 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePP-Matting: High-Accuracy Natural Image Matting
Apr 20, 2022
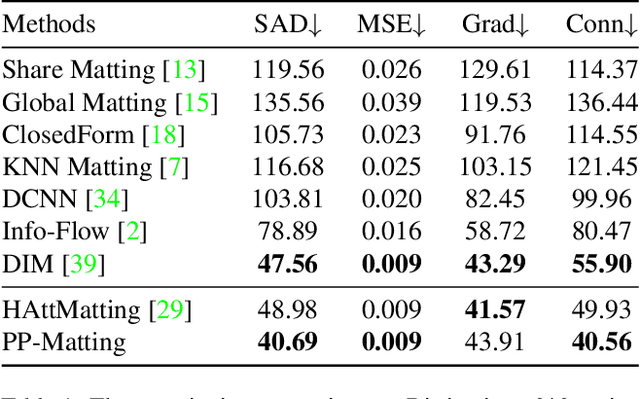
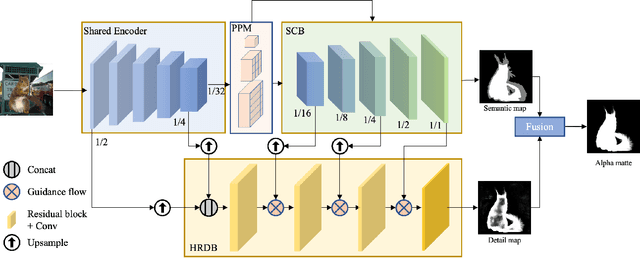
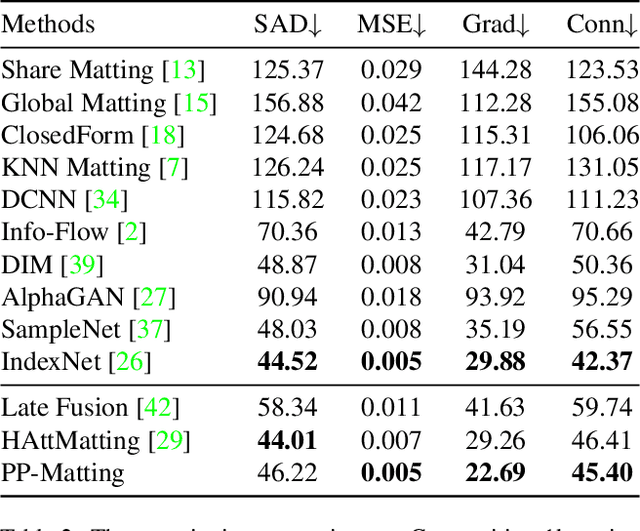
Natural image matting is a fundamental and challenging computer vision task. It has many applications in image editing and composition. Recently, deep learning-based approaches have achieved great improvements in image matting. However, most of them require a user-supplied trimap as an auxiliary input, which limits the matting applications in the real world. Although some trimap-free approaches have been proposed, the matting quality is still unsatisfactory compared to trimap-based ones. Without the trimap guidance, the matting models suffer from foreground-background ambiguity easily, and also generate blurry details in the transition area. In this work, we propose PP-Matting, a trimap-free architecture that can achieve high-accuracy natural image matting. Our method applies a high-resolution detail branch (HRDB) that extracts fine-grained details of the foreground with keeping feature resolution unchanged. Also, we propose a semantic context branch (SCB) that adopts a semantic segmentation subtask. It prevents the detail prediction from local ambiguity caused by semantic context missing. In addition, we conduct extensive experiments on two well-known benchmarks: Composition-1k and Distinctions-646. The results demonstrate the superiority of PP-Matting over previous methods. Furthermore, we provide a qualitative evaluation of our method on human matting which shows its outstanding performance in the practical application. The code and pre-trained models will be available at PaddleSeg: https://github.com/PaddlePaddle/PaddleSeg.
PP-LiteSeg: A Superior Real-Time Semantic Segmentation Model
Apr 06, 2022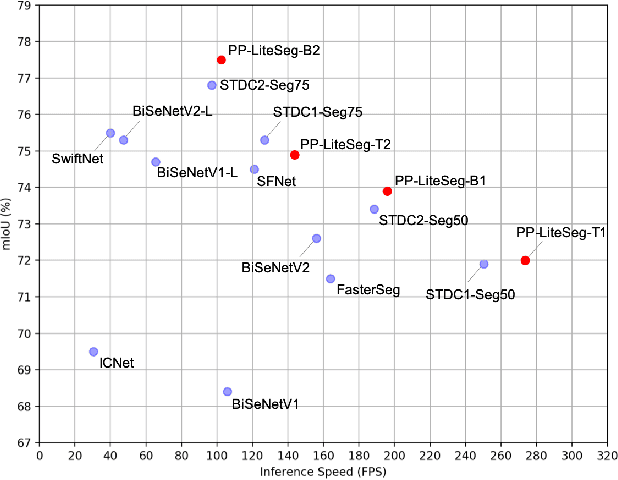

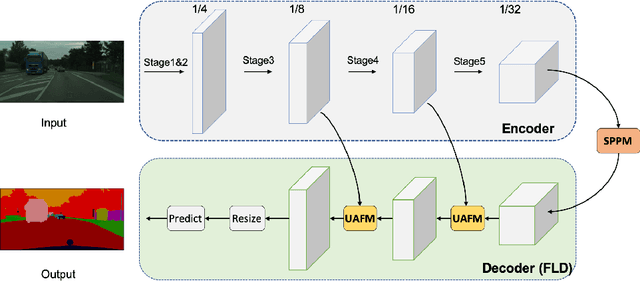
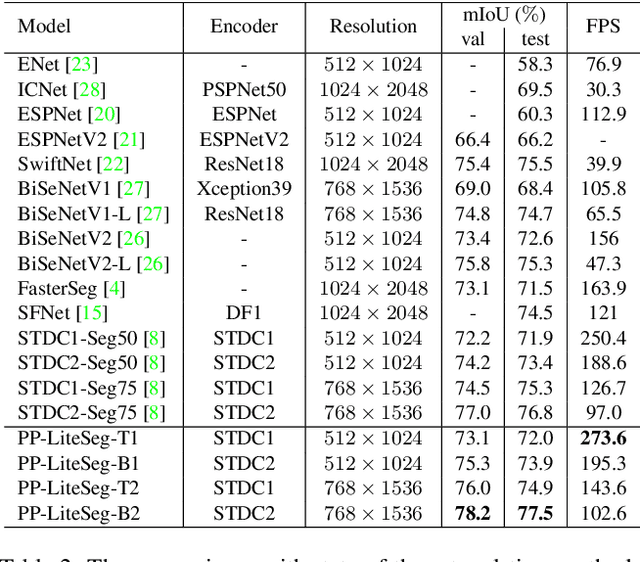
Real-world applications have high demands for semantic segmentation methods. Although semantic segmentation has made remarkable leap-forwards with deep learning, the performance of real-time methods is not satisfactory. In this work, we propose PP-LiteSeg, a novel lightweight model for the real-time semantic segmentation task. Specifically, we present a Flexible and Lightweight Decoder (FLD) to reduce computation overhead of previous decoder. To strengthen feature representations, we propose a Unified Attention Fusion Module (UAFM), which takes advantage of spatial and channel attention to produce a weight and then fuses the input features with the weight. Moreover, a Simple Pyramid Pooling Module (SPPM) is proposed to aggregate global context with low computation cost. Extensive evaluations demonstrate that PP-LiteSeg achieves a superior trade-off between accuracy and speed compared to other methods. On the Cityscapes test set, PP-LiteSeg achieves 72.0% mIoU/273.6 FPS and 77.5% mIoU/102.6 FPS on NVIDIA GTX 1080Ti. Source code and models are available at PaddleSeg: https://github.com/PaddlePaddle/PaddleSeg.
PP-HumanSeg: Connectivity-Aware Portrait Segmentation with a Large-Scale Teleconferencing Video Dataset
Dec 14, 2021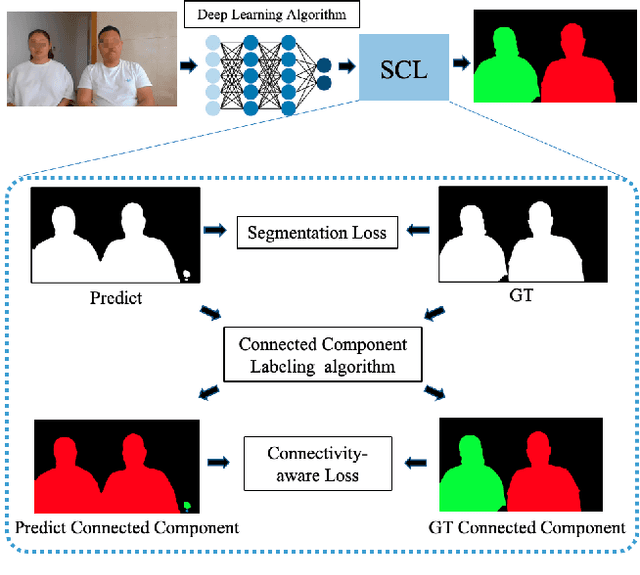


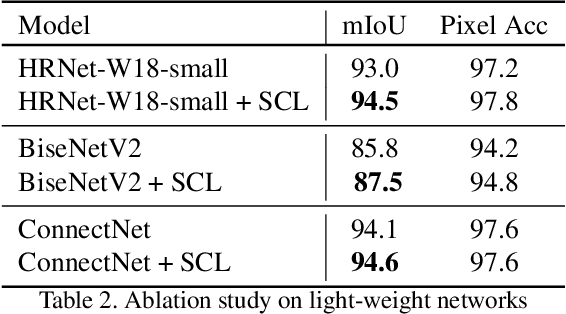
As the COVID-19 pandemic rampages across the world, the demands of video conferencing surge. To this end, real-time portrait segmentation becomes a popular feature to replace backgrounds of conferencing participants. While feature-rich datasets, models and algorithms have been offered for segmentation that extract body postures from life scenes, portrait segmentation has yet not been well covered in a video conferencing context. To facilitate the progress in this field, we introduce an open-source solution named PP-HumanSeg. This work is the first to construct a large-scale video portrait dataset that contains 291 videos from 23 conference scenes with 14K fine-labeled frames and extensions to multi-camera teleconferencing. Furthermore, we propose a novel Semantic Connectivity-aware Learning (SCL) for semantic segmentation, which introduces a semantic connectivity-aware loss to improve the quality of segmentation results from the perspective of connectivity. And we propose an ultra-lightweight model with SCL for practical portrait segmentation, which achieves the best trade-off between IoU and the speed of inference. Extensive evaluations on our dataset demonstrate the superiority of SCL and our model. The source code is available at https://github.com/PaddlePaddle/PaddleSeg.
EdgeFlow: Achieving Practical Interactive Segmentation with Edge-Guided Flow
Sep 20, 2021
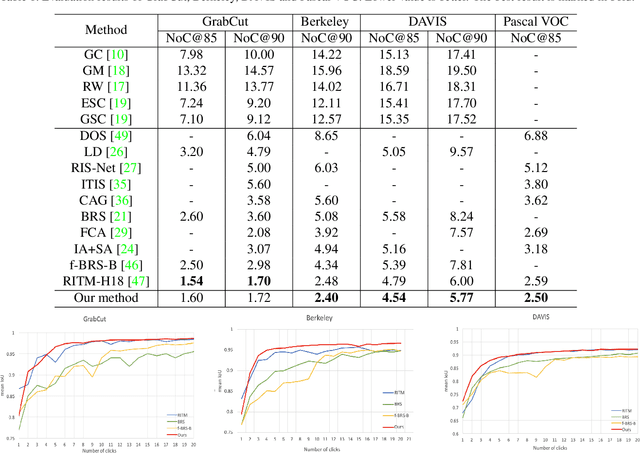
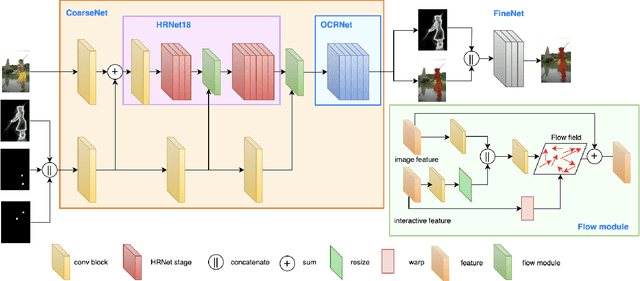

High-quality training data play a key role in image segmentation tasks. Usually, pixel-level annotations are expensive, laborious and time-consuming for the large volume of training data. To reduce labelling cost and improve segmentation quality, interactive segmentation methods have been proposed, which provide the result with just a few clicks. However, their performance does not meet the requirements of practical segmentation tasks in terms of speed and accuracy. In this work, we propose EdgeFlow, a novel architecture that fully utilizes interactive information of user clicks with edge-guided flow. Our method achieves state-of-the-art performance without any post-processing or iterative optimization scheme. Comprehensive experiments on benchmarks also demonstrate the superiority of our method. In addition, with the proposed method, we develop an efficient interactive segmentation tool for practical data annotation tasks. The source code and tool is avaliable at https://github.com/PaddlePaddle/PaddleSeg.