 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Event-based Monocular Depth Estimation using Cross-modal Consistency
Jan 14, 2024An event camera is a novel vision sensor that can capture per-pixel brightness changes and output a stream of asynchronous ``events''. It has advantages over conventional cameras in those scenes with high-speed motions and challenging lighting conditions because of the high temporal resolution, high dynamic range, low bandwidth, low power consumption, and no motion blur. Therefore, several supervised monocular depth estimation from events is proposed to address scenes difficult for conventional cameras. However, depth annotation is costly and time-consuming. In this paper, to lower the annotation cost, we propose a self-supervised event-based monocular depth estimation framework named EMoDepth. EMoDepth constrains the training process using the cross-modal consistency from intensity frames that are aligned with events in the pixel coordinate. Moreover, in inference, only events are used for monocular depth prediction. Additionally, we design a multi-scale skip-connection architecture to effectively fuse features for depth estimation while maintaining high inference speed. Experiments on MVSEC and DSEC datasets demonstrate that our contributions are effective and that the accuracy can outperform existing supervised event-based and unsupervised frame-based methods.
Camera-based 3D Semantic Scene Completion with Sparse Guidance Network
Dec 10, 2023



Semantic scene completion (SSC) aims to predict the semantic occupancy of each voxel in the entire 3D scene from limited observations, which is an emerging and critical task for autonomous driving. Recently, many studies have turned to camera-based SSC solutions due to the richer visual cues and cost-effectiveness of cameras. However, existing methods usually rely on sophisticated and heavy 3D models to directly process the lifted 3D features that are not discriminative enough for clear segmentation boundaries. In this paper, we adopt the dense-sparse-dense design and propose an end-to-end camera-based SSC framework, termed SGN, to diffuse semantics from the semantic- and occupancy-aware seed voxels to the whole scene based on geometry prior and occupancy information. By designing hybrid guidance (sparse semantic and geometry guidance) and effective voxel aggregation for spatial occupancy and geometry priors, we enhance the feature separation between different categories and expedite the convergence of semantic diffusion. Extensive experimental results on the SemanticKITTI dataset demonstrate the superiority of our SGN over existing state-of-the-art methods.
Semi-Supervised Learning for Visual Bird's Eye View Semantic Segmentation
Aug 28, 2023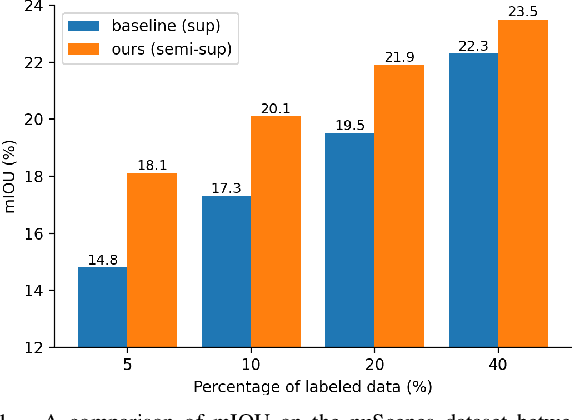
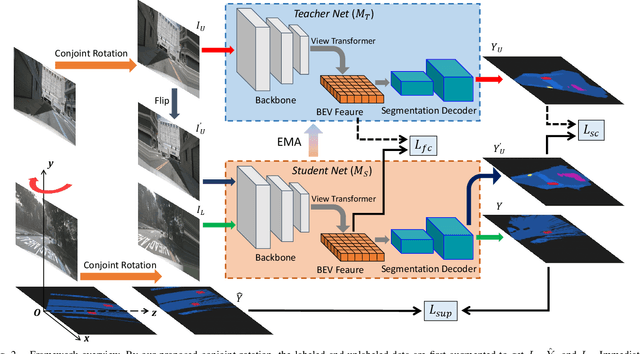
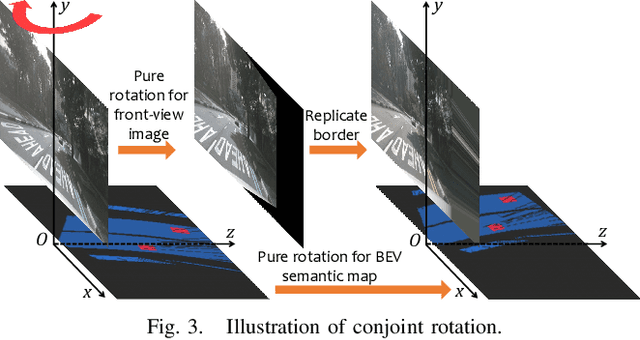
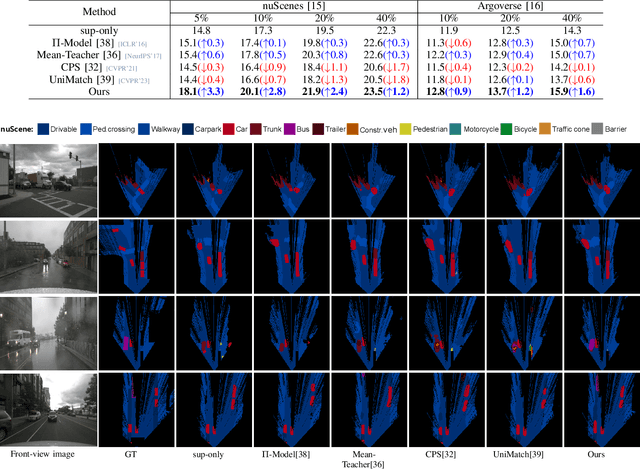
Visual bird's eye view (BEV) semantic segmentation helps autonomous vehicles understand the surrounding environment only from images, including static elements (e.g., roads) and dynamic elements (e.g., vehicles, pedestrians). However, the high cost of annotation procedures of full-supervised methods limits the capability of the visual BEV semantic segmentation, which usually needs HD maps, 3D object bounding boxes, and camera extrinsic matrixes. In this paper, we present a novel semi-supervised framework for visual BEV semantic segmentation to boost performance by exploiting unlabeled images during the training. A consistency loss that makes full use of unlabeled data is then proposed to constrain the model on not only semantic prediction but also the BEV feature. Furthermore, we propose a novel and effective data augmentation method named conjoint rotation which reasonably augments the dataset while maintaining the geometric relationship between the front-view images and the BEV semantic segmentation. Extensive experiments on the nuScenes and Argoverse datasets show that our semi-supervised framework can effectively improve prediction accuracy. To the best of our knowledge, this is the first work that explores improving visual BEV semantic segmentation performance using unlabeled data. The code will be publicly available.
FG-Depth: Flow-Guided Unsupervised Monocular Depth Estimation
Jan 20, 2023



The great potential of unsupervised monocular depth estimation has been demonstrated by many works due to low annotation cost and impressive accuracy comparable to supervised methods. To further improve the performance, recent works mainly focus on designing more complex network structures and exploiting extra supervised information, e.g., semantic segmentation. These methods optimize the models by exploiting the reconstructed relationship between the target and reference images in varying degrees. However, previous methods prove that this image reconstruction optimization is prone to get trapped in local minima. In this paper, our core idea is to guide the optimization with prior knowledge from pretrained Flow-Net. And we show that the bottleneck of unsupervised monocular depth estimation can be broken with our simple but effective framework named FG-Depth. In particular, we propose (i) a flow distillation loss to replace the typical photometric loss that limits the capacity of the model and (ii) a prior flow based mask to remove invalid pixels that bring the noise in training loss. Extensive experiments demonstrate the effectiveness of each component, and our approach achieves state-of-the-art results on both KITTI and NYU-Depth-v2 datasets.