 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaxoKnow: Taxonomy as Prior Knowledge in the Loss Function of Multi-class Classification
May 24, 2023In this paper, we investigate the effectiveness of integrating a hierarchical taxonomy of labels as prior knowledge into the learning algorithm of a flat classifier. We introduce two methods to integrate the hierarchical taxonomy as an explicit regularizer into the loss function of learning algorithms. By reasoning on a hierarchical taxonomy, a neural network alleviates its output distributions over the classes, allowing conditioning on upper concepts for a minority class. We limit ourselves to the flat classification task and provide our experimental results on two industrial in-house datasets and two public benchmarks, RCV1 and Amazon product reviews. Our obtained results show the significant effect of a taxonomy in increasing the performance of a learner in semisupervised multi-class classification and the considerable results obtained in a fully supervised fashion.
Embracing Limited and Imperfect Data: A Review on Plant Stress Recognition Using Deep Learning
May 19, 2023Plant stress recognition has witnessed significant improvements in recent years with the advent of deep learning. A large-scale and annotated training dataset is required to achieve decent performance; however, collecting it is frequently difficult and expensive. Therefore, deploying current deep learning-based methods in real-world applications may suffer primarily from limited and imperfect data. Embracing them is a promising strategy that has not received sufficient attention. From this perspective, a systematic survey was conducted in this study, with the ultimate objective of monitoring plant growth by implementing deep learning, which frees humans and potentially reduces the resultant losses from plant stress. We believe that our paper has highlighted the importance of embracing this limited and imperfect data and enhanced its relevant understanding.
Bootstrapping Named Entity Recognition in E-Commerce with Positive Unlabeled Learning
May 22, 2020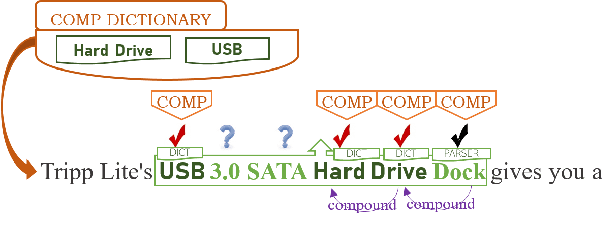
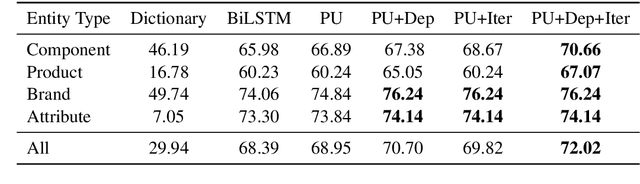
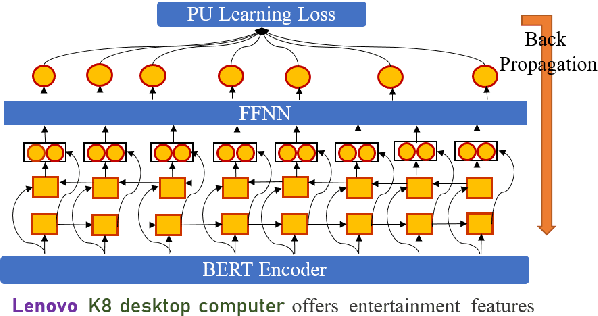
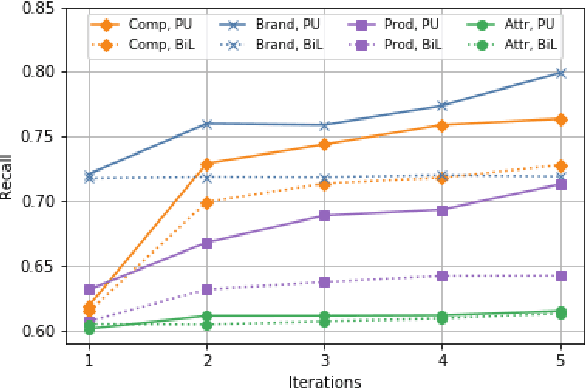
Named Entity Recognition (NER) in domains like e-commerce is an understudied problem due to the lack of annotated datasets. Recognizing novel entity types in this domain, such as products, components, and attributes, is challenging because of their linguistic complexity and the low coverage of existing knowledge resources. To address this problem, we present a bootstrapped positive-unlabeled learning algorithm that integrates domain-specific linguistic features to quickly and efficiently expand the seed dictionary. The model achieves an average F1 score of 72.02% on a novel dataset of product descriptions, an improvement of 3.63% over a baseline BiLSTM classifier, and in particular exhibits better recall (4.96% on average).
FeederGAN: Synthetic Feeder Generation via Deep Graph Adversarial Nets
Apr 03, 2020

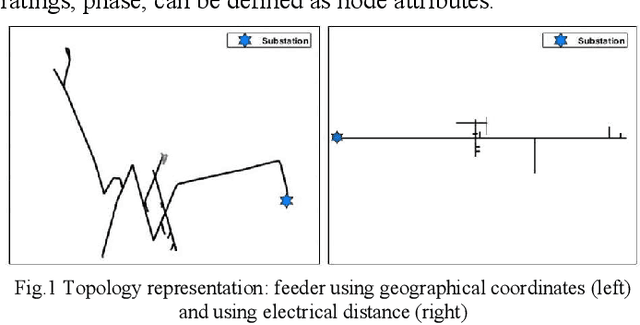

This paper presents a novel, automated, generative adversarial networks (GAN) based synthetic feeder generation mechanism, abbreviated as FeederGAN. FeederGAN digests real feeder models represented by directed graphs via a deep learning framework powered by GAN and graph convolutional networks (GCN). From power system feeder model input files, device connectivity is mapped to the adjacency matrix while device characteristics such as circuit types (i.e., 3-phase, 2-phase, and 1-phase) and component attributes (e.g., length and current ratings) are mapped to the attribute matrix. Then, Wasserstein distance is used to optimize the GAN and GCN is used to discriminate the generated graph from the actual. A greedy method based on graph theory is developed to reconstruct the feeder from the generated adjacency and attribute matrix. Our results show that the generated feeders resemble the actual feeder in both topology and attributes verified by visual inspection and by empirical statistics obtained from actual distribution feeders.
A Feature-based Classification Technique for Answering Multi-choice World History Questions
May 05, 2015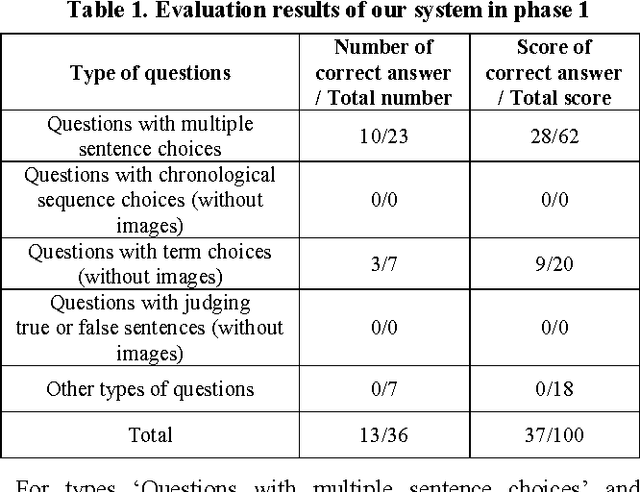
Our FRDC_QA team participated in the QA-Lab English subtask of the NTCIR-11. In this paper, we describe our system for solving real-world university entrance exam questions, which are related to world history. Wikipedia is used as the main external resource for our system. Since problems with choosing right/wrong sentence from multiple sentence choices account for about two-thirds of the total, we individually design a classification based model for solving this type of questions. For other types of questions, we also design some simple methods.
Detecting Concept-level Emotion Cause in Microblogging
Apr 30, 2015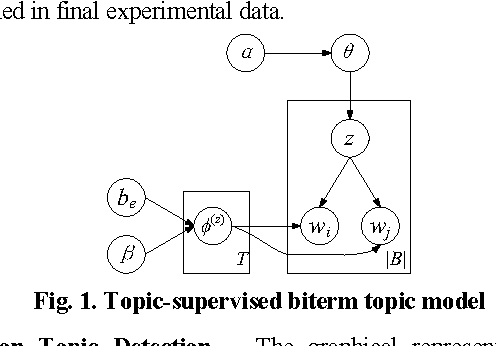
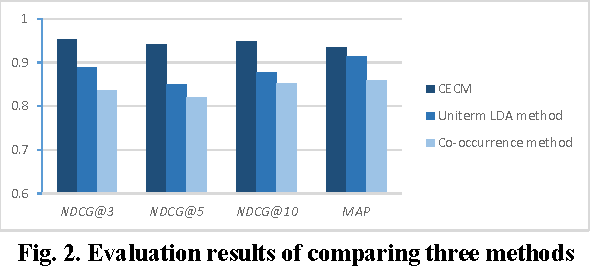

In this paper, we propose a Concept-level Emotion Cause Model (CECM), instead of the mere word-level models, to discover causes of microblogging users' diversified emotions on specific hot event. A modified topic-supervised biterm topic model is utilized in CECM to detect emotion topics' in event-related tweets, and then context-sensitive topical PageRank is utilized to detect meaningful multiword expressions as emotion causes. Experimental results on a dataset from Sina Weibo, one of the largest microblogging websites in China, show CECM can better detect emotion causes than baseline methods.