 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Convergence Rate of Ray Search Optimization for Query-Efficient Hard-Label Attacks
Dec 24, 2025In hard-label black-box adversarial attacks, where only the top-1 predicted label is accessible, the prohibitive query complexity poses a major obstacle to practical deployment. In this paper, we focus on optimizing a representative class of attacks that search for the optimal ray direction yielding the minimum $\ell_2$-norm perturbation required to move a benign image into the adversarial region. Inspired by Nesterov's Accelerated Gradient (NAG), we propose a momentum-based algorithm, ARS-OPT, which proactively estimates the gradient with respect to a future ray direction inferred from accumulated momentum. We provide a theoretical analysis of its convergence behavior, showing that ARS-OPT enables more accurate directional updates and achieves faster, more stable optimization. To further accelerate convergence, we incorporate surrogate-model priors into ARS-OPT's gradient estimation, resulting in PARS-OPT with enhanced performance. The superiority of our approach is supported by theoretical guarantees under standard assumptions. Extensive experiments on ImageNet and CIFAR-10 demonstrate that our method surpasses 13 state-of-the-art approaches in query efficiency.
\emph{FoQuS}: A Forgetting-Quality Coreset Selection Framework for Automatic Modulation Recognition
Sep 10, 2025Deep learning-based Automatic Modulation Recognition (AMR) model has made significant progress with the support of large-scale labeled data. However, when developing new models or performing hyperparameter tuning, the time and energy consumption associated with repeated training using massive amounts of data are often unbearable. To address the above challenges, we propose \emph{FoQuS}, which approximates the effect of full training by selecting a coreset from the original dataset, thereby significantly reducing training overhead. Specifically, \emph{FoQuS} records the prediction trajectory of each sample during full-dataset training and constructs three importance metrics based on training dynamics. Experiments show that \emph{FoQuS} can maintain high recognition accuracy and good cross-architecture generalization on multiple AMR datasets using only 1\%-30\% of the original data.
DUSE: A Data Expansion Framework for Low-resource Automatic Modulation Recognition based on Active Learning
Jul 16, 2025Although deep neural networks have made remarkable achievements in the field of automatic modulation recognition (AMR), these models often require a large amount of labeled data for training. However, in many practical scenarios, the available target domain data is scarce and difficult to meet the needs of model training. The most direct way is to collect data manually and perform expert annotation, but the high time and labor costs are unbearable. Another common method is data augmentation. Although it can enrich training samples to a certain extent, it does not introduce new data and therefore cannot fundamentally solve the problem of data scarcity. To address these challenges, we introduce a data expansion framework called Dynamic Uncertainty-driven Sample Expansion (DUSE). Specifically, DUSE uses an uncertainty scoring function to filter out useful samples from relevant AMR datasets and employs an active learning strategy to continuously refine the scorer. Extensive experiments demonstrate that DUSE consistently outperforms 8 coreset selection baselines in both class-balance and class-imbalance settings. Besides, DUSE exhibits strong cross-architecture generalization for unseen models.
FCOS: A Two-Stage Recoverable Model Pruning Framework for Automatic Modulation Recognition
May 27, 2025With the rapid development of wireless communications and the growing complexity of digital modulation schemes, traditional manual modulation recognition methods struggle to extract reliable signal features and meet real-time requirements in modern scenarios. Recently, deep learning based Automatic Modulation Recognition (AMR) approaches have greatly improved classification accuracy. However, their large model sizes and high computational demands hinder deployment on resource-constrained devices. Model pruning provides a general approach to reduce model complexity, but existing weight, channel, and layer pruning techniques each present a trade-off between compression rate, hardware acceleration, and accuracy preservation. To this end, in this paper, we introduce FCOS, a novel Fine-to-COarse two-Stage pruning framework that combines channel-level pruning with layer-level collapse diagnosis to achieve extreme compression, high performance and efficient inference. In the first stage of FCOS, hierarchical clustering and parameter fusion are applied to channel weights to achieve channel-level pruning. Then a Layer Collapse Diagnosis (LaCD) module uses linear probing to identify layer collapse and removes the collapsed layers due to high channel compression ratio. Experiments on multiple AMR benchmarks demonstrate that FCOS outperforms existing channel and layer pruning methods. Specifically, FCOS achieves 95.51% FLOPs reduction and 95.31% parameter reduction while still maintaining performance close to the original ResNet56, with only a 0.46% drop in accuracy on Sig2019-12. Code is available at https://github.com/yaolu-zjut/FCOS.
MCLRL: A Multi-Domain Contrastive Learning with Reinforcement Learning Framework for Few-Shot Modulation Recognition
Feb 26, 2025



With the rapid advancements in wireless communication technology, automatic modulation recognition (AMR) plays a critical role in ensuring communication security and reliability. However, numerous challenges, including higher performance demands, difficulty in data acquisition under specific scenarios, limited sample size, and low-quality labeled data, hinder its development. Few-shot learning (FSL) offers an effective solution by enabling models to achieve satisfactory performance with only a limited number of labeled samples. While most FSL techniques are applied in the field of computer vision, they are not directly applicable to wireless signal processing. This study does not propose a new FSL-specific signal model but introduces a framework called MCLRL. This framework combines multi-domain contrastive learning with reinforcement learning. Multi-domain representations of signals enhance feature richness, while integrating contrastive learning and reinforcement learning architectures enables the extraction of deep features for classification. In downstream tasks, the model achieves excellent performance using only a few samples and minimal training cycles. Experimental results show that the MCLRL framework effectively extracts key features from signals, performs well in FSL tasks, and maintains flexibility in signal model selection.
Reassessing Layer Pruning in LLMs: New Insights and Methods
Nov 23, 2024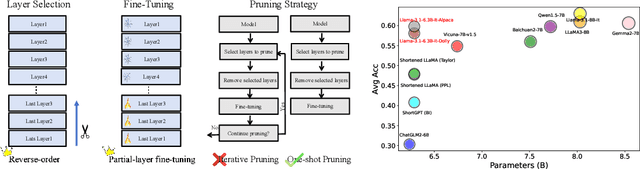
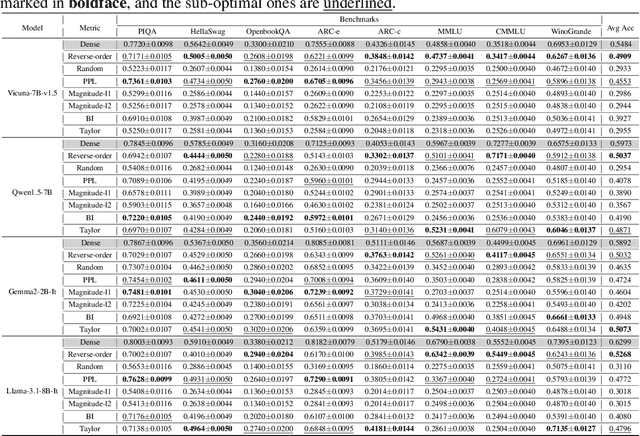
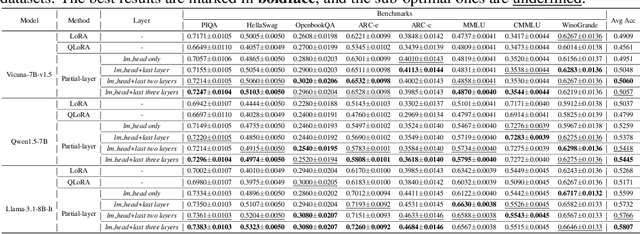
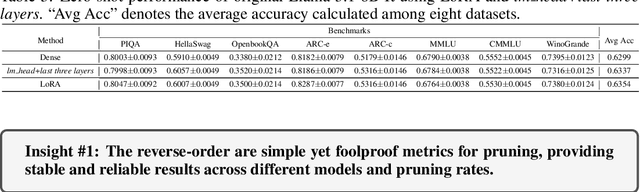
Although large language models (LLMs) have achieved remarkable success across various domains, their considerable scale necessitates substantial computational resources, posing significant challenges for deployment in resource-constrained environments. Layer pruning, as a simple yet effective compression method, removes layers of a model directly, reducing computational overhead. However, what are the best practices for layer pruning in LLMs? Are sophisticated layer selection metrics truly effective? Does the LoRA (Low-Rank Approximation) family, widely regarded as a leading method for pruned model fine-tuning, truly meet expectations when applied to post-pruning fine-tuning? To answer these questions, we dedicate thousands of GPU hours to benchmarking layer pruning in LLMs and gaining insights across multiple dimensions. Our results demonstrate that a simple approach, i.e., pruning the final 25\% of layers followed by fine-tuning the \texttt{lm\_head} and the remaining last three layer, yields remarkably strong performance. Following this guide, we prune Llama-3.1-8B-It and obtain a model that outperforms many popular LLMs of similar size, such as ChatGLM2-6B, Vicuna-7B-v1.5, Qwen1.5-7B and Baichuan2-7B. We release the optimal model weights on Huggingface, and the code is available on GitHub.
MDM: Advancing Multi-Domain Distribution Matching for Automatic Modulation Recognition Dataset Synthesis
Aug 05, 2024Recently, deep learning technology has been successfully introduced into Automatic Modulation Recognition (AMR) tasks. However, the success of deep learning is all attributed to the training on large-scale datasets. Such a large amount of data brings huge pressure on storage, transmission and model training. In order to solve the problem of large amount of data, some researchers put forward the method of data distillation, which aims to compress large training data into smaller synthetic datasets to maintain its performance. While numerous data distillation techniques have been developed within the realm of image processing, the unique characteristics of signals set them apart. Signals exhibit distinct features across various domains, necessitating specialized approaches for their analysis and processing. To this end, a novel dataset distillation method--Multi-domain Distribution Matching (MDM) is proposed. MDM employs the Discrete Fourier Transform (DFT) to translate timedomain signals into the frequency domain, and then uses a model to compute distribution matching losses between the synthetic and real datasets, considering both the time and frequency domains. Ultimately, these two losses are integrated to update the synthetic dataset. We conduct extensive experiments on three AMR datasets. Experimental results show that, compared with baseline methods, our method achieves better performance under the same compression ratio. Furthermore, we conduct crossarchitecture generalization experiments on several models, and the experimental results show that our synthetic datasets can generalize well on other unseen models.
A Generic Layer Pruning Method for Signal Modulation Recognition Deep Learning Models
Jun 12, 2024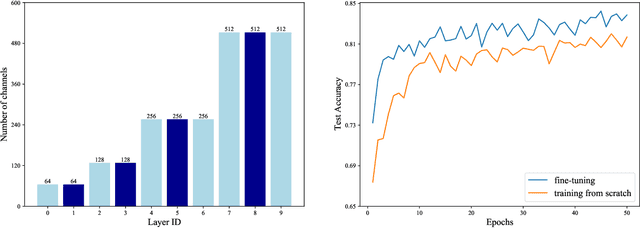
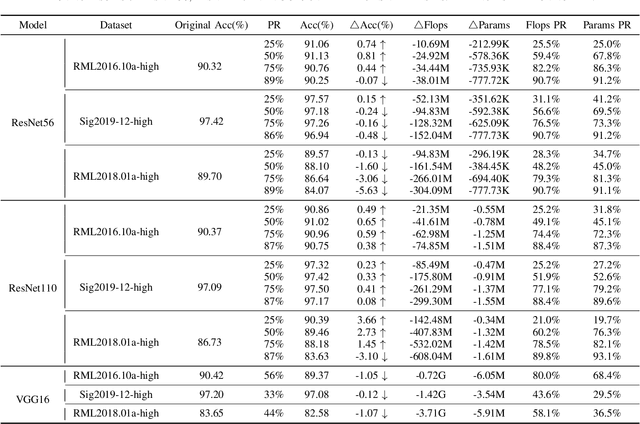
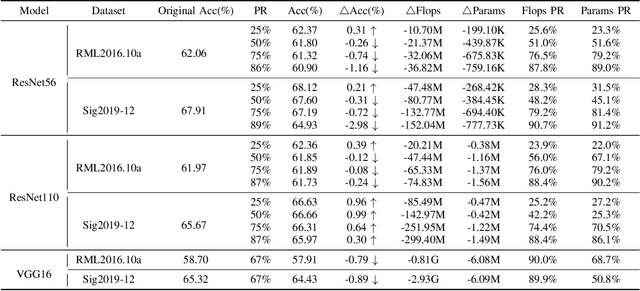

With the successful application of deep learning in communications systems, deep neural networks are becoming the preferred method for signal classification. Although these models yield impressive results, they often come with high computational complexity and large model sizes, which hinders their practical deployment in communication systems. To address this challenge, we propose a novel layer pruning method. Specifically, we decompose the model into several consecutive blocks, each containing consecutive layers with similar semantics. Then, we identify layers that need to be preserved within each block based on their contribution. Finally, we reassemble the pruned blocks and fine-tune the compact model. Extensive experiments on five datasets demonstrate the efficiency and effectiveness of our method over a variety of state-of-the-art baselines, including layer pruning and channel pruning methods.
Mixing Signals: Data Augmentation Approach for Deep Learning Based Modulation Recognition
Apr 05, 2022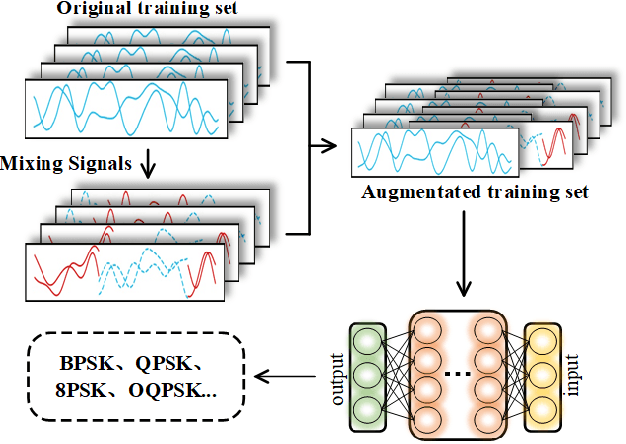
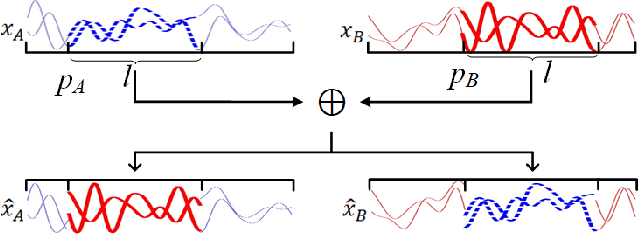
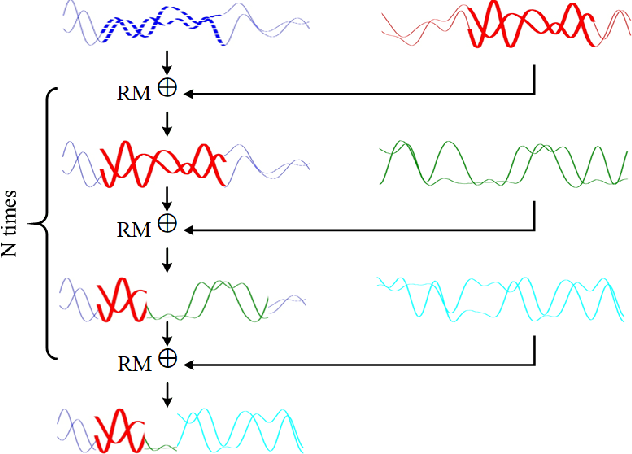

With the rapid development of deep learning, automatic modulation recognition (AMR), as an important task in cognitive radio, has gradually transformed from traditional feature extraction and classification to automatic classification by deep learning technology. However, deep learning models are data-driven methods, which often require a large amount of data as the training support. Data augmentation, as the strategy of expanding dataset, can improve the generalization of the deep learning models and thus improve the accuracy of the models to a certain extent. In this paper, for AMR of radio signals, we propose a data augmentation strategy based on mixing signals and consider four specific methods (Random Mixing, Maximum-Similarity-Mixing, $\theta-$Similarity Mixing and n-times Random Mixing) to achieve data augmentation. Experiments show that our proposed method can improve the classification accuracy of deep learning based AMR models in the full public dataset RML2016.10a. In particular, for the case of a single signal-to-noise ratio signal set, the classification accuracy can be significantly improved, which verifies the effectiveness of the methods.
Deep Transfer Clustering of Radio Signals
Jul 26, 2021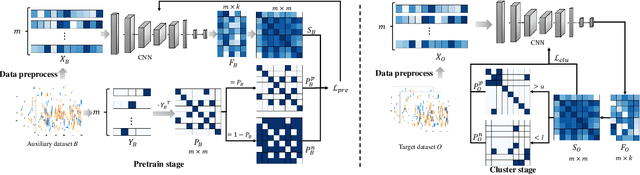
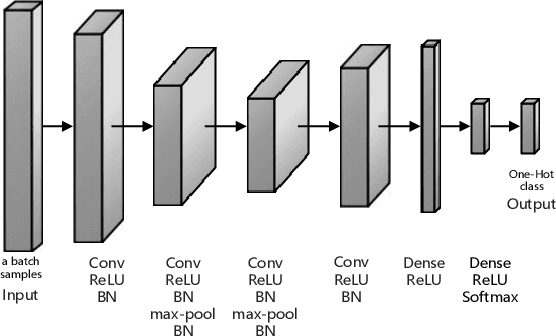

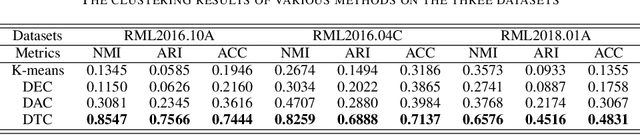
Modulation recognition is an important task in radio signal processing. Most of the current researches focus on supervised learning. However, in many real scenarios, it is difficult and cost to obtain the labels of signals. In this letter, we turn to the more challenging problem: can we cluster the modulation types just based on a large number of unlabeled radio signals? If this problem can be solved, we then can also recognize modulation types by manually labeling a very small number of samples. To answer this problem, we propose a deep transfer clustering (DTC) model. DTC naturally integrates feature learning and deep clustering, and further adopts a transfer learning mechanism to improve the feature extraction ability of an embedded convolutional neural network (CNN) model. The experiments validate that our DTC significantly outperforms a number of baselines, achieving the state-of-the-art performance in clustering radio signals for modulation recognition.