 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Learning for Visual Bird's Eye View Semantic Segmentation
Paper and Code
Aug 28, 2023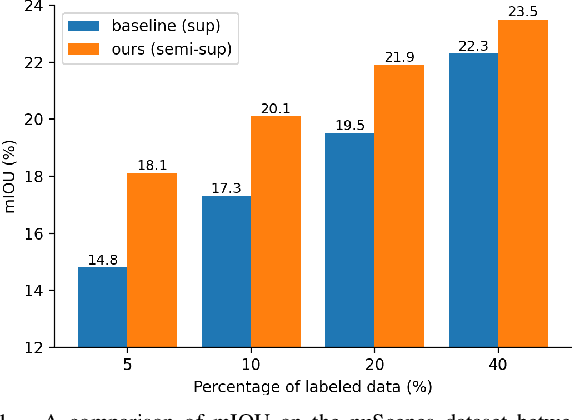
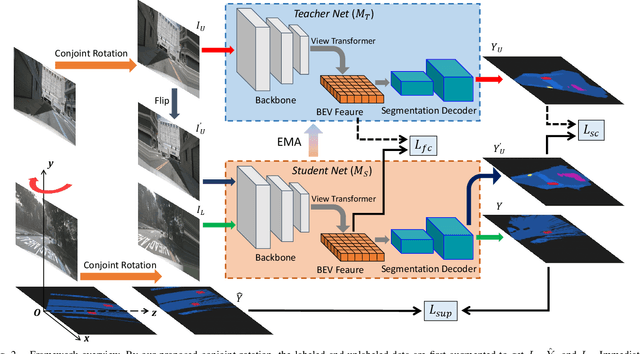
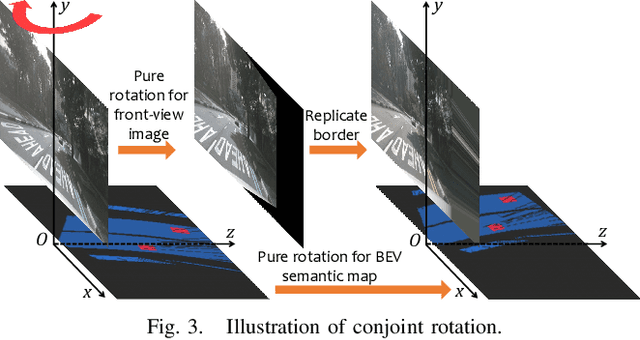
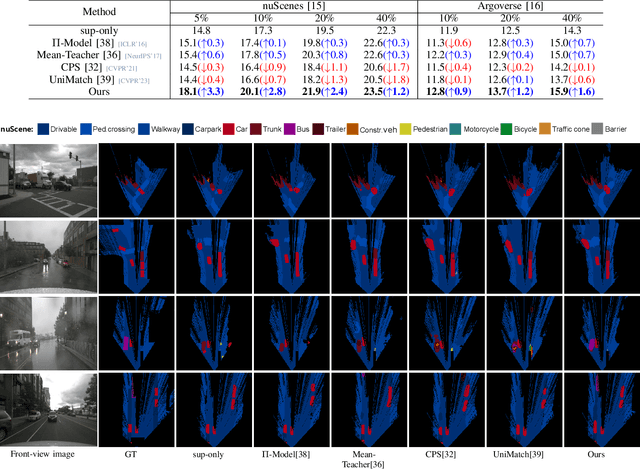
Visual bird's eye view (BEV) semantic segmentation helps autonomous vehicles understand the surrounding environment only from images, including static elements (e.g., roads) and dynamic elements (e.g., vehicles, pedestrians). However, the high cost of annotation procedures of full-supervised methods limits the capability of the visual BEV semantic segmentation, which usually needs HD maps, 3D object bounding boxes, and camera extrinsic matrixes. In this paper, we present a novel semi-supervised framework for visual BEV semantic segmentation to boost performance by exploiting unlabeled images during the training. A consistency loss that makes full use of unlabeled data is then proposed to constrain the model on not only semantic prediction but also the BEV feature. Furthermore, we propose a novel and effective data augmentation method named conjoint rotation which reasonably augments the dataset while maintaining the geometric relationship between the front-view images and the BEV semantic segmentation. Extensive experiments on the nuScenes and Argoverse datasets show that our semi-supervised framework can effectively improve prediction accuracy. To the best of our knowledge, this is the first work that explores improving visual BEV semantic segmentation performance using unlabeled data. The code will be publicly available.