 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-Guided Lidar Segmentation and Odometry Using Image-to-Point Cloud Saliency Transfer
Aug 28, 2023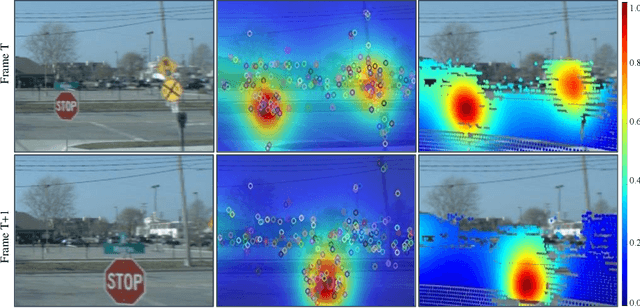

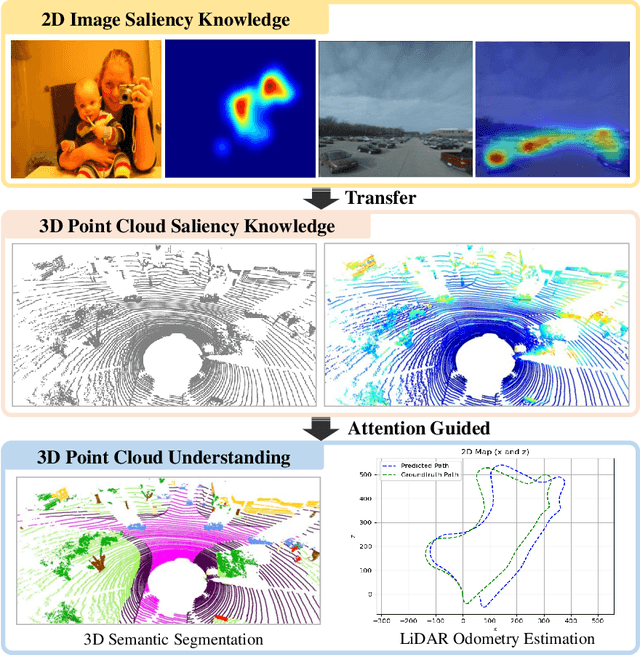
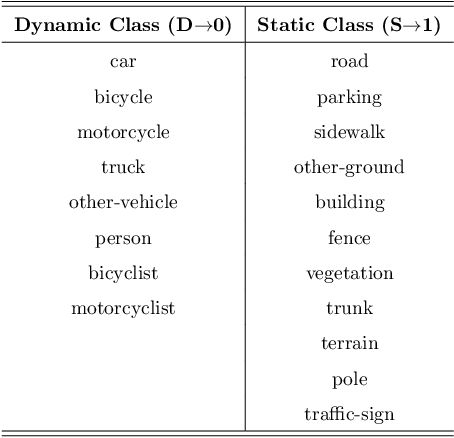
LiDAR odometry estimation and 3D semantic segmentation are crucial for autonomous driving, which has achieved remarkable advances recently. However, these tasks are challenging due to the imbalance of points in different semantic categories for 3D semantic segmentation and the influence of dynamic objects for LiDAR odometry estimation, which increases the importance of using representative/salient landmarks as reference points for robust feature learning. To address these challenges, we propose a saliency-guided approach that leverages attention information to improve the performance of LiDAR odometry estimation and semantic segmentation models. Unlike in the image domain, only a few studies have addressed point cloud saliency information due to the lack of annotated training data. To alleviate this, we first present a universal framework to transfer saliency distribution knowledge from color images to point clouds, and use this to construct a pseudo-saliency dataset (i.e. FordSaliency) for point clouds. Then, we adopt point cloud-based backbones to learn saliency distribution from pseudo-saliency labels, which is followed by our proposed SalLiDAR module. SalLiDAR is a saliency-guided 3D semantic segmentation model that integrates saliency information to improve segmentation performance. Finally, we introduce SalLONet, a self-supervised saliency-guided LiDAR odometry network that uses the semantic and saliency predictions of SalLiDAR to achieve better odometry estimation. Our extensive experiments on benchmark datasets demonstrate that the proposed SalLiDAR and SalLONet models achieve state-of-the-art performance against existing methods, highlighting the effectiveness of image-to-LiDAR saliency knowledge transfer. Source code will be available at https://github.com/nevrez/SalLONet.
SalFBNet: Learning Pseudo-Saliency Distribution via Feedback Convolutional Networks
Jan 11, 2022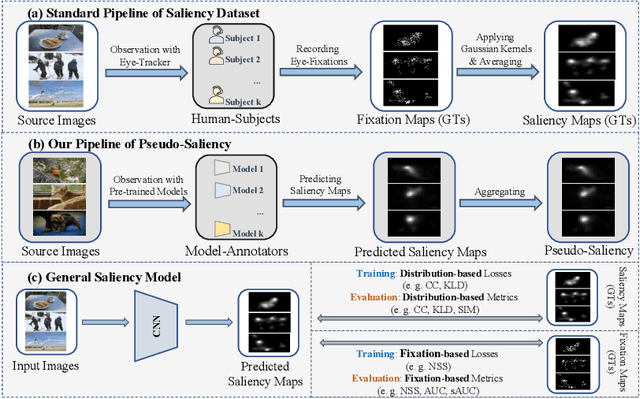
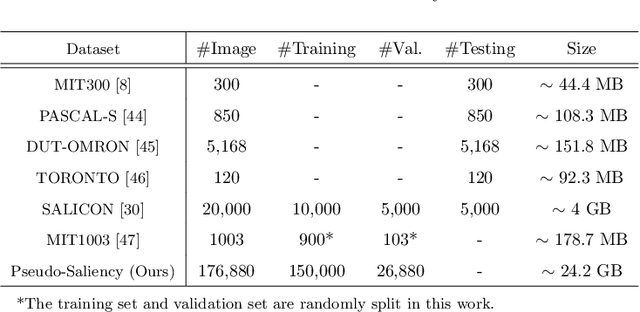
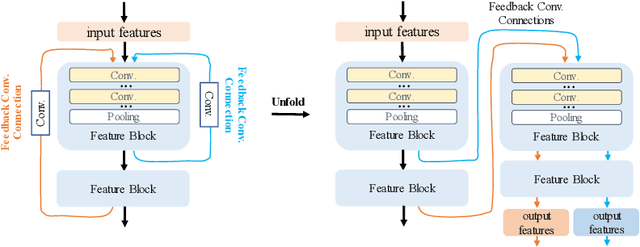
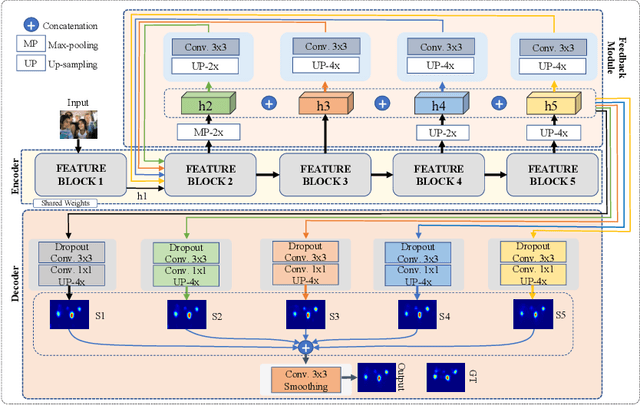
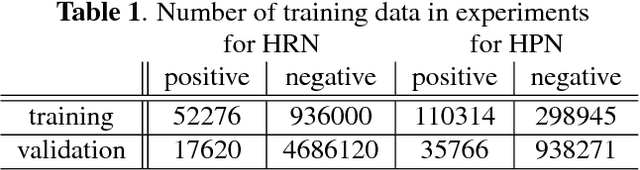
Feed-forward only convolutional neural networks (CNNs) may ignore intrinsic relationships and potential benefits of feedback connections in vision tasks such as saliency detection, despite their significant representation capabilities. In this work, we propose a feedback-recursive convolutional framework (SalFBNet) for saliency detection. The proposed feedback model can learn abundant contextual representations by bridging a recursive pathway from higher-level feature blocks to low-level layer. Moreover, we create a large-scale Pseudo-Saliency dataset to alleviate the problem of data deficiency in saliency detection. We first use the proposed feedback model to learn saliency distribution from pseudo-ground-truth. Afterwards, we fine-tune the feedback model on existing eye-fixation datasets. Furthermore, we present a novel Selective Fixation and Non-Fixation Error (sFNE) loss to make proposed feedback model better learn distinguishable eye-fixation-based features. Extensive experimental results show that our SalFBNet with fewer parameters achieves competitive results on the public saliency detection benchmarks, which demonstrate the effectiveness of proposed feedback model and Pseudo-Saliency data. Source codes and Pseudo-Saliency dataset can be found at https://github.com/gqding/SalFBNet
Object Detection in Satellite Imagery using 2-Step Convolutional Neural Networks
Aug 09, 2018
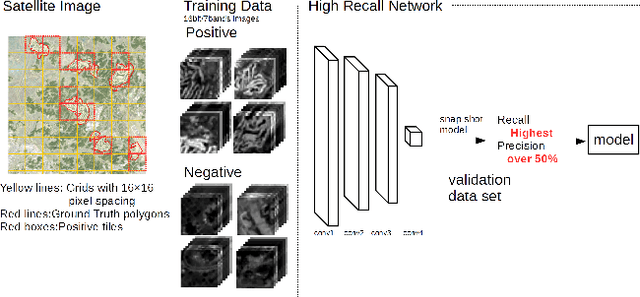
This paper presents an efficient object detection method from satellite imagery. Among a number of machine learning algorithms, we proposed a combination of two convolutional neural networks (CNN) aimed at high precision and high recall, respectively. We validated our models using golf courses as target objects. The proposed deep learning method demonstrated higher accuracy than previous object identification methods.
Object Detection of Satellite Images Using Multi-Channel Higher-order Local Autocorrelation
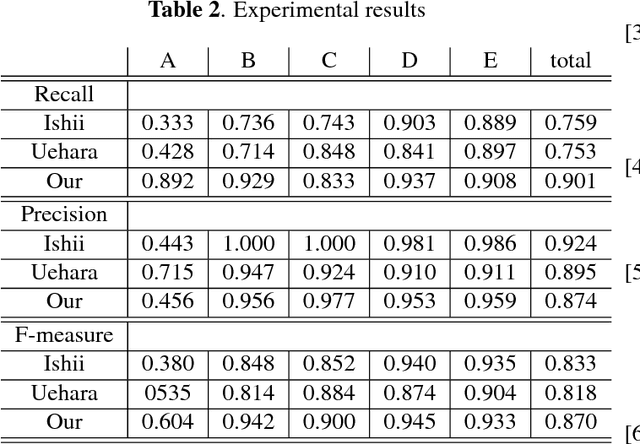
Jul 28, 2017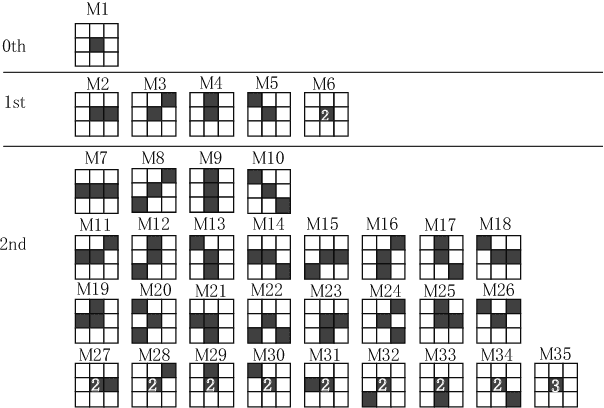
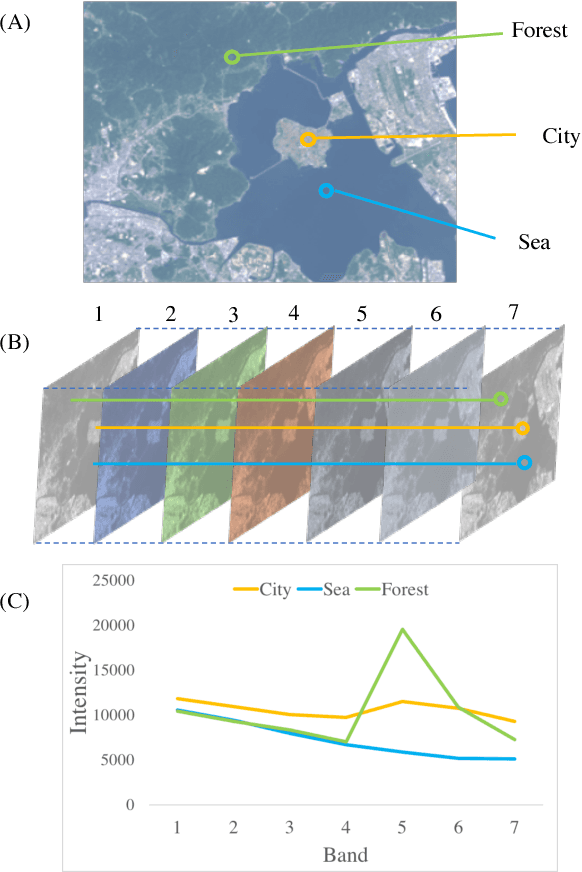
The Earth observation satellites have been monitoring the earth's surface for a long time, and the images taken by the satellites contain large amounts of valuable data. However, it is extremely hard work to manually analyze such huge data. Thus, a method of automatic object detection is needed for satellite images to facilitate efficient data analyses. This paper describes a new image feature extended from higher-order local autocorrelation to the object detection of multispectral satellite images. The feature has been extended to extract spectral inter-relationships in addition to spatial relationships to fully exploit multispectral information. The results of experiments with object detection tasks conducted to evaluate the effectiveness of the proposed feature extension indicate that the feature realized a higher performance compared to existing methods.