 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Diffusion Action Segmentation
Paper and Code
Aug 04, 2024
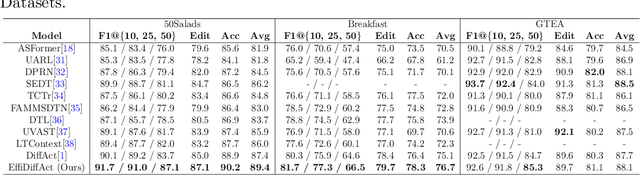
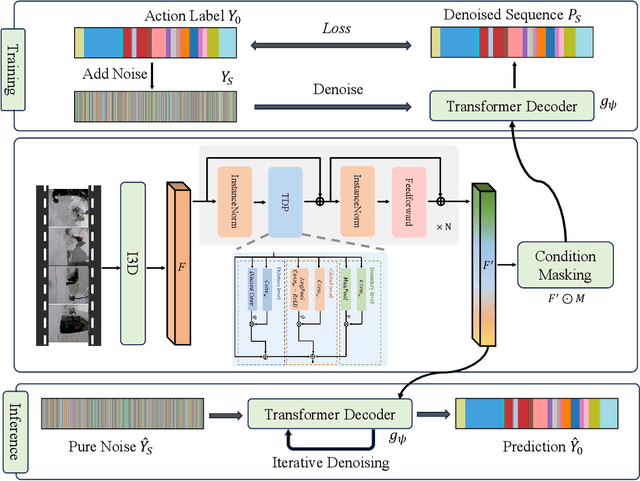

Temporal Action Segmentation (TAS) is an essential task in video analysis, aiming to segment and classify continuous frames into distinct action segments. However, the ambiguous boundaries between actions pose a significant challenge for high-precision segmentation. Recent advances in diffusion models have demonstrated substantial success in TAS tasks due to their stable training process and high-quality generation capabilities. However, the heavy sampling steps required by diffusion models pose a substantial computational burden, limiting their practicality in real-time applications. Additionally, most related works utilize Transformer-based encoder architectures. Although these architectures excel at capturing long-range dependencies, they incur high computational costs and face feature-smoothing issues when processing long video sequences. To address these challenges, we propose EffiDiffAct, an efficient and high-performance TAS algorithm. Specifically, we develop a lightweight temporal feature encoder that reduces computational overhead and mitigates the rank collapse phenomenon associated with traditional self-attention mechanisms. Furthermore, we introduce an adaptive skip strategy that allows for dynamic adjustment of timestep lengths based on computed similarity metrics during inference, thereby further enhancing computational efficiency. Comprehensive experiments on the 50Salads, Breakfast, and GTEA datasets demonstrated the effectiveness of the proposed algorithm.