 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Conversations: Abstract Compression of Conversational Audio Context for LLM-based ASR
Mar 27, 2026Standard LLM-based speech recognition systems typically process utterances in isolation, limiting their ability to leverage conversational context. In this work, we study whether multimodal context from prior turns improves LLM-based ASR and how to represent that context efficiently. We find that, after supervised multi-turn training, conversational context mainly helps with the recognition of contextual entities. However, conditioning on raw context is expensive because the prior-turn audio token sequence grows rapidly with conversation length. To address this, we propose Abstract Compression, which replaces the audio portion of prior turns with a fixed number of learned latent tokens while retaining corresponding transcripts explicitly. On both in-domain and out-of-domain test sets, the compressed model recovers part of the gains of raw-context conditioning with a smaller prior-turn audio footprint. We also provide targeted analyses of the compression setup and its trade-offs.
TidyVoice 2026 Challenge Evaluation Plan
Jan 29, 2026The performance of speaker verification systems degrades significantly under language mismatch, a critical challenge exacerbated by the field's reliance on English-centric data. To address this, we propose the TidyVoice Challenge for cross-lingual speaker verification. The challenge leverages the TidyVoiceX dataset from the novel TidyVoice benchmark, a large-scale, multilingual corpus derived from Mozilla Common Voice, and specifically curated to isolate the effect of language switching across approximately 40 languages. Participants will be tasked with building systems robust to this mismatch, with performance primarily evaluated using the Equal Error Rate on cross-language trials. By providing standardized data, open-source baselines, and a rigorous evaluation protocol, this challenge aims to drive research towards fairer, more inclusive, and language-independent speaker recognition technologies, directly aligning with the Interspeech 2026 theme, "Speaking Together."
Text-only adaptation in LLM-based ASR through text denoising
Jan 28, 2026Adapting automatic speech recognition (ASR) systems based on large language models (LLMs) to new domains using text-only data is a significant yet underexplored challenge. Standard fine-tuning of the LLM on target-domain text often disrupts the critical alignment between speech and text modalities learned by the projector, degrading performance. We introduce a novel text-only adaptation method that emulates the audio projection task by treating it as a text denoising task. Our approach thus trains the LLM to recover clean transcripts from noisy inputs. This process effectively adapts the model to a target domain while preserving cross-modal alignment. Our solution is lightweight, requiring no architectural changes or additional parameters. Extensive evaluation on two datasets demonstrates up to 22.1% relative improvement, outperforming recent state-of-the-art text-only adaptation methods.
Reducing Prompt Sensitivity in LLM-based Speech Recognition Through Learnable Projection
Jan 28, 2026LLM-based automatic speech recognition (ASR), a well-established approach, connects speech foundation models to large language models (LLMs) through a speech-to-LLM projector, yielding promising results. A common design choice in these architectures is the use of a fixed, manually defined prompt during both training and inference. This setup not only enables applicability across a range of practical scenarios, but also helps maximize model performance. However, the impact of prompt design remains underexplored. This paper presents a comprehensive analysis of commonly used prompts across diverse datasets, showing that prompt choice significantly affects ASR performance and introduces instability, with no single prompt performing best across all cases. Inspired by the speech-to-LLM projector, we propose a prompt projector module, a simple, model-agnostic extension that learns to project prompt embeddings to more effective regions of the LLM input space, without modifying the underlying LLM-based ASR model. Experiments on four datasets show that the addition of a prompt projector consistently improves performance, reduces variability, and outperforms the best manually selected prompts.
Spoofing-Aware Speaker Verification via Wavelet Prompt Tuning and Multi-Model Ensembles
Jan 24, 2026This paper describes the UZH-CL system submitted to the SASV section of the WildSpoof 2026 challenge. The challenge focuses on the integrated defense against generative spoofing attacks by requiring the simultaneous verification of speaker identity and audio authenticity. We proposed a cascaded Spoofing-Aware Speaker Verification framework that integrates a Wavelet Prompt-Tuned XLSR-AASIST countermeasure with a multi-model ensemble. The ASV component utilizes the ResNet34, ResNet293, and WavLM-ECAPA-TDNN architectures, with Z-score normalization followed by score averaging. Trained on VoxCeleb2 and SpoofCeleb, the system obtained a Macro a-DCF of 0.2017 and a SASV EER of 2.08%. While the system achieved a 0.16% EER in spoof detection on the in-domain data, results on unseen datasets, such as the ASVspoof5, highlight the critical challenge of cross-domain generalization.
TidyVoice: A Curated Multilingual Dataset for Speaker Verification Derived from Common Voice
Jan 22, 2026The development of robust, multilingual speaker recognition systems is hindered by a lack of large-scale, publicly available and multilingual datasets, particularly for the read-speech style crucial for applications like anti-spoofing. To address this gap, we introduce the TidyVoice dataset derived from the Mozilla Common Voice corpus after mitigating its inherent speaker heterogeneity within the provided client IDs. TidyVoice currently contains training and test data from over 212,000 monolingual speakers (Tidy-M) and around 4,500 multilingual speakers (Tidy-X) from which we derive two distinct conditions. The Tidy-M condition contains target and non-target trials from monolingual speakers across 81 languages. The Tidy-X condition contains target and non-target trials from multilingual speakers in both same- and cross-language trials. We employ two architectures of ResNet models, achieving a 0.35% EER by fine-tuning on our comprehensive Tidy-M partition. Moreover, we show that this fine-tuning enhances the model's generalization, improving performance on unseen conversational interview data from the CANDOR corpus. The complete dataset, evaluation trials, and our models are publicly released to provide a new resource for the community.
Adaptive Multimodal Person Recognition: A Robust Framework for Handling Missing Modalities
Dec 16, 2025Person recognition systems often rely on audio, visual, or behavioral cues, but real-world conditions frequently result in missing or degraded modalities. To address this challenge, we propose a Trimodal person identification framework that integrates voice, face, and gesture modalities, while remaining robust to modality loss. Our approach leverages multi-task learning to process each modality independently, followed by a cross-attention and gated fusion mechanisms to facilitate interaction across modalities. Moreover, a confidence-weighted fusion strategy dynamically adapts to missing and low-quality data, ensuring optimal classification even in Unimodal or Bimodal scenarios. We evaluate our method on CANDOR, a newly introduced interview-based multimodal dataset, which we benchmark for the first time. Our results demonstrate that the proposed Trimodal system achieves 99.18% Top-1 accuracy on person identification tasks, outperforming conventional Unimodal and late-fusion approaches. In addition, we evaluate our model on the VoxCeleb1 dataset as a benchmark and reach 99.92% accuracy in Bimodal mode. Moreover, we show that our system maintains high accuracy even when one or two modalities are unavailable, making it a robust solution for real-world person recognition applications. The code and data for this work are publicly available.
SDialog: A Python Toolkit for End-to-End Agent Building, User Simulation, Dialog Generation, and Evaluation
Dec 12, 2025We present SDialog, an MIT-licensed open-source Python toolkit that unifies dialog generation, evaluation and mechanistic interpretability into a single end-to-end framework for building and analyzing LLM-based conversational agents. Built around a standardized \texttt{Dialog} representation, SDialog provides: (1) persona-driven multi-agent simulation with composable orchestration for controlled, synthetic dialog generation, (2) comprehensive evaluation combining linguistic metrics, LLM-as-a-judge and functional correctness validators, (3) mechanistic interpretability tools for activation inspection and steering via feature ablation and induction, and (4) audio generation with full acoustic simulation including 3D room modeling and microphone effects. The toolkit integrates with all major LLM backends, enabling mixed-backend experiments under a unified API. By coupling generation, evaluation, and interpretability in a dialog-centric architecture, SDialog enables researchers to build, benchmark and understand conversational systems more systematically.
TokenVerse++: Towards Flexible Multitask Learning with Dynamic Task Activation
Aug 27, 2025Token-based multitasking frameworks like TokenVerse require all training utterances to have labels for all tasks, hindering their ability to leverage partially annotated datasets and scale effectively. We propose TokenVerse++, which introduces learnable vectors in the acoustic embedding space of the XLSR-Transducer ASR model for dynamic task activation. This core mechanism enables training with utterances labeled for only a subset of tasks, a key advantage over TokenVerse. We demonstrate this by successfully integrating a dataset with partial labels, specifically for ASR and an additional task, language identification, improving overall performance. TokenVerse++ achieves results on par with or exceeding TokenVerse across multiple tasks, establishing it as a more practical multitask alternative without sacrificing ASR performance.
Better Semi-supervised Learning for Multi-domain ASR Through Incremental Retraining and Data Filtering
Jun 05, 2025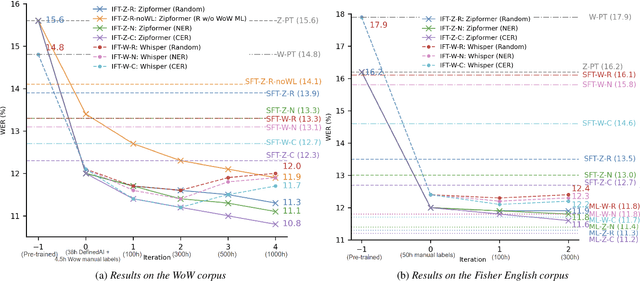
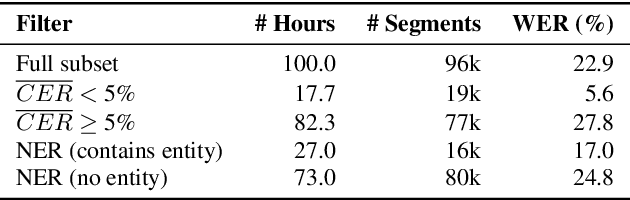

Fine-tuning pretrained ASR models for specific domains is challenging when labeled data is scarce. But unlabeled audio and labeled data from related domains are often available. We propose an incremental semi-supervised learning pipeline that first integrates a small in-domain labeled set and an auxiliary dataset from a closely related domain, achieving a relative improvement of 4% over no auxiliary data. Filtering based on multi-model consensus or named entity recognition (NER) is then applied to select and iteratively refine pseudo-labels, showing slower performance saturation compared to random selection. Evaluated on the multi-domain Wow call center and Fisher English corpora, it outperforms single-step fine-tuning. Consensus-based filtering outperforms other methods, providing up to 22.3% relative improvement on Wow and 24.8% on Fisher over single-step fine-tuning with random selection. NER is the second-best filter, providing competitive performance at a lower computational cost.