 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePP-HumanSeg: Connectivity-Aware Portrait Segmentation with a Large-Scale Teleconferencing Video Dataset
Paper and Code
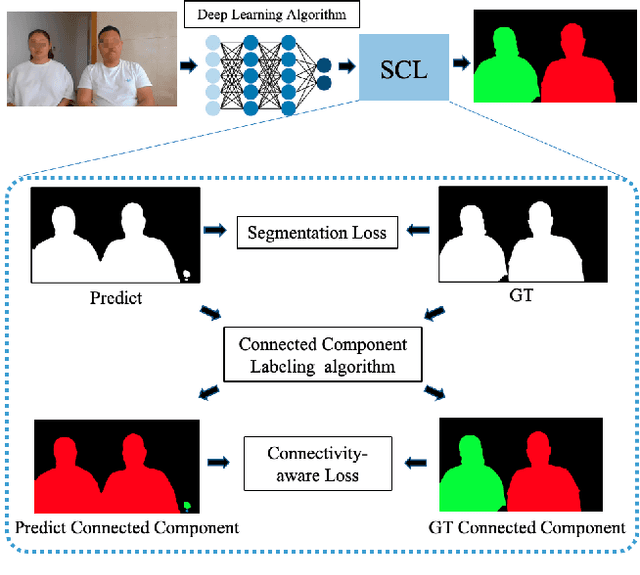


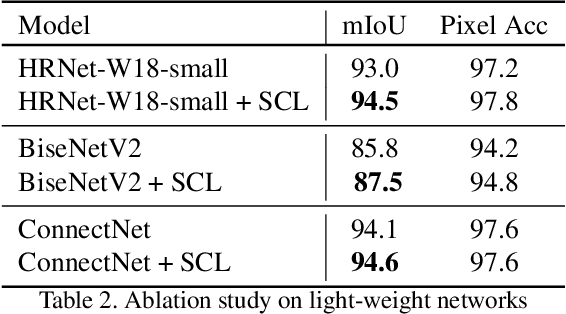
As the COVID-19 pandemic rampages across the world, the demands of video conferencing surge. To this end, real-time portrait segmentation becomes a popular feature to replace backgrounds of conferencing participants. While feature-rich datasets, models and algorithms have been offered for segmentation that extract body postures from life scenes, portrait segmentation has yet not been well covered in a video conferencing context. To facilitate the progress in this field, we introduce an open-source solution named PP-HumanSeg. This work is the first to construct a large-scale video portrait dataset that contains 291 videos from 23 conference scenes with 14K fine-labeled frames and extensions to multi-camera teleconferencing. Furthermore, we propose a novel Semantic Connectivity-aware Learning (SCL) for semantic segmentation, which introduces a semantic connectivity-aware loss to improve the quality of segmentation results from the perspective of connectivity. And we propose an ultra-lightweight model with SCL for practical portrait segmentation, which achieves the best trade-off between IoU and the speed of inference. Extensive evaluations on our dataset demonstrate the superiority of SCL and our model. The source code is available at https://github.com/PaddlePaddle/PaddleSeg.