 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE-SAT: Speech and Text Joint Pretraining for Cross-Lingual Multi-Speaker Text-to-Speech
Nov 07, 2022



Speech representation learning has improved both speech understanding and speech synthesis tasks for single language. However, its ability in cross-lingual scenarios has not been explored. In this paper, we extend the pretraining method for cross-lingual multi-speaker speech synthesis tasks, including cross-lingual multi-speaker voice cloning and cross-lingual multi-speaker speech editing. We propose a speech-text joint pretraining framework, where we randomly mask the spectrogram and the phonemes given a speech example and its transcription. By learning to reconstruct the masked parts of the input in different languages, our model shows great improvements over speaker-embedding-based multi-speaker TTS methods. Moreover, our framework is end-to-end for both the training and the inference without any finetuning effort. In cross-lingual multi-speaker voice cloning and cross-lingual multi-speaker speech editing tasks, our experiments show that our model outperforms speaker-embedding-based multi-speaker TTS methods. The code and model are publicly available at PaddleSpeech.
PaddleSpeech: An Easy-to-Use All-in-One Speech Toolkit
May 20, 2022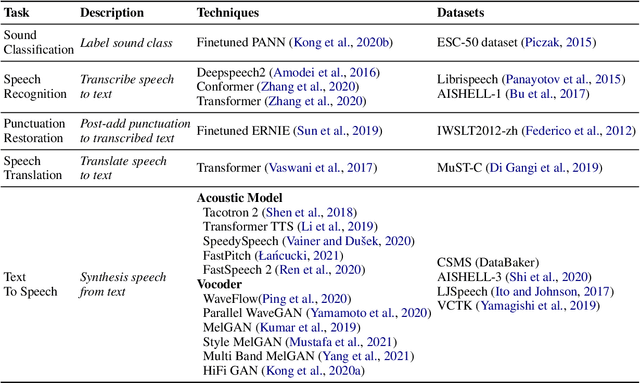
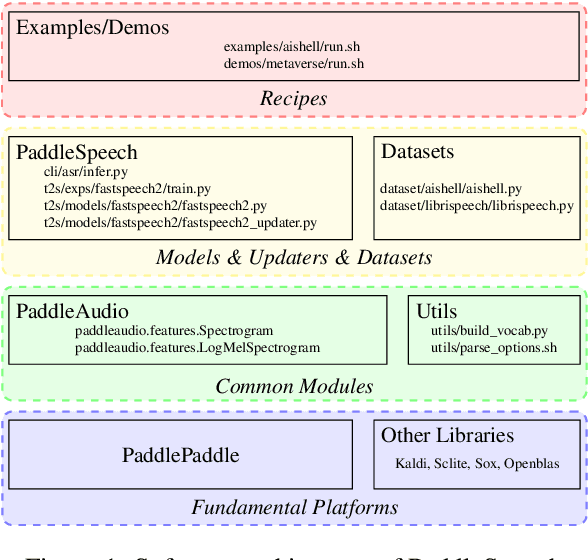
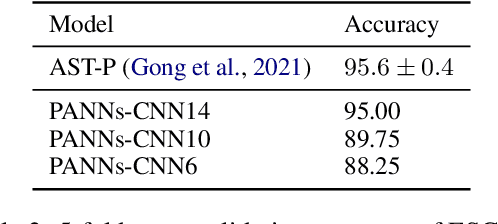
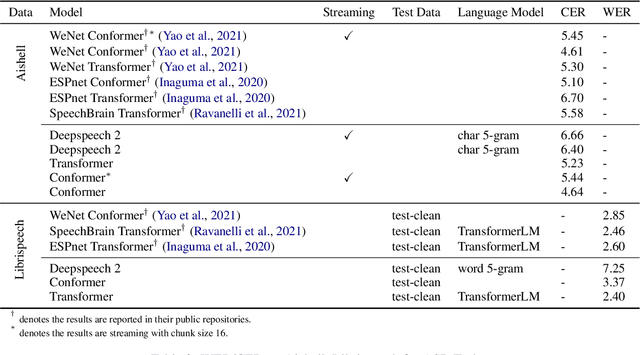
PaddleSpeech is an open-source all-in-one speech toolkit. It aims at facilitating the development and research of speech processing technologies by providing an easy-to-use command-line interface and a simple code structure. This paper describes the design philosophy and core architecture of PaddleSpeech to support several essential speech-to-text and text-to-speech tasks. PaddleSpeech achieves competitive or state-of-the-art performance on various speech datasets and implements the most popular methods. It also provides recipes and pretrained models to quickly reproduce the experimental results in this paper. PaddleSpeech is publicly avaiable at https://github.com/PaddlePaddle/PaddleSpeech.