 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Adversarial Quantization
Paper and Code



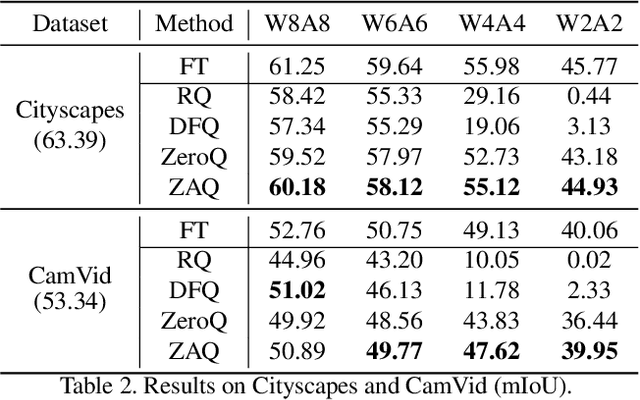
Model quantization is a promising approach to compress deep neural networks and accelerate inference, making it possible to be deployed on mobile and edge devices. To retain the high performance of full-precision models, most existing quantization methods focus on fine-tuning quantized model by assuming training datasets are accessible. However, this assumption sometimes is not satisfied in real situations due to data privacy and security issues, thereby making these quantization methods not applicable. To achieve zero-short model quantization without accessing training data, a tiny number of quantization methods adopt either post-training quantization or batch normalization statistics-guided data generation for fine-tuning. However, both of them inevitably suffer from low performance, since the former is a little too empirical and lacks training support for ultra-low precision quantization, while the latter could not fully restore the peculiarities of original data and is often low efficient for diverse data generation. To address the above issues, we propose a zero-shot adversarial quantization (ZAQ) framework, facilitating effective discrepancy estimation and knowledge transfer from a full-precision model to its quantized model. This is achieved by a novel two-level discrepancy modeling to drive a generator to synthesize informative and diverse data examples to optimize the quantized model in an adversarial learning fashion. We conduct extensive experiments on three fundamental vision tasks, demonstrating the superiority of ZAQ over the strong zero-shot baselines and validating the effectiveness of its main components. Code is available at <https://git.io/Jqc0y>.