 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaled-up Discovery of Latent Concepts in Deep NLP Models
Paper and Code

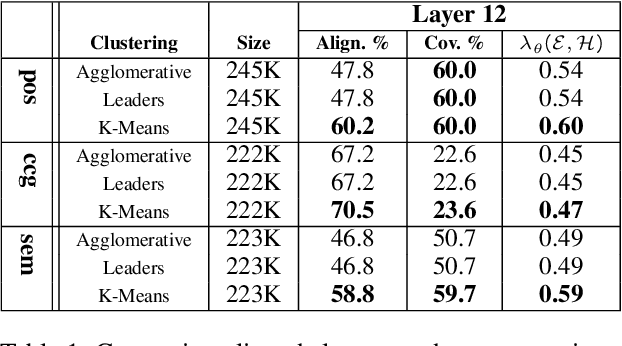

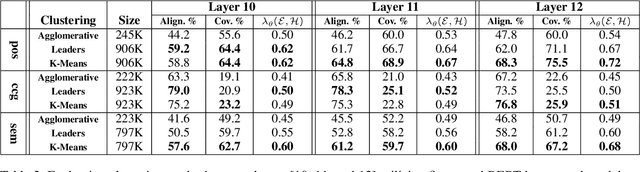
Pre-trained language models (pLMs) learn intricate patterns and contextual dependencies via unsupervised learning on vast text data, driving breakthroughs across NLP tasks. Despite these achievements, these models remain black boxes, necessitating research into understanding their decision-making processes. Recent studies explore representation analysis by clustering latent spaces within pre-trained models. However, these approaches are limited in terms of scalability and the scope of interpretation because of high computation costs of clustering algorithms. This study focuses on comparing clustering algorithms for the purpose of scaling encoded concept discovery of representations from pLMs. Specifically, we compare three algorithms in their capacity to unveil the encoded concepts through their alignment to human-defined ontologies: Agglomerative Hierarchical Clustering, Leaders Algorithm, and K-Means Clustering. Our results show that K-Means has the potential to scale to very large datasets, allowing rich latent concept discovery, both on the word and phrase level.