 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Object-Aware Attention Guided Frame Association for RGB-D SLAM
Oct 30, 2025Attention models have recently emerged as a powerful approach, demonstrating significant progress in various fields. Visualization techniques, such as class activation mapping, provide visual insights into the reasoning of convolutional neural networks (CNNs). Using network gradients, it is possible to identify regions where the network pays attention during image recognition tasks. Furthermore, these gradients can be combined with CNN features to localize more generalizable, task-specific attentive (salient) regions within scenes. However, explicit use of this gradient-based attention information integrated directly into CNN representations for semantic object understanding remains limited. Such integration is particularly beneficial for visual tasks like simultaneous localization and mapping (SLAM), where CNN representations enriched with spatially attentive object locations can enhance performance. In this work, we propose utilizing task-specific network attention for RGB-D indoor SLAM. Specifically, we integrate layer-wise attention information derived from network gradients with CNN feature representations to improve frame association performance. Experimental results indicate improved performance compared to baseline methods, particularly for large environments.
RGB-D SLAM Using Attention Guided Frame Association
Jan 28, 2022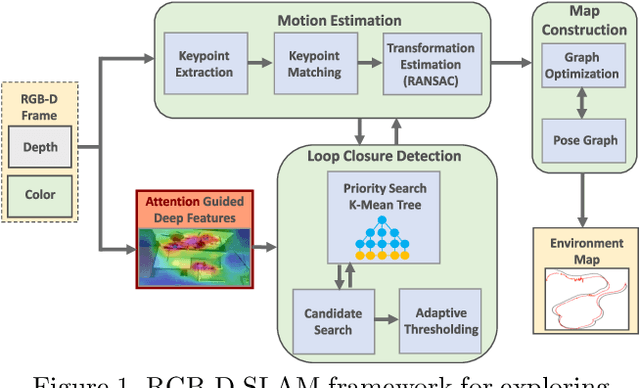
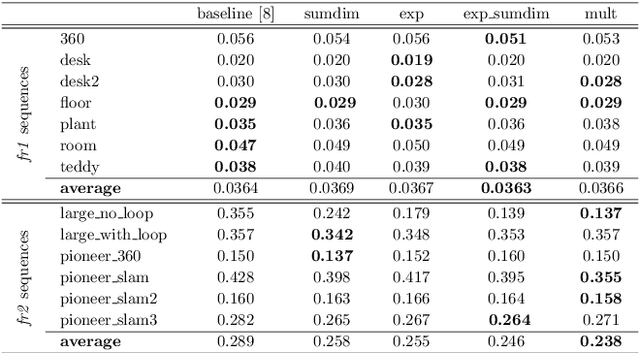
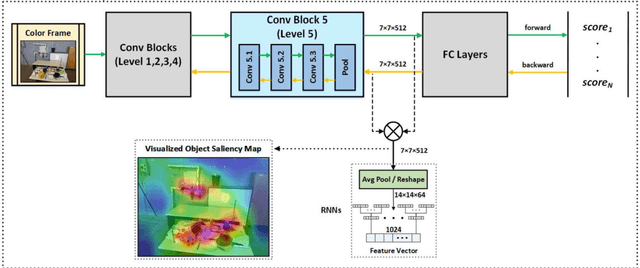
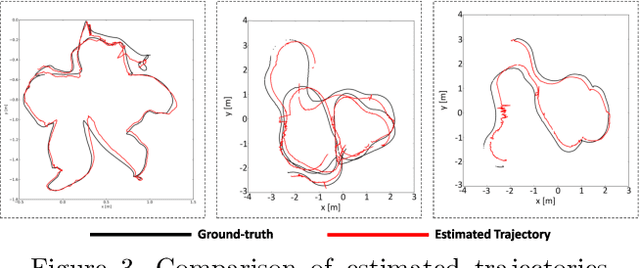
Deep learning models as an emerging topic have shown great progress in various fields. Especially, visualization tools such as class activation mapping methods provided visual explanation on the reasoning of convolutional neural networks (CNNs). By using the gradients of the network layers, it is possible to demonstrate where the networks pay attention during a specific image recognition task. Moreover, these gradients can be integrated with CNN features for localizing more generalized task dependent attentive (salient) objects in scenes. Despite this progress, there is not much explicit usage of this gradient (network attention) information to integrate with CNN representations for object semantics. This can be very useful for visual tasks such as simultaneous localization and mapping (SLAM) where CNN representations of spatially attentive object locations may lead to improved performance. Therefore, in this work, we propose the use of task specific network attention for RGB-D indoor SLAM. To do so, we integrate layer-wise object attention information (layer gradients) with CNN layer representations to improve frame association performance in a state-of-the-art RGB-D indoor SLAM method. Experiments show promising initial results with improved performance.
ADNet: Temporal Anomaly Detection in Surveillance Videos
Apr 14, 2021

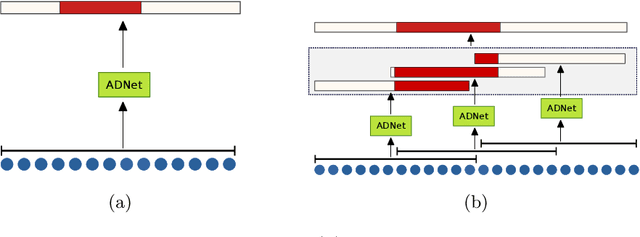
Anomaly detection in surveillance videos is an important research problem in computer vision. In this paper, we propose ADNet, an anomaly detection network, which utilizes temporal convolutions to localize anomalies in videos. The model works online by accepting consecutive windows consisting of fixed-number of video clips. Features extracted from video clips in a window are fed to ADNet, which allows to localize anomalies in videos effectively. We propose the AD Loss function to improve abnormal segment detection performance of ADNet. Additionally, we propose to use F1@k metric for temporal anomaly detection. F1@k is a better evaluation metric than AUC in terms of not penalizing minor shifts in temporal segments and punishing short false positive temporal segment predictions. Furthermore, we extend UCF Crime dataset by adding two more anomaly classes and providing temporal anomaly annotations for all classes. Finally, we thoroughly evaluate our model on the extended UCF Crime dataset. ADNet produces promising results with respect to F1@k metric. Dataset extensions and code will be publicly available upon publishing
When CNNs Meet Random RNNs: Towards Multi-Level Analysis for RGB-D Object and Scene Recognition
Apr 26, 2020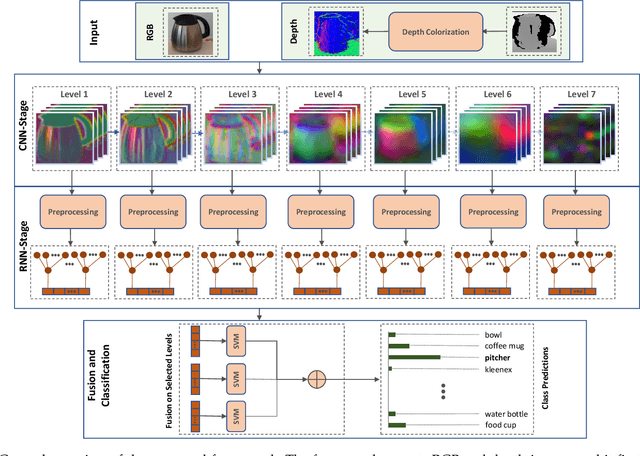

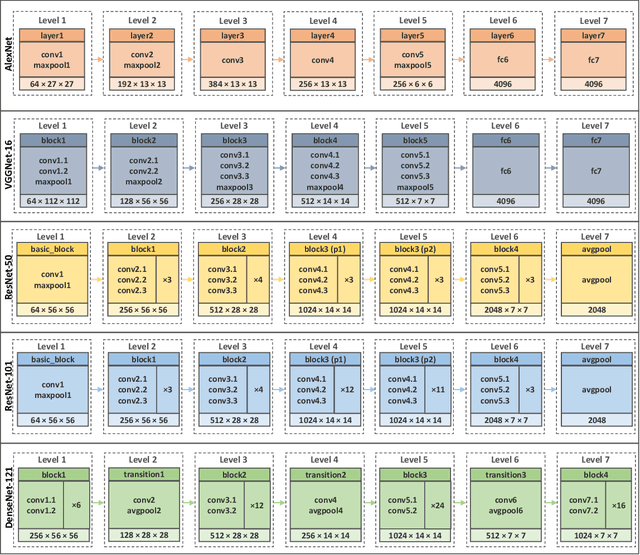
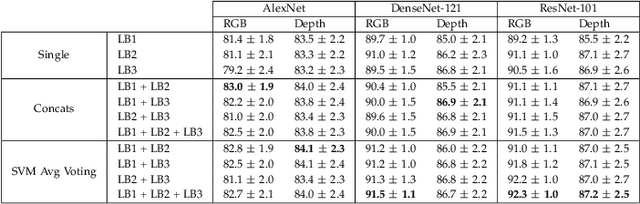
Recognizing objects and scenes are two challenging but essential tasks in image understanding. In particular, the use of RGB-D sensors in handling these tasks has emerged as an important area of focus for better visual understanding. Meanwhile, deep neural networks, specifically convolutional neural networks (CNNs), have become widespread and have been applied to many visual tasks by replacing hand-crafted features with effective deep features. However, it is an open problem how to exploit deep features from a multi-layer CNN model effectively. In this paper, we propose a novel two-stage framework that extracts discriminative feature representations from multi-modal RGB-D images for object and scene recognition tasks. In the first stage, a pretrained CNN model has been employed as a backbone to extract visual features at multiple levels. The second stage maps these features into high level representations with a fully randomized structure of recursive neural networks (RNNs) efficiently. In order to cope with the high dimensionality of CNN activations, a random weighted pooling scheme has been proposed by extending the idea of randomness in RNNs. Multi-modal fusion has been performed through a soft voting approach by computing weights based on individual recognition confidences (i.e. SVM scores) of RGB and depth streams separately. This produces consistent class label estimation in final RGB-D classification performance. Extensive experiments verify that fully randomized structure in RNN stage encodes CNN activations to discriminative solid features successfully. Comparative experimental results on the popular Washington RGB-D Object and SUN RGB-D Scene datasets show that the proposed approach significantly outperforms state-of-the-art methods both in object and scene recognition tasks.