 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Convergence Rate of Ray Search Optimization for Query-Efficient Hard-Label Attacks
Dec 24, 2025In hard-label black-box adversarial attacks, where only the top-1 predicted label is accessible, the prohibitive query complexity poses a major obstacle to practical deployment. In this paper, we focus on optimizing a representative class of attacks that search for the optimal ray direction yielding the minimum $\ell_2$-norm perturbation required to move a benign image into the adversarial region. Inspired by Nesterov's Accelerated Gradient (NAG), we propose a momentum-based algorithm, ARS-OPT, which proactively estimates the gradient with respect to a future ray direction inferred from accumulated momentum. We provide a theoretical analysis of its convergence behavior, showing that ARS-OPT enables more accurate directional updates and achieves faster, more stable optimization. To further accelerate convergence, we incorporate surrogate-model priors into ARS-OPT's gradient estimation, resulting in PARS-OPT with enhanced performance. The superiority of our approach is supported by theoretical guarantees under standard assumptions. Extensive experiments on ImageNet and CIFAR-10 demonstrate that our method surpasses 13 state-of-the-art approaches in query efficiency.
Boosting Ray Search Procedure of Hard-label Attacks with Transfer-based Priors
Jul 23, 2025One of the most practical and challenging types of black-box adversarial attacks is the hard-label attack, where only the top-1 predicted label is available. One effective approach is to search for the optimal ray direction from the benign image that minimizes the $\ell_p$-norm distance to the adversarial region. The unique advantage of this approach is that it transforms the hard-label attack into a continuous optimization problem. The objective function value is the ray's radius, which can be obtained via binary search at a high query cost. Existing methods use a "sign trick" in gradient estimation to reduce the number of queries. In this paper, we theoretically analyze the quality of this gradient estimation and propose a novel prior-guided approach to improve ray search efficiency both theoretically and empirically. Specifically, we utilize the transfer-based priors from surrogate models, and our gradient estimators appropriately integrate them by approximating the projection of the true gradient onto the subspace spanned by these priors and random directions, in a query-efficient manner. We theoretically derive the expected cosine similarities between the obtained gradient estimators and the true gradient, and demonstrate the improvement achieved by incorporating priors. Extensive experiments on the ImageNet and CIFAR-10 datasets show that our approach significantly outperforms 11 state-of-the-art methods in terms of query efficiency.
XUAT-Copilot: Multi-Agent Collaborative System for Automated User Acceptance Testing with Large Language Model
Jan 10, 2024In past years, we have been dedicated to automating user acceptance testing (UAT) process of WeChat Pay, one of the most influential mobile payment applications in China. A system titled XUAT has been developed for this purpose. However, there is still a human-labor-intensive stage, i.e, test scripts generation, in the current system. Therefore, in this paper, we concentrate on methods of boosting the automation level of the current system, particularly the stage of test scripts generation. With recent notable successes, large language models (LLMs) demonstrate significant potential in attaining human-like intelligence and there has been a growing research area that employs LLMs as autonomous agents to obtain human-like decision-making capabilities. Inspired by these works, we propose an LLM-powered multi-agent collaborative system, named XUAT-Copilot, for automated UAT. The proposed system mainly consists of three LLM-based agents responsible for action planning, state checking and parameter selecting, respectively, and two additional modules for state sensing and case rewriting. The agents interact with testing device, make human-like decision and generate action command in a collaborative way. The proposed multi-agent system achieves a close effectiveness to human testers in our experimental studies and gains a significant improvement of Pass@1 accuracy compared with single-agent architecture. More importantly, the proposed system has launched in the formal testing environment of WeChat Pay mobile app, which saves a considerable amount of manpower in the daily development work.
Mixing Signals: Data Augmentation Approach for Deep Learning Based Modulation Recognition
Apr 05, 2022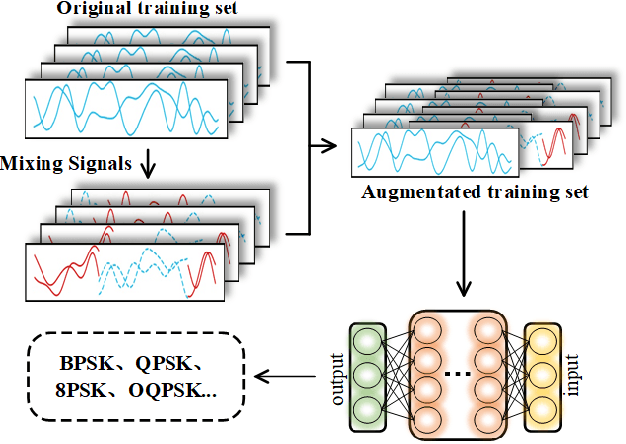
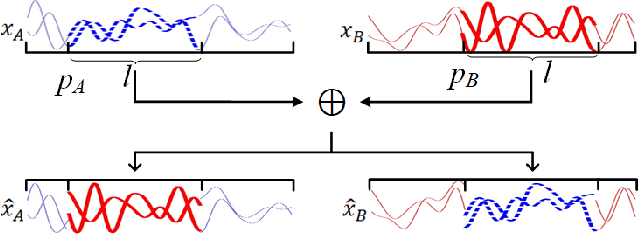
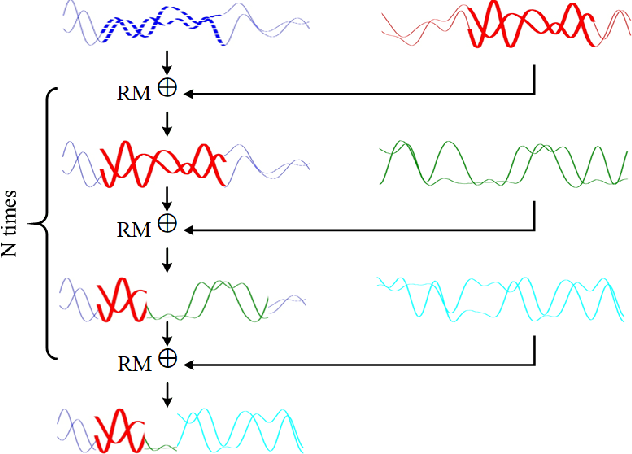

With the rapid development of deep learning, automatic modulation recognition (AMR), as an important task in cognitive radio, has gradually transformed from traditional feature extraction and classification to automatic classification by deep learning technology. However, deep learning models are data-driven methods, which often require a large amount of data as the training support. Data augmentation, as the strategy of expanding dataset, can improve the generalization of the deep learning models and thus improve the accuracy of the models to a certain extent. In this paper, for AMR of radio signals, we propose a data augmentation strategy based on mixing signals and consider four specific methods (Random Mixing, Maximum-Similarity-Mixing, $\theta-$Similarity Mixing and n-times Random Mixing) to achieve data augmentation. Experiments show that our proposed method can improve the classification accuracy of deep learning based AMR models in the full public dataset RML2016.10a. In particular, for the case of a single signal-to-noise ratio signal set, the classification accuracy can be significantly improved, which verifies the effectiveness of the methods.