 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandGCAT: Occlusion-Robust 3D Hand Mesh Reconstruction from Monocular Images
Feb 27, 2024



We propose a robust and accurate method for reconstructing 3D hand mesh from monocular images. This is a very challenging problem, as hands are often severely occluded by objects. Previous works often have disregarded 2D hand pose information, which contains hand prior knowledge that is strongly correlated with occluded regions. Thus, in this work, we propose a novel 3D hand mesh reconstruction network HandGCAT, that can fully exploit hand prior as compensation information to enhance occluded region features. Specifically, we designed the Knowledge-Guided Graph Convolution (KGC) module and the Cross-Attention Transformer (CAT) module. KGC extracts hand prior information from 2D hand pose by graph convolution. CAT fuses hand prior into occluded regions by considering their high correlation. Extensive experiments on popular datasets with challenging hand-object occlusions, such as HO3D v2, HO3D v3, and DexYCB demonstrate that our HandGCAT reaches state-of-the-art performance. The code is available at https://github.com/heartStrive/HandGCAT.
* 6 pages, 4 figures, ICME-2023 conference paper
CPR-Coach: Recognizing Composite Error Actions based on Single-class Training
Sep 21, 2023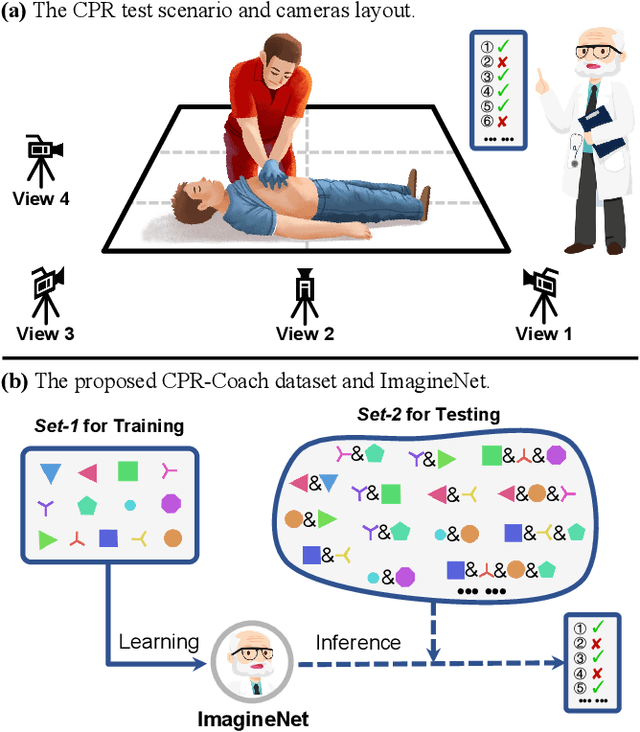
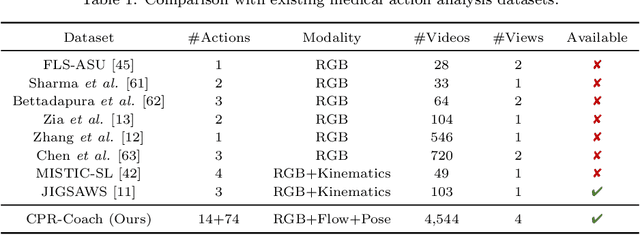

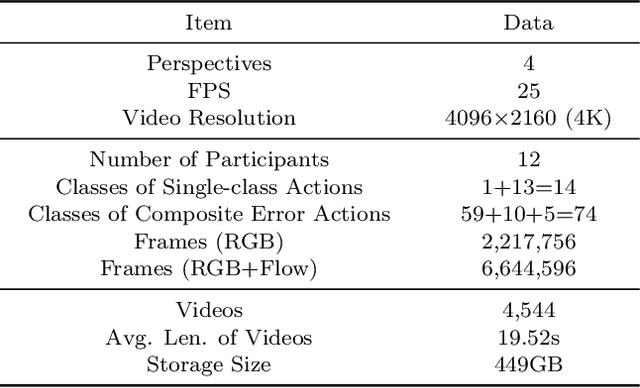
The fine-grained medical action analysis task has received considerable attention from pattern recognition communities recently, but it faces the problems of data and algorithm shortage. Cardiopulmonary Resuscitation (CPR) is an essential skill in emergency treatment. Currently, the assessment of CPR skills mainly depends on dummies and trainers, leading to high training costs and low efficiency. For the first time, this paper constructs a vision-based system to complete error action recognition and skill assessment in CPR. Specifically, we define 13 types of single-error actions and 74 types of composite error actions during external cardiac compression and then develop a video dataset named CPR-Coach. By taking the CPR-Coach as a benchmark, this paper thoroughly investigates and compares the performance of existing action recognition models based on different data modalities. To solve the unavoidable Single-class Training & Multi-class Testing problem, we propose a humancognition-inspired framework named ImagineNet to improve the model's multierror recognition performance under restricted supervision. Extensive experiments verify the effectiveness of the framework. We hope this work could advance research toward fine-grained medical action analysis and skill assessment. The CPR-Coach dataset and the code of ImagineNet are publicly available on Github.
CA-SpaceNet: Counterfactual Analysis for 6D Pose Estimation in Space
Jul 16, 2022

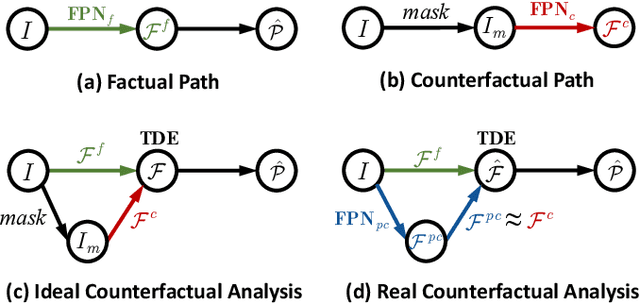

Reliable and stable 6D pose estimation of uncooperative space objects plays an essential role in on-orbit servicing and debris removal missions. Considering that the pose estimator is sensitive to background interference, this paper proposes a counterfactual analysis framework named CASpaceNet to complete robust 6D pose estimation of the spaceborne targets under complicated background. Specifically, conventional methods are adopted to extract the features of the whole image in the factual case. In the counterfactual case, a non-existent image without the target but only the background is imagined. Side effect caused by background interference is reduced by counterfactual analysis, which leads to unbiased prediction in final results. In addition, we also carry out lowbit-width quantization for CA-SpaceNet and deploy part of the framework to a Processing-In-Memory (PIM) accelerator on FPGA. Qualitative and quantitative results demonstrate the effectiveness and efficiency of our proposed method. To our best knowledge, this paper applies causal inference and network quantization to the 6D pose estimation of space-borne targets for the first time. The code is available at https://github.com/Shunli-Wang/CA-SpaceNet.