 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attempt to Develop a Neural Parser based on Simplified Head-Driven Phrase Structure Grammar on Vietnamese
Nov 26, 2024In this paper, we aimed to develop a neural parser for Vietnamese based on simplified Head-Driven Phrase Structure Grammar (HPSG). The existing corpora, VietTreebank and VnDT, had around 15% of constituency and dependency tree pairs that did not adhere to simplified HPSG rules. To attempt to address the issue of the corpora not adhering to simplified HPSG rules, we randomly permuted samples from the training and development sets to make them compliant with simplified HPSG. We then modified the first simplified HPSG Neural Parser for the Penn Treebank by replacing it with the PhoBERT or XLM-RoBERTa models, which can encode Vietnamese texts. We conducted experiments on our modified VietTreebank and VnDT corpora. Our extensive experiments showed that the simplified HPSG Neural Parser achieved a new state-of-the-art F-score of 82% for constituency parsing when using the same predicted part-of-speech (POS) tags as the self-attentive constituency parser. Additionally, it outperformed previous studies in dependency parsing with a higher Unlabeled Attachment Score (UAS). However, our parser obtained lower Labeled Attachment Score (LAS) scores likely due to our focus on arc permutation without changing the original labels, as we did not consult with a linguistic expert. Lastly, the research findings of this paper suggest that simplified HPSG should be given more attention to linguistic expert when developing treebanks for Vietnamese natural language processing.
Are Anomaly Scores Telling the Whole Story? A Benchmark for Multilevel Anomaly Detection
Nov 21, 2024



Anomaly detection (AD) is a machine learning task that identifies anomalies by learning patterns from normal training data. In many real-world scenarios, anomalies vary in severity, from minor anomalies with little risk to severe abnormalities requiring immediate attention. However, existing models primarily operate in a binary setting, and the anomaly scores they produce are usually based on the deviation of data points from normal data, which may not accurately reflect practical severity. In this paper, we address this gap by making three key contributions. First, we propose a novel setting, Multilevel AD (MAD), in which the anomaly score represents the severity of anomalies in real-world applications, and we highlight its diverse applications across various domains. Second, we introduce a novel benchmark, MAD-Bench, that evaluates models not only on their ability to detect anomalies, but also on how effectively their anomaly scores reflect severity. This benchmark incorporates multiple types of baselines and real-world applications involving severity. Finally, we conduct a comprehensive performance analysis on MAD-Bench. We evaluate models on their ability to assign severity-aligned scores, investigate the correspondence between their performance on binary and multilevel detection, and study their robustness. This analysis offers key insights into improving AD models for practical severity alignment. The code framework and datasets used for the benchmark will be made publicly available.
ViSoBERT: A Pre-Trained Language Model for Vietnamese Social Media Text Processing
Oct 28, 2023
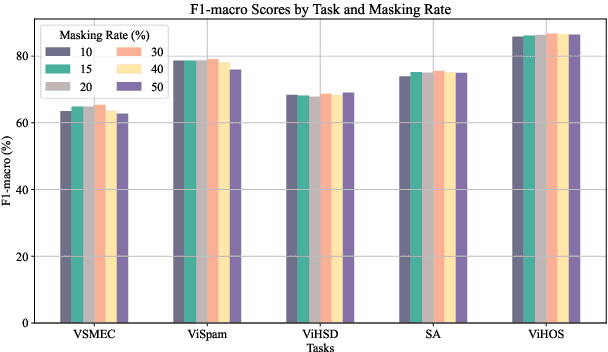

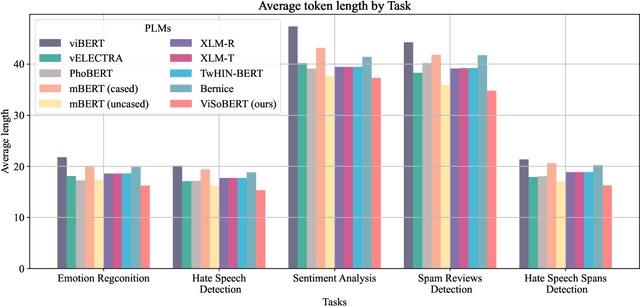
English and Chinese, known as resource-rich languages, have witnessed the strong development of transformer-based language models for natural language processing tasks. Although Vietnam has approximately 100M people speaking Vietnamese, several pre-trained models, e.g., PhoBERT, ViBERT, and vELECTRA, performed well on general Vietnamese NLP tasks, including POS tagging and named entity recognition. These pre-trained language models are still limited to Vietnamese social media tasks. In this paper, we present the first monolingual pre-trained language model for Vietnamese social media texts, ViSoBERT, which is pre-trained on a large-scale corpus of high-quality and diverse Vietnamese social media texts using XLM-R architecture. Moreover, we explored our pre-trained model on five important natural language downstream tasks on Vietnamese social media texts: emotion recognition, hate speech detection, sentiment analysis, spam reviews detection, and hate speech spans detection. Our experiments demonstrate that ViSoBERT, with far fewer parameters, surpasses the previous state-of-the-art models on multiple Vietnamese social media tasks. Our ViSoBERT model is available only for research purposes.
Evaluating the Symbol Binding Ability of Large Language Models for Multiple-Choice Questions in Vietnamese General Education
Oct 23, 2023



In this paper, we evaluate the ability of large language models (LLMs) to perform multiple choice symbol binding (MCSB) for multiple choice question answering (MCQA) tasks in zero-shot, one-shot, and few-shot settings. We focus on Vietnamese, with fewer challenging MCQA datasets than in English. The two existing datasets, ViMMRC 1.0 and ViMMRC 2.0, focus on literature. Recent research in Vietnamese natural language processing (NLP) has focused on the Vietnamese National High School Graduation Examination (VNHSGE) from 2019 to 2023 to evaluate ChatGPT. However, these studies have mainly focused on how ChatGPT solves the VNHSGE step by step. We aim to create a novel and high-quality dataset by providing structured guidelines for typing LaTeX formulas for mathematics, physics, chemistry, and biology. This dataset can be used to evaluate the MCSB ability of LLMs and smaller language models (LMs) because it is typed in a strict LaTeX style. We focus on predicting the character (A, B, C, or D) that is the most likely answer to a question, given the context of the question. Our evaluation of six well-known LLMs, namely BLOOMZ-7.1B-MT, LLaMA-2-7B, LLaMA-2-70B, GPT-3, GPT-3.5, and GPT-4.0, on the ViMMRC 1.0 and ViMMRC 2.0 benchmarks and our proposed dataset shows promising results on the MCSB ability of LLMs for Vietnamese. The dataset is available for research purposes only.
ViCGCN: Graph Convolutional Network with Contextualized Language Models for Social Media Mining in Vietnamese
Sep 06, 2023Social media processing is a fundamental task in natural language processing with numerous applications. As Vietnamese social media and information science have grown rapidly, the necessity of information-based mining on Vietnamese social media has become crucial. However, state-of-the-art research faces several significant drawbacks, including imbalanced data and noisy data on social media platforms. Imbalanced and noisy are two essential issues that need to be addressed in Vietnamese social media texts. Graph Convolutional Networks can address the problems of imbalanced and noisy data in text classification on social media by taking advantage of the graph structure of the data. This study presents a novel approach based on contextualized language model (PhoBERT) and graph-based method (Graph Convolutional Networks). In particular, the proposed approach, ViCGCN, jointly trained the power of Contextualized embeddings with the ability of Graph Convolutional Networks, GCN, to capture more syntactic and semantic dependencies to address those drawbacks. Extensive experiments on various Vietnamese benchmark datasets were conducted to verify our approach. The observation shows that applying GCN to BERTology models as the final layer significantly improves performance. Moreover, the experiments demonstrate that ViCGCN outperforms 13 powerful baseline models, including BERTology models, fusion BERTology and GCN models, other baselines, and SOTA on three benchmark social media datasets. Our proposed ViCGCN approach demonstrates a significant improvement of up to 6.21%, 4.61%, and 2.63% over the best Contextualized Language Models, including multilingual and monolingual, on three benchmark datasets, UIT-VSMEC, UIT-ViCTSD, and UIT-VSFC, respectively. Additionally, our integrated model ViCGCN achieves the best performance compared to other BERTology integrated with GCN models.
Link Prediction for Wikipedia Articles as a Natural Language Inference Task
Sep 05, 2023Link prediction task is vital to automatically understanding the structure of large knowledge bases. In this paper, we present our system to solve this task at the Data Science and Advanced Analytics 2023 Competition "Efficient and Effective Link Prediction" (DSAA-2023 Competition) with a corpus containing 948,233 training and 238,265 for public testing. This paper introduces an approach to link prediction in Wikipedia articles by formulating it as a natural language inference (NLI) task. Drawing inspiration from recent advancements in natural language processing and understanding, we cast link prediction as an NLI task, wherein the presence of a link between two articles is treated as a premise, and the task is to determine whether this premise holds based on the information presented in the articles. We implemented our system based on the Sentence Pair Classification for Link Prediction for the Wikipedia Articles task. Our system achieved 0.99996 Macro F1-score and 1.00000 Macro F1-score for the public and private test sets, respectively. Our team UIT-NLP ranked 3rd in performance on the private test set, equal to the scores of the first and second places. Our code is publicly for research purposes.