 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Robust Incomplete Multimodal Sentiment Analysis via Hierarchical Representation Learning
Nov 05, 2024



Multimodal Sentiment Analysis (MSA) is an important research area that aims to understand and recognize human sentiment through multiple modalities. The complementary information provided by multimodal fusion promotes better sentiment analysis compared to utilizing only a single modality. Nevertheless, in real-world applications, many unavoidable factors may lead to situations of uncertain modality missing, thus hindering the effectiveness of multimodal modeling and degrading the model's performance. To this end, we propose a Hierarchical Representation Learning Framework (HRLF) for the MSA task under uncertain missing modalities. Specifically, we propose a fine-grained representation factorization module that sufficiently extracts valuable sentiment information by factorizing modality into sentiment-relevant and modality-specific representations through crossmodal translation and sentiment semantic reconstruction. Moreover, a hierarchical mutual information maximization mechanism is introduced to incrementally maximize the mutual information between multi-scale representations to align and reconstruct the high-level semantics in the representations. Ultimately, we propose a hierarchical adversarial learning mechanism that further aligns and adapts the latent distribution of sentiment-relevant representations to produce robust joint multimodal representations. Comprehensive experiments on three datasets demonstrate that HRLF significantly improves MSA performance under uncertain modality missing cases.
Faster Diffusion Action Segmentation
Aug 04, 2024
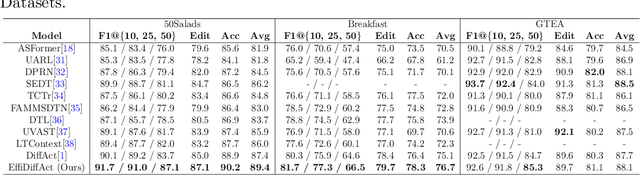
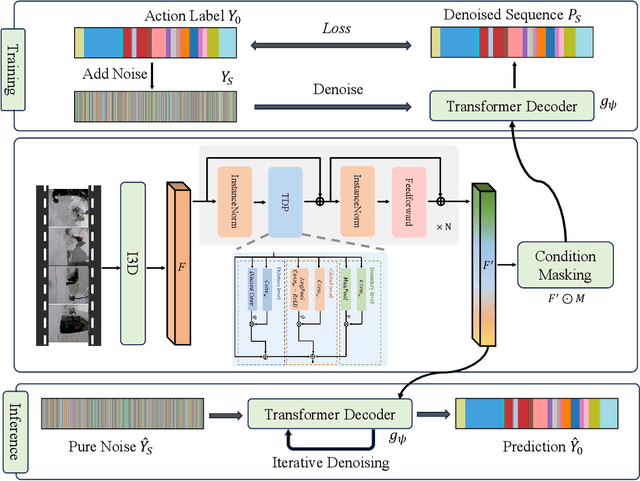

Temporal Action Segmentation (TAS) is an essential task in video analysis, aiming to segment and classify continuous frames into distinct action segments. However, the ambiguous boundaries between actions pose a significant challenge for high-precision segmentation. Recent advances in diffusion models have demonstrated substantial success in TAS tasks due to their stable training process and high-quality generation capabilities. However, the heavy sampling steps required by diffusion models pose a substantial computational burden, limiting their practicality in real-time applications. Additionally, most related works utilize Transformer-based encoder architectures. Although these architectures excel at capturing long-range dependencies, they incur high computational costs and face feature-smoothing issues when processing long video sequences. To address these challenges, we propose EffiDiffAct, an efficient and high-performance TAS algorithm. Specifically, we develop a lightweight temporal feature encoder that reduces computational overhead and mitigates the rank collapse phenomenon associated with traditional self-attention mechanisms. Furthermore, we introduce an adaptive skip strategy that allows for dynamic adjustment of timestep lengths based on computed similarity metrics during inference, thereby further enhancing computational efficiency. Comprehensive experiments on the 50Salads, Breakfast, and GTEA datasets demonstrated the effectiveness of the proposed algorithm.
PediatricsGPT: Large Language Models as Chinese Medical Assistants for Pediatric Applications
May 29, 2024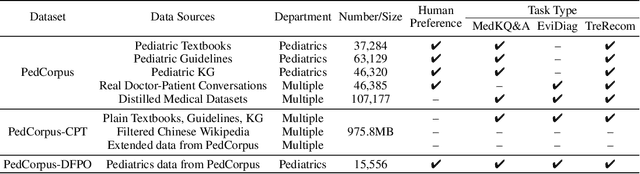
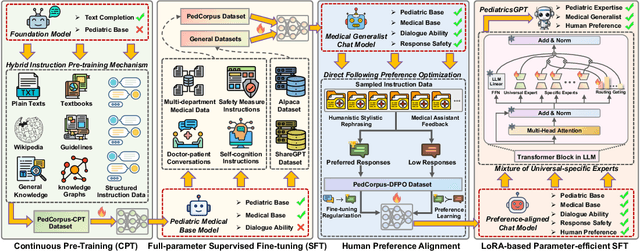
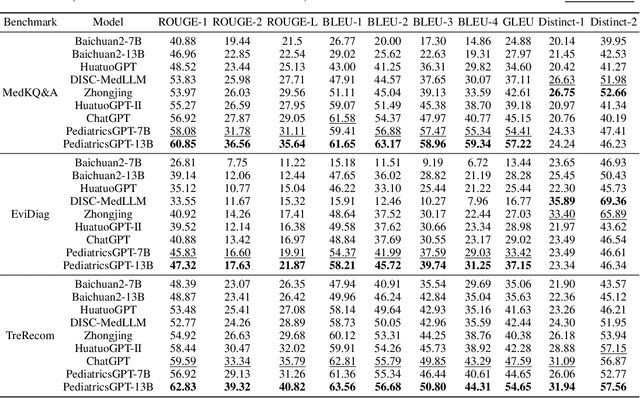
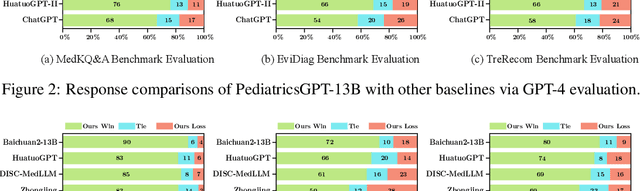
Developing intelligent pediatric consultation systems offers promising prospects for improving diagnostic efficiency, especially in China, where healthcare resources are scarce. Despite recent advances in Large Language Models (LLMs) for Chinese medicine, their performance is sub-optimal in pediatric applications due to inadequate instruction data and vulnerable training procedures. To address the above issues, this paper builds PedCorpus, a high-quality dataset of over 300,000 multi-task instructions from pediatric textbooks, guidelines, and knowledge graph resources to fulfil diverse diagnostic demands. Upon well-designed PedCorpus, we propose PediatricsGPT, the first Chinese pediatric LLM assistant built on a systematic and robust training pipeline. In the continuous pre-training phase, we introduce a hybrid instruction pre-training mechanism to mitigate the internal-injected knowledge inconsistency of LLMs for medical domain adaptation. Immediately, the full-parameter Supervised Fine-Tuning (SFT) is utilized to incorporate the general medical knowledge schema into the models. After that, we devise a direct following preference optimization to enhance the generation of pediatrician-like humanistic responses. In the parameter-efficient secondary SFT phase, a mixture of universal-specific experts strategy is presented to resolve the competency conflict between medical generalist and pediatric expertise mastery. Extensive results based on the metrics, GPT-4, and doctor evaluations on distinct doctor downstream tasks show that PediatricsGPT consistently outperforms previous Chinese medical LLMs. Our model and dataset will be open-source for community development.
SMCD: High Realism Motion Style Transfer via Mamba-based Diffusion
May 05, 2024



Motion style transfer is a significant research direction in multimedia applications. It enables the rapid switching of different styles of the same motion for virtual digital humans, thus vastly increasing the diversity and realism of movements. It is widely applied in multimedia scenarios such as movies, games, and the Metaverse. However, most of the current work in this field adopts the GAN, which may lead to instability and convergence issues, making the final generated motion sequence somewhat chaotic and unable to reflect a highly realistic and natural style. To address these problems, we consider style motion as a condition and propose the Style Motion Conditioned Diffusion (SMCD) framework for the first time, which can more comprehensively learn the style features of motion. Moreover, we apply Mamba model for the first time in the motion style transfer field, introducing the Motion Style Mamba (MSM) module to handle longer motion sequences. Thirdly, aiming at the SMCD framework, we propose Diffusion-based Content Consistency Loss and Content Consistency Loss to assist the overall framework's training. Finally, we conduct extensive experiments. The results reveal that our method surpasses state-of-the-art methods in both qualitative and quantitative comparisons, capable of generating more realistic motion sequences.
Correlation-Decoupled Knowledge Distillation for Multimodal Sentiment Analysis with Incomplete Modalities
Apr 25, 2024



Multimodal sentiment analysis (MSA) aims to understand human sentiment through multimodal data. Most MSA efforts are based on the assumption of modality completeness. However, in real-world applications, some practical factors cause uncertain modality missingness, which drastically degrades the model's performance. To this end, we propose a Correlation-decoupled Knowledge Distillation (CorrKD) framework for the MSA task under uncertain missing modalities. Specifically, we present a sample-level contrastive distillation mechanism that transfers comprehensive knowledge containing cross-sample correlations to reconstruct missing semantics. Moreover, a category-guided prototype distillation mechanism is introduced to capture cross-category correlations using category prototypes to align feature distributions and generate favorable joint representations. Eventually, we design a response-disentangled consistency distillation strategy to optimize the sentiment decision boundaries of the student network through response disentanglement and mutual information maximization. Comprehensive experiments on three datasets indicate that our framework can achieve favorable improvements compared with several baselines.
Robust Emotion Recognition in Context Debiasing
Mar 09, 2024Context-aware emotion recognition (CAER) has recently boosted the practical applications of affective computing techniques in unconstrained environments. Mainstream CAER methods invariably extract ensemble representations from diverse contexts and subject-centred characteristics to perceive the target person's emotional state. Despite advancements, the biggest challenge remains due to context bias interference. The harmful bias forces the models to rely on spurious correlations between background contexts and emotion labels in likelihood estimation, causing severe performance bottlenecks and confounding valuable context priors. In this paper, we propose a counterfactual emotion inference (CLEF) framework to address the above issue. Specifically, we first formulate a generalized causal graph to decouple the causal relationships among the variables in CAER. Following the causal graph, CLEF introduces a non-invasive context branch to capture the adverse direct effect caused by the context bias. During the inference, we eliminate the direct context effect from the total causal effect by comparing factual and counterfactual outcomes, resulting in bias mitigation and robust prediction. As a model-agnostic framework, CLEF can be readily integrated into existing methods, bringing consistent performance gains.
HandGCAT: Occlusion-Robust 3D Hand Mesh Reconstruction from Monocular Images
Feb 27, 2024



We propose a robust and accurate method for reconstructing 3D hand mesh from monocular images. This is a very challenging problem, as hands are often severely occluded by objects. Previous works often have disregarded 2D hand pose information, which contains hand prior knowledge that is strongly correlated with occluded regions. Thus, in this work, we propose a novel 3D hand mesh reconstruction network HandGCAT, that can fully exploit hand prior as compensation information to enhance occluded region features. Specifically, we designed the Knowledge-Guided Graph Convolution (KGC) module and the Cross-Attention Transformer (CAT) module. KGC extracts hand prior information from 2D hand pose by graph convolution. CAT fuses hand prior into occluded regions by considering their high correlation. Extensive experiments on popular datasets with challenging hand-object occlusions, such as HO3D v2, HO3D v3, and DexYCB demonstrate that our HandGCAT reaches state-of-the-art performance. The code is available at https://github.com/heartStrive/HandGCAT.
* 6 pages, 4 figures, ICME-2023 conference paper
CPR-Coach: Recognizing Composite Error Actions based on Single-class Training
Sep 21, 2023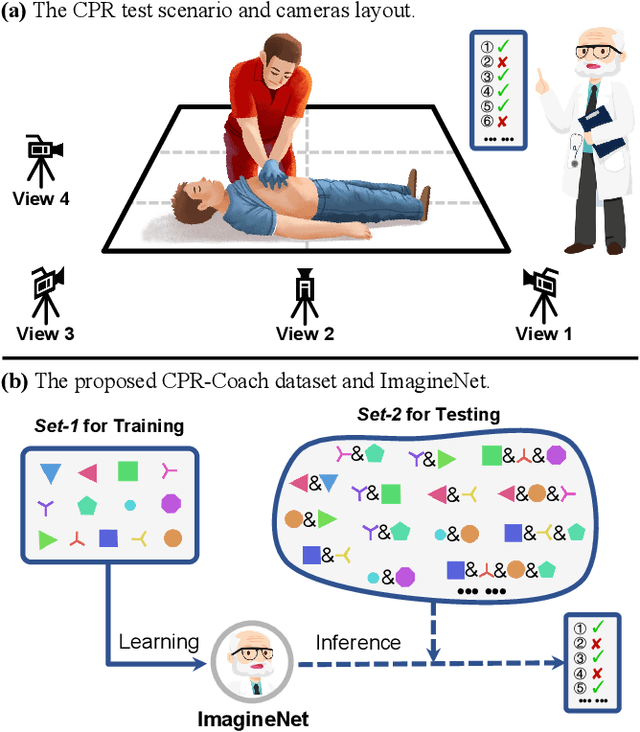
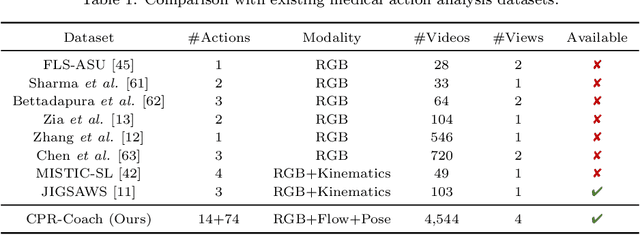

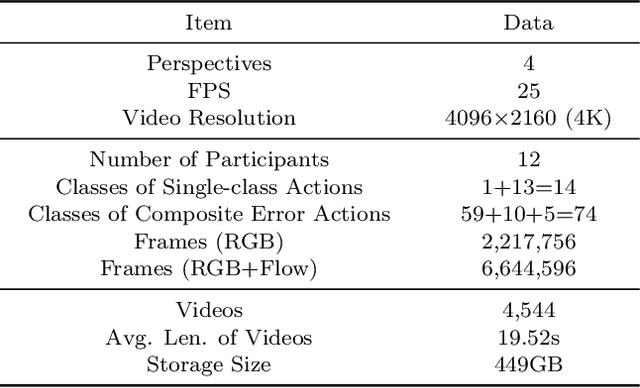
The fine-grained medical action analysis task has received considerable attention from pattern recognition communities recently, but it faces the problems of data and algorithm shortage. Cardiopulmonary Resuscitation (CPR) is an essential skill in emergency treatment. Currently, the assessment of CPR skills mainly depends on dummies and trainers, leading to high training costs and low efficiency. For the first time, this paper constructs a vision-based system to complete error action recognition and skill assessment in CPR. Specifically, we define 13 types of single-error actions and 74 types of composite error actions during external cardiac compression and then develop a video dataset named CPR-Coach. By taking the CPR-Coach as a benchmark, this paper thoroughly investigates and compares the performance of existing action recognition models based on different data modalities. To solve the unavoidable Single-class Training & Multi-class Testing problem, we propose a humancognition-inspired framework named ImagineNet to improve the model's multierror recognition performance under restricted supervision. Extensive experiments verify the effectiveness of the framework. We hope this work could advance research toward fine-grained medical action analysis and skill assessment. The CPR-Coach dataset and the code of ImagineNet are publicly available on Github.
CA-SpaceNet: Counterfactual Analysis for 6D Pose Estimation in Space
Jul 16, 2022

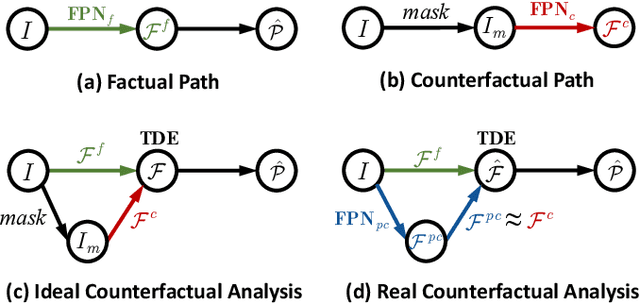

Reliable and stable 6D pose estimation of uncooperative space objects plays an essential role in on-orbit servicing and debris removal missions. Considering that the pose estimator is sensitive to background interference, this paper proposes a counterfactual analysis framework named CASpaceNet to complete robust 6D pose estimation of the spaceborne targets under complicated background. Specifically, conventional methods are adopted to extract the features of the whole image in the factual case. In the counterfactual case, a non-existent image without the target but only the background is imagined. Side effect caused by background interference is reduced by counterfactual analysis, which leads to unbiased prediction in final results. In addition, we also carry out lowbit-width quantization for CA-SpaceNet and deploy part of the framework to a Processing-In-Memory (PIM) accelerator on FPGA. Qualitative and quantitative results demonstrate the effectiveness and efficiency of our proposed method. To our best knowledge, this paper applies causal inference and network quantization to the 6D pose estimation of space-borne targets for the first time. The code is available at https://github.com/Shunli-Wang/CA-SpaceNet.