 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-Augmented Layout Transformer for Content-Aware Layout Generation
Nov 22, 2023
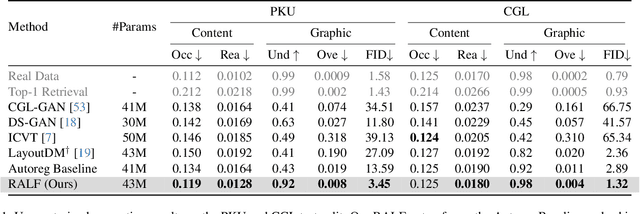

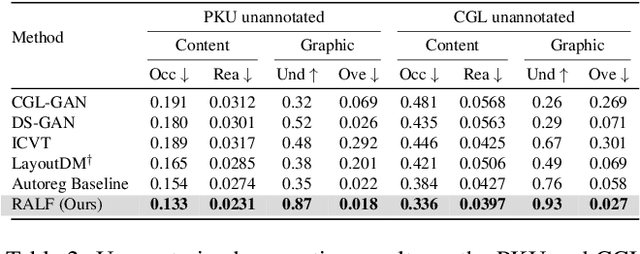
Content-aware graphic layout generation aims to automatically arrange visual elements along with a given content, such as an e-commerce product image. In this paper, we argue that the current layout generation approaches suffer from the limited training data for the high-dimensional layout structure. We show that a simple retrieval augmentation can significantly improve the generation quality. Our model, which is named Retrieval-Augmented Layout Transformer (RALF), retrieves nearest neighbor layout examples based on an input image and feeds these results into an autoregressive generator. Our model can apply retrieval augmentation to various controllable generation tasks and yield high-quality layouts within a unified architecture. Our extensive experiments show that RALF successfully generates content-aware layouts in both constrained and unconstrained settings and significantly outperforms the baselines.
Memory Efficient Diffusion Probabilistic Models via Patch-based Generation
Apr 14, 2023Diffusion probabilistic models have been successful in generating high-quality and diverse images. However, traditional models, whose input and output are high-resolution images, suffer from excessive memory requirements, making them less practical for edge devices. Previous approaches for generative adversarial networks proposed a patch-based method that uses positional encoding and global content information. Nevertheless, designing a patch-based approach for diffusion probabilistic models is non-trivial. In this paper, we resent a diffusion probabilistic model that generates images on a patch-by-patch basis. We propose two conditioning methods for a patch-based generation. First, we propose position-wise conditioning using one-hot representation to ensure patches are in proper positions. Second, we propose Global Content Conditioning (GCC) to ensure patches have coherent content when concatenated together. We evaluate our model qualitatively and quantitatively on CelebA and LSUN bedroom datasets and demonstrate a moderate trade-off between maximum memory consumption and generated image quality. Specifically, when an entire image is divided into 2 x 2 patches, our proposed approach can reduce the maximum memory consumption by half while maintaining comparable image quality.
A Structure-Guided Diffusion Model for Large-Hole Diverse Image Completion
Nov 18, 2022

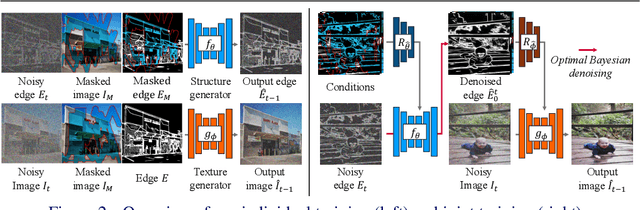

Diverse image completion, a problem of generating various ways of filling incomplete regions (i.e. holes) of an image, has made remarkable success. However, managing input images with large holes is still a challenging problem due to the corruption of semantically important structures. In this paper, we tackle this problem by incorporating explicit structural guidance. We propose a structure-guided diffusion model (SGDM) for the large-hole diverse completion problem. Our proposed SGDM consists of a structure generator and a texture generator, which are both diffusion probabilistic models (DMs). The structure generator generates an edge image representing a plausible structure within the holes, which is later used to guide the texture generation process. To jointly train these two generators, we design a strategy that combines optimal Bayesian denoising and a momentum framework. In addition to the quality improvement, auxiliary edge images generated by the structure generator can be manually edited to allow user-guided image editing. Our experiments using datasets of faces (CelebA-HQ) and natural scenes (Places) show that our method achieves a comparable or superior trade-off between visual quality and diversity compared to other state-of-the-art methods.
SLGAN: Style- and Latent-guided Generative Adversarial Network for Desirable Makeup Transfer and Removal
Sep 24, 2020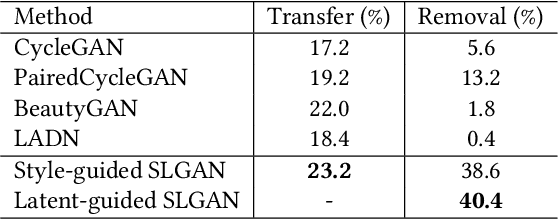
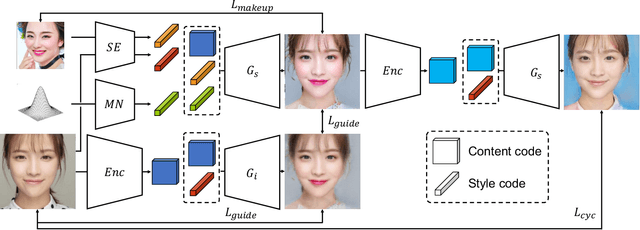


There are five features to consider when using generative adversarial networks to apply makeup to photos of the human face. These features include (1) facial components, (2) interactive color adjustments, (3) makeup variations, (4) robustness to poses and expressions, and the (5) use of multiple reference images. Several related works have been proposed, mainly using generative adversarial networks (GAN). Unfortunately, none of them have addressed all five features simultaneously. This paper closes the gap with an innovative style- and latent-guided GAN (SLGAN). We provide a novel, perceptual makeup loss and a style-invariant decoder that can transfer makeup styles based on histogram matching to avoid the identity-shift problem. In our experiments, we show that our SLGAN is better than or comparable to state-of-the-art methods. Furthermore, we show that our proposal can interpolate facial makeup images to determine the unique features, compare existing methods, and help users find desirable makeup configurations.