 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
Open World MRI Reconstruction with Bias-Calibrated Adaptation
Mar 13, 2026Real-world MRI reconstruction systems face the open-world challenge: test data from unseen imaging centers, anatomical structures, or acquisition protocols can differ drastically from training data, causing severe performance degradation. Existing methods struggle with this challenge. To address this, we propose BiasRecon, a bias-calibrated adaptation framework grounded in the minimal intervention principle: preserve what transfers, calibrate what does not. Concretely, BiasRecon formulates open-world adaptation as an alternating optimization framework that jointly optimizes three components: (1) frequency-guided prior calibration that introduces layer-wise calibration variables to selectively modulate frequency-specific features of the pre-trained score network via self-supervised k-space signals, (2) score-based denoising that leverages the calibrated generative prior for high-fidelity image reconstruction, and (3) adaptive regularization that employs Stein's Unbiased Risk Estimator to dynamically balance the prior-measurement trade-off, matching test-time noise characteristics without requiring ground truth. By intervening minimally and precisely through this alternating scheme, BiasRecon achieves robust adaptation with fewer than 100 tunable parameters. Extensive experiments across four datasets demonstrate state-of-the-art performance on open-world reconstruction tasks.
MedQ-Deg: A Multidimensional Benchmark for Evaluating MLLMs Across Medical Image Quality Degradations
Mar 08, 2026Despite impressive performance on standard benchmarks, multimodal large language models (MLLMs) face critical challenges in real-world clinical environments where medical images inevitably suffer various quality degradations. Existing benchmarks exhibit two key limitations: (1) absence of large-scale, multidimensional assessment across medical image quality gradients and (2) no systematic confidence calibration analysis. To address these gaps, we present MedQ-Deg, a comprehensive benchmark for evaluating medical MLLMs under image quality degradations. MedQ-Deg provides multi-dimensional evaluation spanning 18 distinct degradation types, 30 fine-grained capability dimensions, and 7 imaging modalities, with 24,894 question-answer pairs. Each degradation is implemented at 3 severity degrees, calibrated by expert radiologists. We further introduce Calibration Shift metric, which quantifies the gap between a model's perceived confidence and actual performance to assess metacognitive reliability under degradation. Our comprehensive evaluation of 40 mainstream MLLMs reveals several critical findings: (1) overall model performance degrades systematically as degradation severity increases, (2) models universally exhibit the AI Dunning-Kruger Effect, maintaining inappropriately high confidence despite severe accuracy collapse, and (3) models display markedly differentiated behavioral patterns across capability dimensions, imaging modalities, and degradation types. We hope MedQ-Deg drives progress toward medical MLLMs that are robust and trustworthy in real clinical practice.
MedQ-Bench: Evaluating and Exploring Medical Image Quality Assessment Abilities in MLLMs
Oct 02, 2025
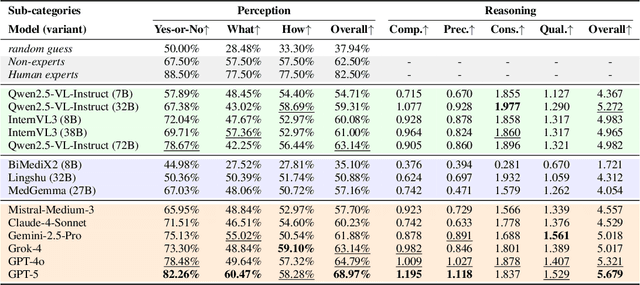
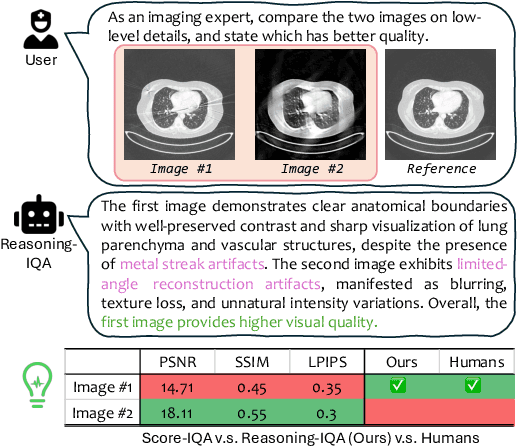

Medical Image Quality Assessment (IQA) serves as the first-mile safety gate for clinical AI, yet existing approaches remain constrained by scalar, score-based metrics and fail to reflect the descriptive, human-like reasoning process central to expert evaluation. To address this gap, we introduce MedQ-Bench, a comprehensive benchmark that establishes a perception-reasoning paradigm for language-based evaluation of medical image quality with Multi-modal Large Language Models (MLLMs). MedQ-Bench defines two complementary tasks: (1) MedQ-Perception, which probes low-level perceptual capability via human-curated questions on fundamental visual attributes; and (2) MedQ-Reasoning, encompassing both no-reference and comparison reasoning tasks, aligning model evaluation with human-like reasoning on image quality. The benchmark spans five imaging modalities and over forty quality attributes, totaling 2,600 perceptual queries and 708 reasoning assessments, covering diverse image sources including authentic clinical acquisitions, images with simulated degradations via physics-based reconstructions, and AI-generated images. To evaluate reasoning ability, we propose a multi-dimensional judging protocol that assesses model outputs along four complementary axes. We further conduct rigorous human-AI alignment validation by comparing LLM-based judgement with radiologists. Our evaluation of 14 state-of-the-art MLLMs demonstrates that models exhibit preliminary but unstable perceptual and reasoning skills, with insufficient accuracy for reliable clinical use. These findings highlight the need for targeted optimization of MLLMs in medical IQA. We hope that MedQ-Bench will catalyze further exploration and unlock the untapped potential of MLLMs for medical image quality evaluation.
MCCD: Multi-Agent Collaboration-based Compositional Diffusion for Complex Text-to-Image Generation
May 05, 2025Diffusion models have shown excellent performance in text-to-image generation. Nevertheless, existing methods often suffer from performance bottlenecks when handling complex prompts that involve multiple objects, characteristics, and relations. Therefore, we propose a Multi-agent Collaboration-based Compositional Diffusion (MCCD) for text-to-image generation for complex scenes. Specifically, we design a multi-agent collaboration-based scene parsing module that generates an agent system comprising multiple agents with distinct tasks, utilizing MLLMs to extract various scene elements effectively. In addition, Hierarchical Compositional diffusion utilizes a Gaussian mask and filtering to refine bounding box regions and enhance objects through region enhancement, resulting in the accurate and high-fidelity generation of complex scenes. Comprehensive experiments demonstrate that our MCCD significantly improves the performance of the baseline models in a training-free manner, providing a substantial advantage in complex scene generation.
Toward Robust Incomplete Multimodal Sentiment Analysis via Hierarchical Representation Learning
Nov 05, 2024



Multimodal Sentiment Analysis (MSA) is an important research area that aims to understand and recognize human sentiment through multiple modalities. The complementary information provided by multimodal fusion promotes better sentiment analysis compared to utilizing only a single modality. Nevertheless, in real-world applications, many unavoidable factors may lead to situations of uncertain modality missing, thus hindering the effectiveness of multimodal modeling and degrading the model's performance. To this end, we propose a Hierarchical Representation Learning Framework (HRLF) for the MSA task under uncertain missing modalities. Specifically, we propose a fine-grained representation factorization module that sufficiently extracts valuable sentiment information by factorizing modality into sentiment-relevant and modality-specific representations through crossmodal translation and sentiment semantic reconstruction. Moreover, a hierarchical mutual information maximization mechanism is introduced to incrementally maximize the mutual information between multi-scale representations to align and reconstruct the high-level semantics in the representations. Ultimately, we propose a hierarchical adversarial learning mechanism that further aligns and adapts the latent distribution of sentiment-relevant representations to produce robust joint multimodal representations. Comprehensive experiments on three datasets demonstrate that HRLF significantly improves MSA performance under uncertain modality missing cases.
MedAide: Towards an Omni Medical Aide via Specialized LLM-based Multi-Agent Collaboration
Oct 17, 2024

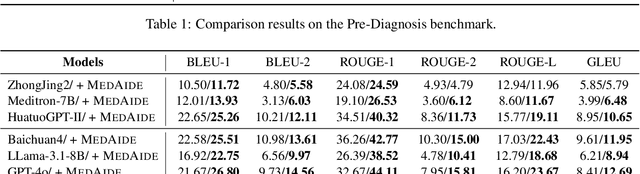

Large Language Model (LLM)-driven interactive systems currently show potential promise in healthcare domains. Despite their remarkable capabilities, LLMs typically lack personalized recommendations and diagnosis analysis in sophisticated medical applications, causing hallucinations and performance bottlenecks. To address these challenges, this paper proposes MedAide, an LLM-based omni medical multi-agent collaboration framework for specialized healthcare services. Specifically, MedAide first performs query rewriting through retrieval-augmented generation to accomplish accurate medical intent understanding. Immediately, we devise a contextual encoder to obtain intent prototype embeddings, which are used to recognize fine-grained intents by similarity matching. According to the intent relevance, the activated agents collaborate effectively to provide integrated decision analysis. Extensive experiments are conducted on four medical benchmarks with composite intents. Experimental results from automated metrics and expert doctor evaluations show that MedAide outperforms current LLMs and improves their medical proficiency and strategic reasoning.
Improving Factuality in Large Language Models via Decoding-Time Hallucinatory and Truthful Comparators
Aug 22, 2024



Despite their remarkable capabilities, Large Language Models (LLMs) are prone to generate responses that contradict verifiable facts, i.e., unfaithful hallucination content. Existing efforts generally focus on optimizing model parameters or editing semantic representations, which compromise the internal factual knowledge of target LLMs. In addition, hallucinations typically exhibit multifaceted patterns in downstream tasks, limiting the model's holistic performance across tasks. In this paper, we propose a Comparator-driven Decoding-Time (CDT) framework to alleviate the response hallucination. Firstly, we construct hallucinatory and truthful comparators with multi-task fine-tuning samples. In this case, we present an instruction prototype-guided mixture of experts strategy to enhance the ability of the corresponding comparators to capture different hallucination or truthfulness patterns in distinct task instructions. CDT constrains next-token predictions to factuality-robust distributions by contrasting the logit differences between the target LLMs and these comparators. Systematic experiments on multiple downstream tasks show that our framework can significantly improve the model performance and response factuality.
PediatricsGPT: Large Language Models as Chinese Medical Assistants for Pediatric Applications
May 29, 2024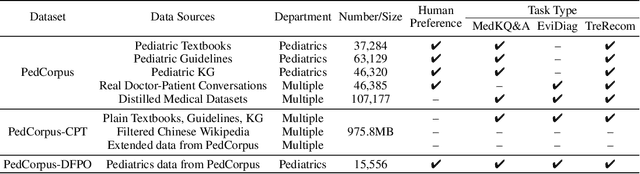
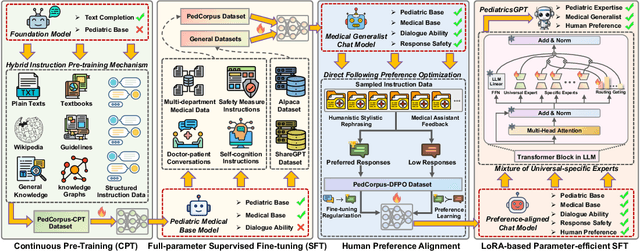
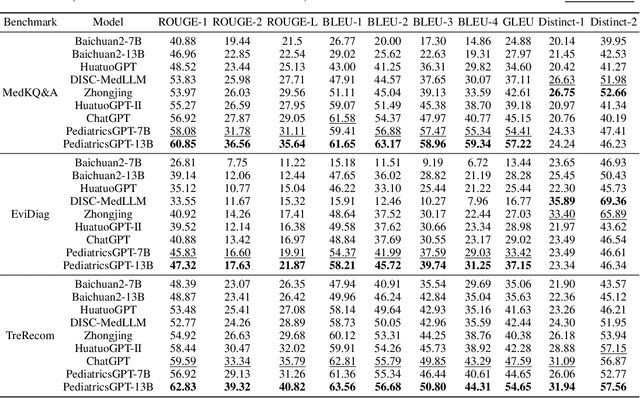
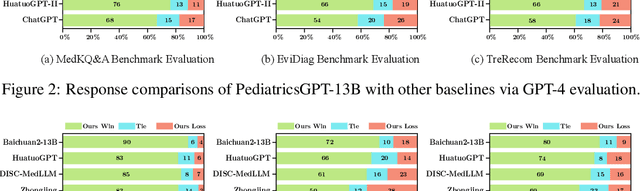
Developing intelligent pediatric consultation systems offers promising prospects for improving diagnostic efficiency, especially in China, where healthcare resources are scarce. Despite recent advances in Large Language Models (LLMs) for Chinese medicine, their performance is sub-optimal in pediatric applications due to inadequate instruction data and vulnerable training procedures. To address the above issues, this paper builds PedCorpus, a high-quality dataset of over 300,000 multi-task instructions from pediatric textbooks, guidelines, and knowledge graph resources to fulfil diverse diagnostic demands. Upon well-designed PedCorpus, we propose PediatricsGPT, the first Chinese pediatric LLM assistant built on a systematic and robust training pipeline. In the continuous pre-training phase, we introduce a hybrid instruction pre-training mechanism to mitigate the internal-injected knowledge inconsistency of LLMs for medical domain adaptation. Immediately, the full-parameter Supervised Fine-Tuning (SFT) is utilized to incorporate the general medical knowledge schema into the models. After that, we devise a direct following preference optimization to enhance the generation of pediatrician-like humanistic responses. In the parameter-efficient secondary SFT phase, a mixture of universal-specific experts strategy is presented to resolve the competency conflict between medical generalist and pediatric expertise mastery. Extensive results based on the metrics, GPT-4, and doctor evaluations on distinct doctor downstream tasks show that PediatricsGPT consistently outperforms previous Chinese medical LLMs. Our model and dataset will be open-source for community development.
Efficiency in Focus: LayerNorm as a Catalyst for Fine-tuning Medical Visual Language Pre-trained Models
Apr 25, 2024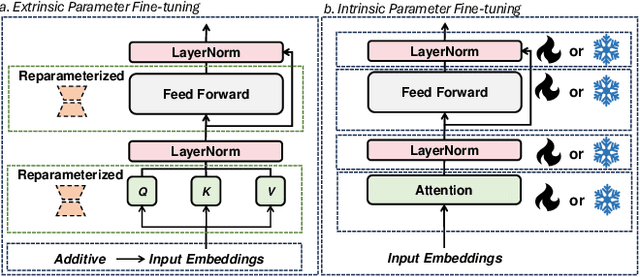
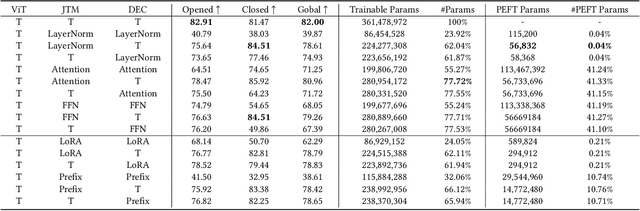
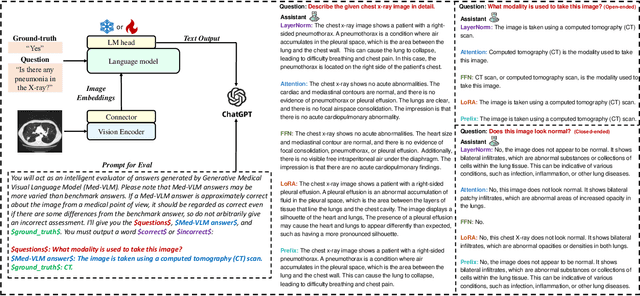
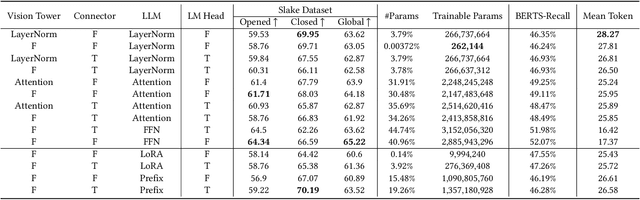
In the realm of Medical Visual Language Models (Med-VLMs), the quest for universal efficient fine-tuning mechanisms remains paramount, especially given researchers in interdisciplinary fields are often extremely short of training resources, yet largely unexplored. Given the unique challenges in the medical domain, such as limited data scope and significant domain-specific requirements, evaluating and adapting Parameter-Efficient Fine-Tuning (PEFT) methods specifically for Med-VLMs is essential. Most of the current PEFT methods on Med-VLMs have yet to be comprehensively investigated but mainly focus on adding some components to the model's structure or input. However, fine-tuning intrinsic model components often yields better generality and consistency, and its impact on the ultimate performance of Med-VLMs has been widely overlooked and remains understudied. In this paper, we endeavour to explore an alternative to traditional PEFT methods, especially the impact of fine-tuning LayerNorm layers, FFNs and Attention layers on the Med-VLMs. Our comprehensive studies span both small-scale and large-scale Med-VLMs, evaluating their performance under various fine-tuning paradigms across tasks such as Medical Visual Question Answering and Medical Imaging Report Generation. The findings reveal unique insights into the effects of intrinsic parameter fine-tuning methods on fine-tuning Med-VLMs to downstream tasks and expose fine-tuning solely the LayerNorm layers not only surpasses the efficiency of traditional PEFT methods but also retains the model's accuracy and generalization capabilities across a spectrum of medical downstream tasks. The experiments show LayerNorm fine-tuning's superior adaptability and scalability, particularly in the context of large-scale Med-VLMs.