 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multimodal Human Intention Understanding Debiasing via Subject-Deconfounding
Paper and Code
Mar 08, 2024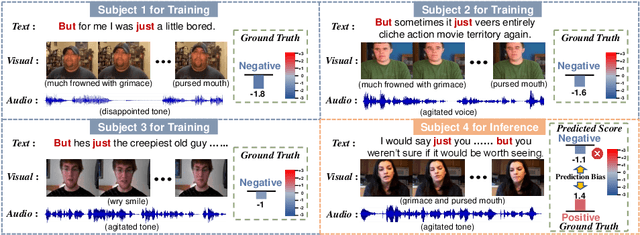
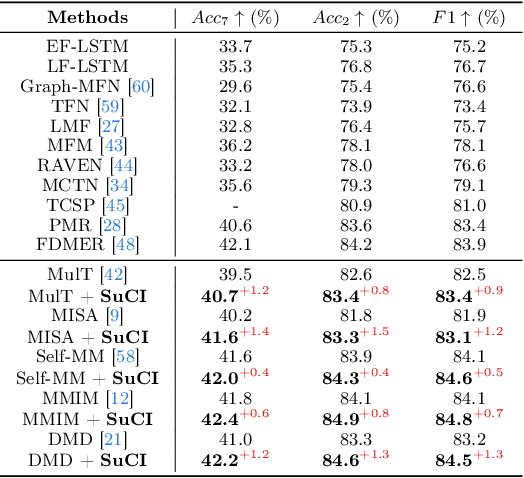
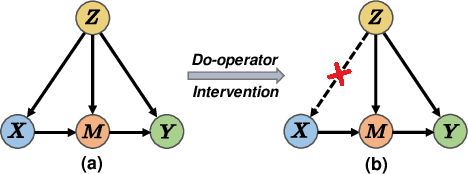
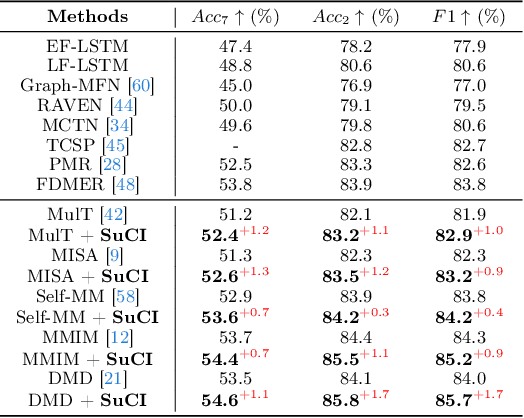
Multimodal intention understanding (MIU) is an indispensable component of human expression analysis (e.g., sentiment or humor) from heterogeneous modalities, including visual postures, linguistic contents, and acoustic behaviors. Existing works invariably focus on designing sophisticated structures or fusion strategies to achieve impressive improvements. Unfortunately, they all suffer from the subject variation problem due to data distribution discrepancies among subjects. Concretely, MIU models are easily misled by distinct subjects with different expression customs and characteristics in the training data to learn subject-specific spurious correlations, significantly limiting performance and generalizability across uninitiated subjects.Motivated by this observation, we introduce a recapitulative causal graph to formulate the MIU procedure and analyze the confounding effect of subjects. Then, we propose SuCI, a simple yet effective causal intervention module to disentangle the impact of subjects acting as unobserved confounders and achieve model training via true causal effects. As a plug-and-play component, SuCI can be widely applied to most methods that seek unbiased predictions. Comprehensive experiments on several MIU benchmarks clearly demonstrate the effectiveness of the proposed module.