 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColorGPT: Leveraging Large Language Models for Multimodal Color Recommendation
Aug 12, 2025Colors play a crucial role in the design of vector graphic documents by enhancing visual appeal, facilitating communication, improving usability, and ensuring accessibility. In this context, color recommendation involves suggesting appropriate colors to complete or refine a design when one or more colors are missing or require alteration. Traditional methods often struggled with these challenges due to the complex nature of color design and the limited data availability. In this study, we explored the use of pretrained Large Language Models (LLMs) and their commonsense reasoning capabilities for color recommendation, raising the question: Can pretrained LLMs serve as superior designers for color recommendation tasks? To investigate this, we developed a robust, rigorously validated pipeline, ColorGPT, that was built by systematically testing multiple color representations and applying effective prompt engineering techniques. Our approach primarily targeted color palette completion by recommending colors based on a set of given colors and accompanying context. Moreover, our method can be extended to full palette generation, producing an entire color palette corresponding to a provided textual description. Experimental results demonstrated that our LLM-based pipeline outperformed existing methods in terms of color suggestion accuracy and the distribution of colors in the color palette completion task. For the full palette generation task, our approach also yielded improvements in color diversity and similarity compared to current techniques.
Multimodal Markup Document Models for Graphic Design Completion
Sep 27, 2024



This paper presents multimodal markup document models (MarkupDM) that can generate both markup language and images within interleaved multimodal documents. Unlike existing vision-and-language multimodal models, our MarkupDM tackles unique challenges critical to graphic design tasks: generating partial images that contribute to the overall appearance, often involving transparency and varying sizes, and understanding the syntax and semantics of markup languages, which play a fundamental role as a representational format of graphic designs. To address these challenges, we design an image quantizer to tokenize images of diverse sizes with transparency and modify a code language model to process markup languages and incorporate image modalities. We provide in-depth evaluations of our approach on three graphic design completion tasks: generating missing attribute values, images, and texts in graphic design templates. Results corroborate the effectiveness of our MarkupDM for graphic design tasks. We also discuss the strengths and weaknesses in detail, providing insights for future research on multimodal document generation.
Fast Sprite Decomposition from Animated Graphics
Aug 07, 2024



This paper presents an approach to decomposing animated graphics into sprites, a set of basic elements or layers. Our approach builds on the optimization of sprite parameters to fit the raster video. For efficiency, we assume static textures for sprites to reduce the search space while preventing artifacts using a texture prior model. To further speed up the optimization, we introduce the initialization of the sprite parameters utilizing a pre-trained video object segmentation model and user input of single frame annotations. For our study, we construct the Crello Animation dataset from an online design service and define quantitative metrics to measure the quality of the extracted sprites. Experiments show that our method significantly outperforms baselines for similar decomposition tasks in terms of the quality/efficiency tradeoff.
LTSim: Layout Transportation-based Similarity Measure for Evaluating Layout Generation
Jul 17, 2024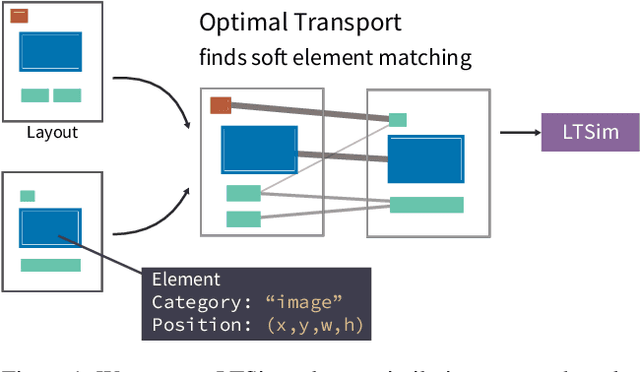

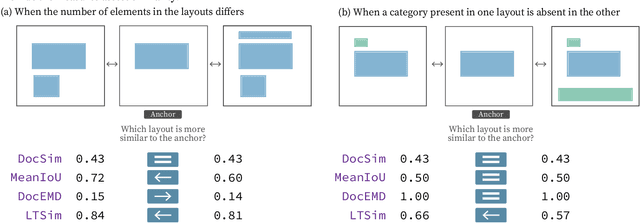
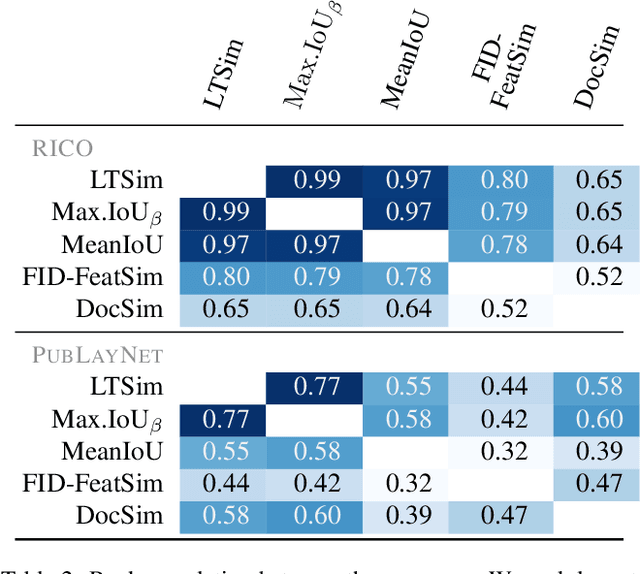
We introduce a layout similarity measure designed to evaluate the results of layout generation. While several similarity measures have been proposed in prior research, there has been a lack of comprehensive discussion about their behaviors. Our research uncovers that the majority of these measures are unable to handle various layout differences, primarily due to their dependencies on strict element matching, that is one-by-one matching of elements within the same category. To overcome this limitation, we propose a new similarity measure based on optimal transport, which facilitates a more flexible matching of elements. This approach allows us to quantify the similarity between any two layouts even those sharing no element categories, making our measure highly applicable to a wide range of layout generation tasks. For tasks such as unconditional layout generation, where FID is commonly used, we also extend our measure to deal with collection-level similarities between groups of layouts. The empirical result suggests that our collection-level measure offers more reliable comparisons than existing ones like FID and Max.IoU.
Retrieval-Augmented Layout Transformer for Content-Aware Layout Generation
Nov 22, 2023
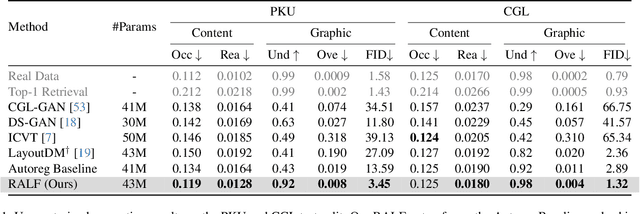

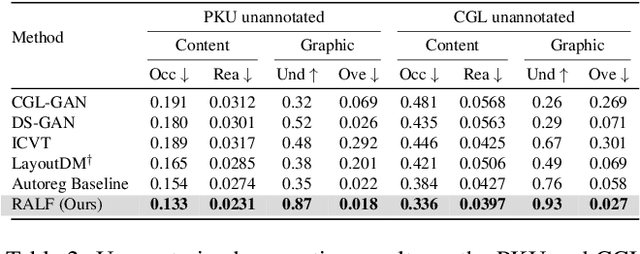
Content-aware graphic layout generation aims to automatically arrange visual elements along with a given content, such as an e-commerce product image. In this paper, we argue that the current layout generation approaches suffer from the limited training data for the high-dimensional layout structure. We show that a simple retrieval augmentation can significantly improve the generation quality. Our model, which is named Retrieval-Augmented Layout Transformer (RALF), retrieves nearest neighbor layout examples based on an input image and feeds these results into an autoregressive generator. Our model can apply retrieval augmentation to various controllable generation tasks and yield high-quality layouts within a unified architecture. Our extensive experiments show that RALF successfully generates content-aware layouts in both constrained and unconstrained settings and significantly outperforms the baselines.
Towards Flexible Multi-modal Document Models
Mar 31, 2023Creative workflows for generating graphical documents involve complex inter-related tasks, such as aligning elements, choosing appropriate fonts, or employing aesthetically harmonious colors. In this work, we attempt at building a holistic model that can jointly solve many different design tasks. Our model, which we denote by FlexDM, treats vector graphic documents as a set of multi-modal elements, and learns to predict masked fields such as element type, position, styling attributes, image, or text, using a unified architecture. Through the use of explicit multi-task learning and in-domain pre-training, our model can better capture the multi-modal relationships among the different document fields. Experimental results corroborate that our single FlexDM is able to successfully solve a multitude of different design tasks, while achieving performance that is competitive with task-specific and costly baselines.
LayoutDM: Discrete Diffusion Model for Controllable Layout Generation
Mar 14, 2023



Controllable layout generation aims at synthesizing plausible arrangement of element bounding boxes with optional constraints, such as type or position of a specific element. In this work, we try to solve a broad range of layout generation tasks in a single model that is based on discrete state-space diffusion models. Our model, named LayoutDM, naturally handles the structured layout data in the discrete representation and learns to progressively infer a noiseless layout from the initial input, where we model the layout corruption process by modality-wise discrete diffusion. For conditional generation, we propose to inject layout constraints in the form of masking or logit adjustment during inference. We show in the experiments that our LayoutDM successfully generates high-quality layouts and outperforms both task-specific and task-agnostic baselines on several layout tasks.
Generative Colorization of Structured Mobile Web Pages
Dec 22, 2022



Color is a critical design factor for web pages, affecting important factors such as viewer emotions and the overall trust and satisfaction of a website. Effective coloring requires design knowledge and expertise, but if this process could be automated through data-driven modeling, efficient exploration and alternative workflows would be possible. However, this direction remains underexplored due to the lack of a formalization of the web page colorization problem, datasets, and evaluation protocols. In this work, we propose a new dataset consisting of e-commerce mobile web pages in a tractable format, which are created by simplifying the pages and extracting canonical color styles with a common web browser. The web page colorization problem is then formalized as a task of estimating plausible color styles for a given web page content with a given hierarchical structure of the elements. We present several Transformer-based methods that are adapted to this task by prepending structural message passing to capture hierarchical relationships between elements. Experimental results, including a quantitative evaluation designed for this task, demonstrate the advantages of our methods over statistical and image colorization methods. The code is available at https://github.com/CyberAgentAILab/webcolor.
Constrained Graphic Layout Generation via Latent Optimization
Aug 02, 2021
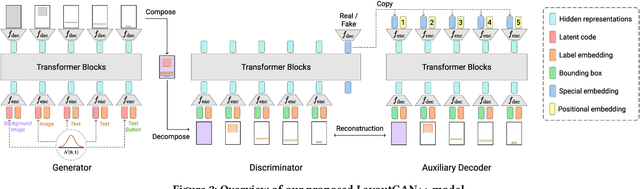


It is common in graphic design humans visually arrange various elements according to their design intent and semantics. For example, a title text almost always appears on top of other elements in a document. In this work, we generate graphic layouts that can flexibly incorporate such design semantics, either specified implicitly or explicitly by a user. We optimize using the latent space of an off-the-shelf layout generation model, allowing our approach to be complementary to and used with existing layout generation models. Our approach builds on a generative layout model based on a Transformer architecture, and formulates the layout generation as a constrained optimization problem where design constraints are used for element alignment, overlap avoidance, or any other user-specified relationship. We show in the experiments that our approach is capable of generating realistic layouts in both constrained and unconstrained generation tasks with a single model. The code is available at https://github.com/ktrk115/const_layout .