition confidences (i.e. SVM scores) of RGB and depth streams separately. This produces consistent class label estimation in final RGB-D classification performance. Extensive experiments verify that fully randomized structure in RNN stage encodes CNN activations to discriminative solid features successfully. Comparative experimental results on the popular Washington RGB-D Object and SUN RGB-D Scene datasets show that the proposed approach significantly outperforms state-of-the-art methods both in object and scene recognition tasks.