 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT5-SR: A Unified Seq-to-Seq Decoding Strategy for Semantic Parsing
Jun 14, 2023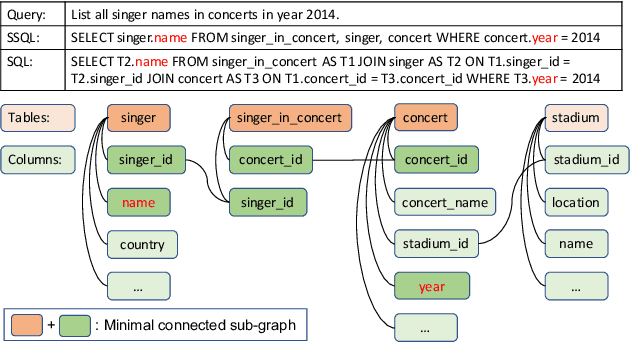

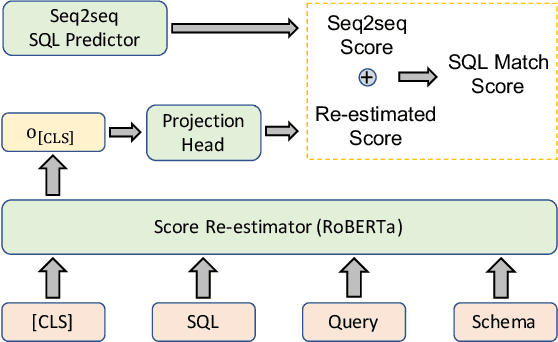

Translating natural language queries into SQLs in a seq2seq manner has attracted much attention recently. However, compared with abstract-syntactic-tree-based SQL generation, seq2seq semantic parsers face much more challenges, including poor quality on schematical information prediction and poor semantic coherence between natural language queries and SQLs. This paper analyses the above difficulties and proposes a seq2seq-oriented decoding strategy called SR, which includes a new intermediate representation SSQL and a reranking method with score re-estimator to solve the above obstacles respectively. Experimental results demonstrate the effectiveness of our proposed techniques and T5-SR-3b achieves new state-of-the-art results on the Spider dataset.
Pay More Attention to History: A Context Modeling Strategy for Conversational Text-to-SQL
Dec 16, 2021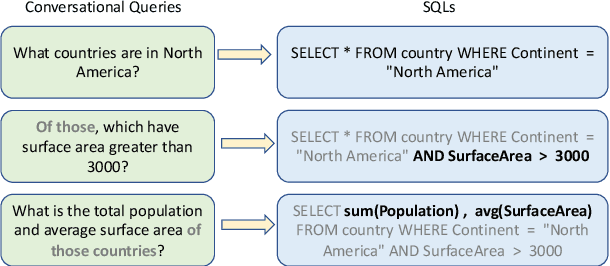
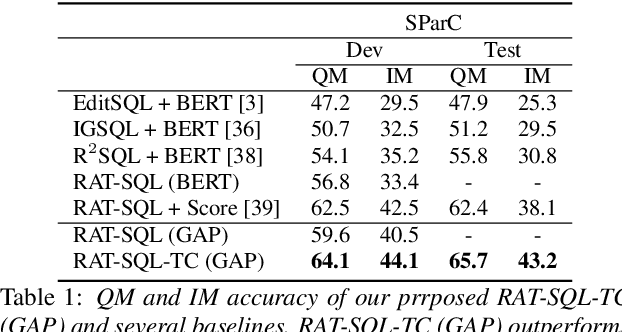
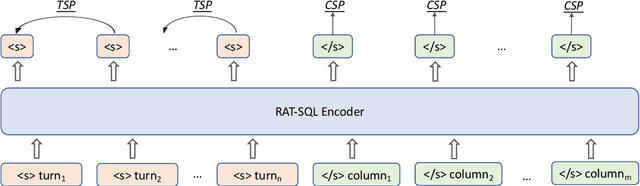
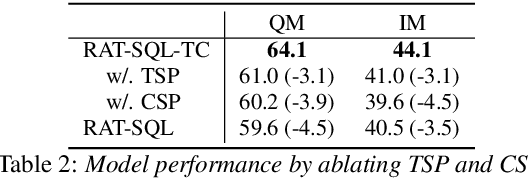
Conversational text-to-SQL aims at converting multi-turn natural language queries into their corresponding SQL representations. One of the most intractable problem of conversational text-to-SQL is modeling the semantics of multi-turn queries and gathering proper information required for the current query. This paper shows that explicit modeling the semantic changes by adding each turn and the summarization of the whole context can bring better performance on converting conversational queries into SQLs. In particular, we propose two conversational modeling tasks in both turn grain and conversation grain. These two tasks simply work as auxiliary training tasks to help with multi-turn conversational semantic parsing. We conducted empirical studies and achieve new state-of-the-art results on large-scale open-domain conversational text-to-SQL dataset. The results demonstrate that the proposed mechanism significantly improves the performance of multi-turn semantic parsing.
Bootstrapping Named Entity Recognition in E-Commerce with Positive Unlabeled Learning
May 22, 2020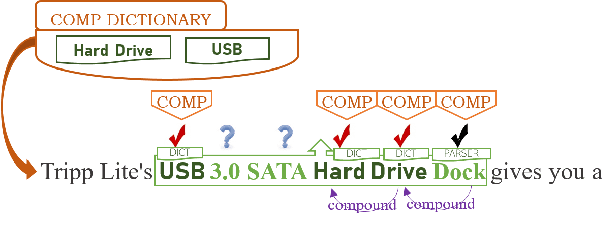
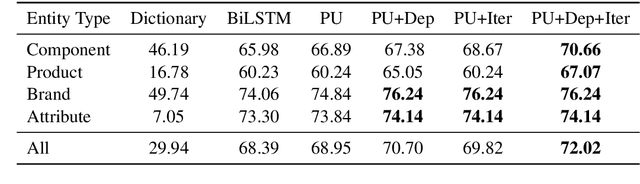
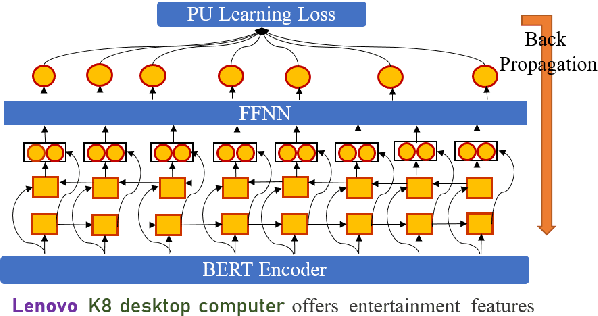
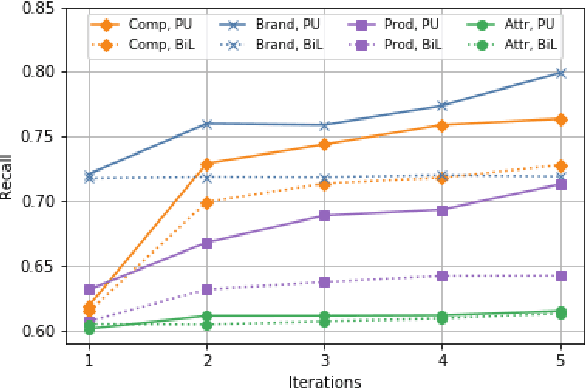
Named Entity Recognition (NER) in domains like e-commerce is an understudied problem due to the lack of annotated datasets. Recognizing novel entity types in this domain, such as products, components, and attributes, is challenging because of their linguistic complexity and the low coverage of existing knowledge resources. To address this problem, we present a bootstrapped positive-unlabeled learning algorithm that integrates domain-specific linguistic features to quickly and efficiently expand the seed dictionary. The model achieves an average F1 score of 72.02% on a novel dataset of product descriptions, an improvement of 3.63% over a baseline BiLSTM classifier, and in particular exhibits better recall (4.96% on average).