 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero2Text: Zero-Training Cross-Domain Inversion Attacks on Textual Embeddings
Feb 03, 2026The proliferation of retrieval-augmented generation (RAG) has established vector databases as critical infrastructure, yet they introduce severe privacy risks via embedding inversion attacks. Existing paradigms face a fundamental trade-off: optimization-based methods require computationally prohibitive queries, while alignment-based approaches hinge on the unrealistic assumption of accessible in-domain training data. These constraints render them ineffective in strict black-box and cross-domain settings. To dismantle these barriers, we introduce Zero2Text, a novel training-free framework based on recursive online alignment. Unlike methods relying on static datasets, Zero2Text synergizes LLM priors with a dynamic ridge regression mechanism to iteratively align generation to the target embedding on-the-fly. We further demonstrate that standard defenses, such as differential privacy, fail to effectively mitigate this adaptive threat. Extensive experiments across diverse benchmarks validate Zero2Text; notably, on MS MARCO against the OpenAI victim model, it achieves 1.8x higher ROUGE-L and 6.4x higher BLEU-2 scores compared to baselines, recovering sentences from unknown domains without a single leaked data pair.
Diffusion-based Decentralized Federated Multi-Task Representation Learning
Dec 29, 2025Representation learning is a widely adopted framework for learning in data-scarce environments to obtain a feature extractor or representation from various different yet related tasks. Despite extensive research on representation learning, decentralized approaches remain relatively underexplored. This work develops a decentralized projected gradient descent-based algorithm for multi-task representation learning. We focus on the problem of multi-task linear regression in which multiple linear regression models share a common, low-dimensional linear representation. We present an alternating projected gradient descent and minimization algorithm for recovering a low-rank feature matrix in a diffusion-based decentralized and federated fashion. We obtain constructive, provable guarantees that provide a lower bound on the required sample complexity and an upper bound on the iteration complexity of our proposed algorithm. We analyze the time and communication complexity of our algorithm and show that it is fast and communication-efficient. We performed numerical simulations to validate the performance of our algorithm and compared it with benchmark algorithms.
Beyond Centralization: Provable Communication Efficient Decentralized Multi-Task Learning
Dec 27, 2025Representation learning is a widely adopted framework for learning in data-scarce environments, aiming to extract common features from related tasks. While centralized approaches have been extensively studied, decentralized methods remain largely underexplored. We study decentralized multi-task representation learning in which the features share a low-rank structure. We consider multiple tasks, each with a finite number of data samples, where the observations follow a linear model with task-specific parameters. In the decentralized setting, task data are distributed across multiple nodes, and information exchange between nodes is constrained by a communication network. The goal is to recover the underlying feature matrix whose rank is much smaller than both the parameter dimension and the number of tasks. We propose a new alternating projected gradient and minimization algorithm with provable accuracy guarantees. We provide comprehensive characterizations of the time, communication, and sample complexities. Importantly, the communication complexity is independent of the target accuracy, which significantly reduces communication cost compared to prior methods. Numerical simulations validate the theoretical analysis across different dimensions and network topologies, and demonstrate regimes in which decentralized learning outperforms centralized federated approaches.
CF-DETR: Coarse-to-Fine Transformer for Real-Time Object Detection
May 29, 2025Detection Transformers (DETR) are increasingly adopted in autonomous vehicle (AV) perception systems due to their superior accuracy over convolutional networks. However, concurrently executing multiple DETR tasks presents significant challenges in meeting firm real-time deadlines (R1) and high accuracy requirements (R2), particularly for safety-critical objects, while navigating the inherent latency-accuracy trade-off under resource constraints. Existing real-time DNN scheduling approaches often treat models generically, failing to leverage Transformer-specific properties for efficient resource allocation. To address these challenges, we propose CF-DETR, an integrated system featuring a novel coarse-to-fine Transformer architecture and a dedicated real-time scheduling framework NPFP**. CF-DETR employs three key strategies (A1: coarse-to-fine inference, A2: selective fine inference, A3: multi-level batch inference) that exploit Transformer properties to dynamically adjust patch granularity and attention scope based on object criticality, aiming to satisfy R2. The NPFP** scheduling framework (A4) orchestrates these adaptive mechanisms A1-A3. It partitions each DETR task into a safety-critical coarse subtask for guaranteed critical object detection within its deadline (ensuring R1), and an optional fine subtask for enhanced overall accuracy (R2), while managing individual and batched execution. Our extensive evaluations on server, GPU-enabled embedded platforms, and actual AV platforms demonstrate that CF-DETR, under an NPFP** policy, successfully meets strict timing guarantees for critical operations and achieves significantly higher overall and critical object detection accuracy compared to existing baselines across diverse AV workloads.
Real Time Scheduling Framework for Multi Object Detection via Spiking Neural Networks
Jan 29, 2025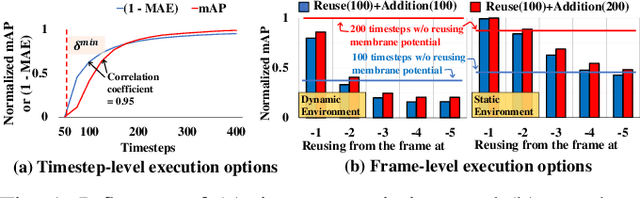
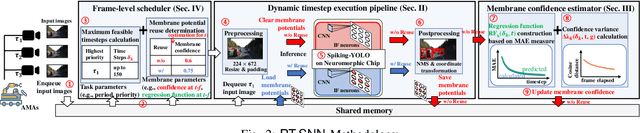

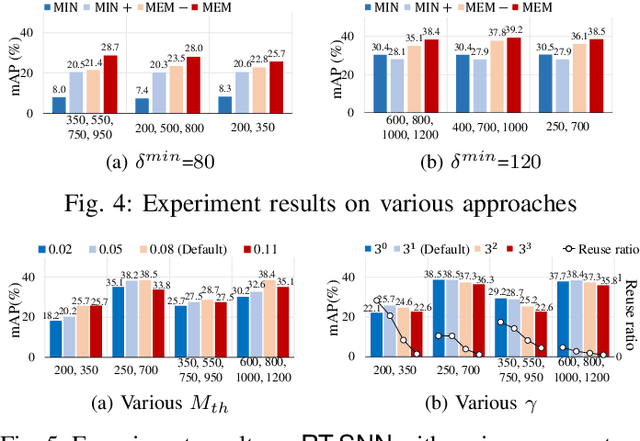
Given the energy constraints in autonomous mobile agents (AMAs), such as unmanned vehicles, spiking neural networks (SNNs) are increasingly favored as a more efficient alternative to traditional artificial neural networks. AMAs employ multi-object detection (MOD) from multiple cameras to identify nearby objects while ensuring two essential objectives, (R1) timing guarantee and (R2) high accuracy for safety. In this paper, we propose RT-SNN, the first system design, aiming at achieving R1 and R2 in SNN-based MOD systems on AMAs. Leveraging the characteristic that SNNs gather feature data of input image termed as membrane potential, through iterative computation over multiple timesteps, RT-SNN provides multiple execution options with adjustable timesteps and a novel method for reusing membrane potential to support R1. Then, it captures how these execution strategies influence R2 by introducing a novel notion of mean absolute error and membrane confidence. Further, RT-SNN develops a new scheduling framework consisting of offline schedulability analysis for R1 and a run-time scheduling algorithm for R2 using the notion of membrane confidence. We deployed RT-SNN to Spiking-YOLO, the SNN-based MOD model derived from ANN-to-SNN conversion, and our experimental evaluation confirms its effectiveness in meeting the R1 and R2 requirements while providing significant energy efficiency.
BankTweak: Adversarial Attack against Multi-Object Trackers by Manipulating Feature Banks
Aug 22, 2024



Multi-object tracking (MOT) aims to construct moving trajectories for objects, and modern multi-object trackers mainly utilize the tracking-by-detection methodology. Initial approaches to MOT attacks primarily aimed to degrade the detection quality of the frames under attack, thereby reducing accuracy only in those specific frames, highlighting a lack of \textit{efficiency}. To improve efficiency, recent advancements manipulate object positions to cause persistent identity (ID) switches during the association phase, even after the attack ends within a few frames. However, these position-manipulating attacks have inherent limitations, as they can be easily counteracted by adjusting distance-related parameters in the association phase, revealing a lack of \textit{robustness}. In this paper, we present \textsf{BankTweak}, a novel adversarial attack designed for MOT trackers, which features efficiency and robustness. \textsf{BankTweak} focuses on the feature extractor in the association phase and reveals vulnerability in the Hungarian matching method used by feature-based MOT systems. Exploiting the vulnerability, \textsf{BankTweak} induces persistent ID switches (addressing \textit{efficiency}) even after the attack ends by strategically injecting altered features into the feature banks without modifying object positions (addressing \textit{robustness}). To demonstrate the applicability, we apply \textsf{BankTweak} to three multi-object trackers (DeepSORT, StrongSORT, and MOTDT) with one-stage, two-stage, anchor-free, and transformer detectors. Extensive experiments on the MOT17 and MOT20 datasets show that our method substantially surpasses existing attacks, exposing the vulnerability of the tracking-by-detection framework to \textsf{BankTweak}.
AT-SNN: Adaptive Tokens for Vision Transformer on Spiking Neural Network
Aug 22, 2024



In the training and inference of spiking neural networks (SNNs), direct training and lightweight computation methods have been orthogonally developed, aimed at reducing power consumption. However, only a limited number of approaches have applied these two mechanisms simultaneously and failed to fully leverage the advantages of SNN-based vision transformers (ViTs) since they were originally designed for convolutional neural networks (CNNs). In this paper, we propose AT-SNN designed to dynamically adjust the number of tokens processed during inference in SNN-based ViTs with direct training, wherein power consumption is proportional to the number of tokens. We first demonstrate the applicability of adaptive computation time (ACT), previously limited to RNNs and ViTs, to SNN-based ViTs, enhancing it to discard less informative spatial tokens selectively. Also, we propose a new token-merge mechanism that relies on the similarity of tokens, which further reduces the number of tokens while enhancing accuracy. We implement AT-SNN to Spikformer and show the effectiveness of AT-SNN in achieving high energy efficiency and accuracy compared to state-of-the-art approaches on the image classification tasks, CIFAR10, CIFAR-100, and TinyImageNet. For example, our approach uses up to 42.4% fewer tokens than the existing best-performing method on CIFAR-100, while conserving higher accuracy.