 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstood in Translation, Transformers for Domain Understanding
Paper and Code
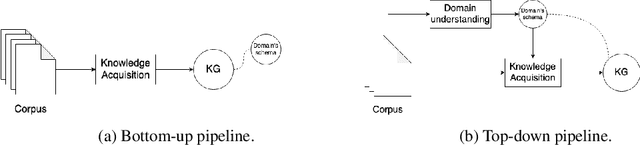


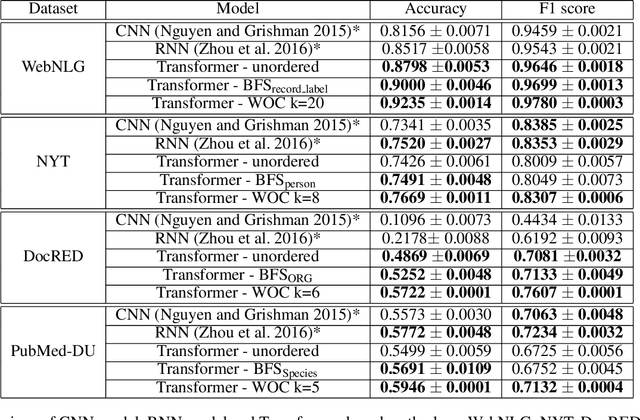
Knowledge acquisition is the essential first step of any Knowledge Graph (KG) application. This knowledge can be extracted from a given corpus (KG generation process) or specified from an existing KG (KG specification process). Focusing on domain specific solutions, knowledge acquisition is a labor intensive task usually orchestrated and supervised by subject matter experts. Specifically, the domain of interest is usually manually defined and then the needed generation or extraction tools are utilized to produce the KG. Herein, we propose a supervised machine learning method, based on Transformers, for domain definition of a corpus. We argue why such automated definition of the domain's structure is beneficial both in terms of construction time and quality of the generated graph. The proposed method is extensively validated on three public datasets (WebNLG, NYT and DocRED) by comparing it with two reference methods based on CNNs and RNNs models. The evaluation shows the efficiency of our model in this task. Focusing on scientific document understanding, we present a new health domain dataset based on publications extracted from PubMed and we successfully utilize our method on this. Lastly, we demonstrate how this work lays the foundation for fully automated and unsupervised KG generation.