 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
Multimodal Preference Data Synthetic Alignment with Reward Model
Dec 23, 2024
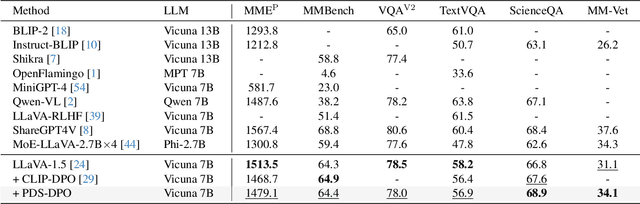
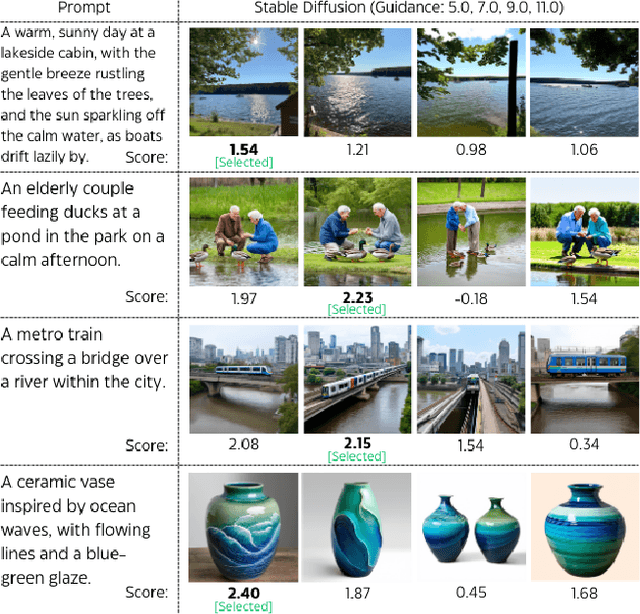

Multimodal large language models (MLLMs) have significantly advanced tasks like caption generation and visual question answering by integrating visual and textual data. However, they sometimes produce misleading or hallucinate content due to discrepancies between their pre-training data and real user prompts. Existing approaches using Direct Preference Optimization (DPO) in vision-language tasks often rely on strong models like GPT-4 or CLIP to determine positive and negative responses. Here, we propose a new framework in generating synthetic data using a reward model as a proxy of human preference for effective multimodal alignment with DPO training. The resulting DPO dataset ranges from 2K to 9K image-text pairs, was evaluated on LLaVA-v1.5-7B, where our approach demonstrated substantial improvements in both the trustworthiness and reasoning capabilities of the base model across multiple hallucination and vision-language benchmark. The experiment results indicate that integrating selected synthetic data, such as from generative and rewards models can effectively reduce reliance on human-annotated data while enhancing MLLMs' alignment capability, offering a scalable solution for safer deployment.
Investigating the Robustness and Properties of Detection Transformers (DETR) Toward Difficult Images
Oct 12, 2023



Transformer-based object detectors (DETR) have shown significant performance across machine vision tasks, ultimately in object detection. This detector is based on a self-attention mechanism along with the transformer encoder-decoder architecture to capture the global context in the image. The critical issue to be addressed is how this model architecture can handle different image nuisances, such as occlusion and adversarial perturbations. We studied this issue by measuring the performance of DETR with different experiments and benchmarking the network with convolutional neural network (CNN) based detectors like YOLO and Faster-RCNN. We found that DETR performs well when it comes to resistance to interference from information loss in occlusion images. Despite that, we found that the adversarial stickers put on the image require the network to produce a new unnecessary set of keys, queries, and values, which in most cases, results in a misdirection of the network. DETR also performed poorer than YOLOv5 in the image corruption benchmark. Furthermore, we found that DETR depends heavily on the main query when making a prediction, which leads to imbalanced contributions between queries since the main query receives most of the gradient flow.