 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvSW: Overcoming Silent Weights for Accurate Binary Neural Networks
Paper and Code
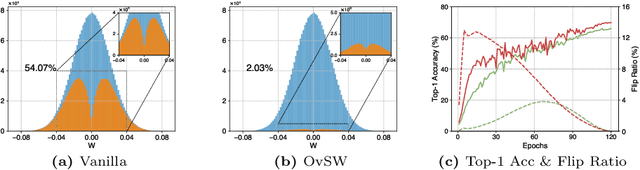


Binary Neural Networks~(BNNs) have been proven to be highly effective for deploying deep neural networks on mobile and embedded platforms. Most existing works focus on minimizing quantization errors, improving representation ability, or designing gradient approximations to alleviate gradient mismatch in BNNs, while leaving the weight sign flipping, a critical factor for achieving powerful BNNs, untouched. In this paper, we investigate the efficiency of weight sign updates in BNNs. We observe that, for vanilla BNNs, over 50\% of the weights remain their signs unchanged during training, and these weights are not only distributed at the tails of the weight distribution but also universally present in the vicinity of zero. We refer to these weights as ``silent weights'', which slow down convergence and lead to a significant accuracy degradation. Theoretically, we reveal this is due to the independence of the BNNs gradient from the latent weight distribution. To address the issue, we propose Overcome Silent Weights~(OvSW). OvSW first employs Adaptive Gradient Scaling~(AGS) to establish a relationship between the gradient and the latent weight distribution, thereby improving the overall efficiency of weight sign updates. Additionally, we design Silence Awareness Decaying~(SAD) to automatically identify ``silent weights'' by tracking weight flipping state, and apply an additional penalty to ``silent weights'' to facilitate their flipping. By efficiently updating weight signs, our method achieves faster convergence and state-of-the-art performance on CIFAR10 and ImageNet1K dataset with various architectures. For example, OvSW obtains 61.6\% and 65.5\% top-1 accuracy on the ImageNet1K using binarized ResNet18 and ResNet34 architecture respectively. Codes are available at \url{https://github.com/JingyangXiang/OvSW}.