 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenVerse: Unifying Speech and NLP Tasks via Transducer-based ASR
Jul 05, 2024



In traditional conversational intelligence from speech, a cascaded pipeline is used, involving tasks such as voice activity detection, diarization, transcription, and subsequent processing with different NLP models for tasks like semantic endpointing and named entity recognition (NER). Our paper introduces TokenVerse, a single Transducer-based model designed to handle multiple tasks. This is achieved by integrating task-specific tokens into the reference text during ASR model training, streamlining the inference and eliminating the need for separate NLP models. In addition to ASR, we conduct experiments on 3 different tasks: speaker change detection, endpointing, and NER. Our experiments on a public and a private dataset show that the proposed method improves ASR by up to 7.7% in relative WER while outperforming the cascaded pipeline approach in individual task performance. Additionally, we present task transfer learning to a new task within an existing TokenVerse.
XLSR-Transducer: Streaming ASR for Self-Supervised Pretrained Models
Jul 05, 2024



Self-supervised pretrained models exhibit competitive performance in automatic speech recognition on finetuning, even with limited in-domain supervised data for training. However, popular pretrained models are not suitable for streaming ASR because they are trained with full attention context. In this paper, we introduce XLSR-Transducer, where the XLSR-53 model is used as encoder in transducer setup. Our experiments on the AMI dataset reveal that the XLSR-Transducer achieves 4% absolute WER improvement over Whisper large-v2 and 8% over a Zipformer transducer model trained from scratch.To enable streaming capabilities, we investigate different attention masking patterns in the self-attention computation of transformer layers within the XLSR-53 model. We validate XLSR-Transducer on AMI and 5 languages from CommonVoice under low-resource scenarios. Finally, with the introduction of attention sinks, we reduce the left context by half while achieving a relative 12% improvement in WER.
Implementing contextual biasing in GPU decoder for online ASR
Jun 23, 2023


GPU decoding significantly accelerates the output of ASR predictions. While GPUs are already being used for online ASR decoding, post-processing and rescoring on GPUs have not been properly investigated yet. Rescoring with available contextual information can considerably improve ASR predictions. Previous studies have proven the viability of lattice rescoring in decoding and biasing language model (LM) weights in offline and online CPU scenarios. In real-time GPU decoding, partial recognition hypotheses are produced without lattice generation, which makes the implementation of biasing more complex. The paper proposes and describes an approach to integrate contextual biasing in real-time GPU decoding while exploiting the standard Kaldi GPU decoder. Besides the biasing of partial ASR predictions, our approach also permits dynamic context switching allowing a flexible rescoring per each speech segment directly on GPU. The code is publicly released and tested with open-sourced test sets.
Lessons Learned in ATCO2: 5000 hours of Air Traffic Control Communications for Robust Automatic Speech Recognition and Understanding
May 02, 2023

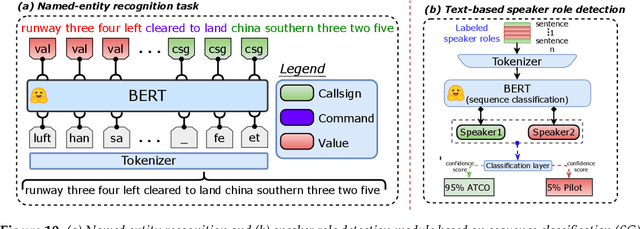

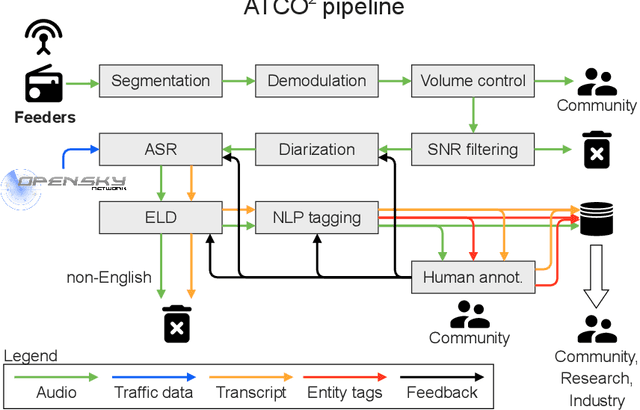
Voice communication between air traffic controllers (ATCos) and pilots is critical for ensuring safe and efficient air traffic control (ATC). This task requires high levels of awareness from ATCos and can be tedious and error-prone. Recent attempts have been made to integrate artificial intelligence (AI) into ATC in order to reduce the workload of ATCos. However, the development of data-driven AI systems for ATC demands large-scale annotated datasets, which are currently lacking in the field. This paper explores the lessons learned from the ATCO2 project, a project that aimed to develop a unique platform to collect and preprocess large amounts of ATC data from airspace in real time. Audio and surveillance data were collected from publicly accessible radio frequency channels with VHF receivers owned by a community of volunteers and later uploaded to Opensky Network servers, which can be considered an "unlimited source" of data. In addition, this paper reviews previous work from ATCO2 partners, including (i) robust automatic speech recognition, (ii) natural language processing, (iii) English language identification of ATC communications, and (iv) the integration of surveillance data such as ADS-B. We believe that the pipeline developed during the ATCO2 project, along with the open-sourcing of its data, will encourage research in the ATC field. A sample of the ATCO2 corpus is available on the following website: https://www.atco2.org/data, while the full corpus can be purchased through ELDA at http://catalog.elra.info/en-us/repository/browse/ELRA-S0484. We demonstrated that ATCO2 is an appropriate dataset to develop ASR engines when little or near to no ATC in-domain data is available. For instance, with the CNN-TDNNf kaldi model, we reached the performance of as low as 17.9% and 24.9% WER on public ATC datasets which is 6.6/7.6% better than "out-of-domain" but supervised CNN-TDNNf model.
A Virtual Simulation-Pilot Agent for Training of Air Traffic Controllers
Apr 16, 2023In this paper we propose a novel virtual simulation-pilot engine for speeding up air traffic controller (ATCo) training by integrating different state-of-the-art artificial intelligence (AI) based tools. The virtual simulation-pilot engine receives spoken communications from ATCo trainees, and it performs automatic speech recognition and understanding. Thus, it goes beyond only transcribing the communication and can also understand its meaning. The output is subsequently sent to a response generator system, which resembles the spoken read back that pilots give to the ATCo trainees. The overall pipeline is composed of the following submodules: (i) automatic speech recognition (ASR) system that transforms audio into a sequence of words; (ii) high-level air traffic control (ATC) related entity parser that understands the transcribed voice communication; and (iii) a text-to-speech submodule that generates a spoken utterance that resembles a pilot based on the situation of the dialogue. Our system employs state-of-the-art AI-based tools such as Wav2Vec 2.0, Conformer, BERT and Tacotron models. To the best of our knowledge, this is the first work fully based on open-source ATC resources and AI tools. In addition, we have developed a robust and modular system with optional submodules that can enhance the system's performance by incorporating real-time surveillance data, metadata related to exercises (such as sectors or runways), or even introducing a deliberate read-back error to train ATCo trainees to identify them. Our ASR system can reach as low as 5.5% and 15.9% word error rates (WER) on high and low-quality ATC audio. We also demonstrate that adding surveillance data into the ASR can yield callsign detection accuracy of more than 96%.
Effectiveness of Text, Acoustic, and Lattice-based representations in Spoken Language Understanding tasks
Dec 16, 2022



In this paper, we perform an exhaustive evaluation of different representations to address the intent classification problem in a Spoken Language Understanding (SLU) setup. We benchmark three types of systems to perform the SLU intent detection task: 1) text-based, 2) lattice-based, and a novel 3) multimodal approach. Our work provides a comprehensive analysis of what could be the achievable performance of different state-of-the-art SLU systems under different circumstances, e.g., automatically- vs. manually-generated transcripts. We evaluate the systems on the publicly available SLURP spoken language resource corpus. Our results indicate that using richer forms of Automatic Speech Recognition (ASR) outputs allows SLU systems to improve in comparison to the 1-best setup (4% relative improvement). However, crossmodal approaches, i.e., learning from acoustic and text embeddings, obtains performance similar to the oracle setup, and a relative improvement of 18% over the 1-best configuration. Thus, crossmodal architectures represent a good alternative to overcome the limitations of working purely automatically generated textual data.
Speech and Natural Language Processing Technologies for Pseudo-Pilot Simulator
Dec 14, 2022



This paper describes a simple yet efficient repetition-based modular system for speeding up air-traffic controllers (ATCos) training. E.g., a human pilot is still required in EUROCONTROL's ESCAPE lite simulator (see https://www.eurocontrol.int/simulator/escape) during ATCo training. However, this need can be substituted by an automatic system that could act as a pilot. In this paper, we aim to develop and integrate a pseudo-pilot agent into the ATCo training pipeline by merging diverse artificial intelligence (AI) powered modules. The system understands the voice communications issued by the ATCo, and, in turn, it generates a spoken prompt that follows the pilot's phraseology to the initial communication. Our system mainly relies on open-source AI tools and air traffic control (ATC) databases, thus, proving its simplicity and ease of replicability. The overall pipeline is composed of the following: (1) a submodule that receives and pre-processes the input stream of raw audio, (2) an automatic speech recognition (ASR) system that transforms audio into a sequence of words; (3) a high-level ATC-related entity parser, which extracts relevant information from the communication, i.e., callsigns and commands, and finally, (4) a speech synthesizer submodule that generates responses based on the high-level ATC entities previously extracted. Overall, we show that this system could pave the way toward developing a real proof-of-concept pseudo-pilot system. Hence, speeding up the training of ATCos while drastically reducing its overall cost.
ATCO2 corpus: A Large-Scale Dataset for Research on Automatic Speech Recognition and Natural Language Understanding of Air Traffic Control Communications
Nov 08, 2022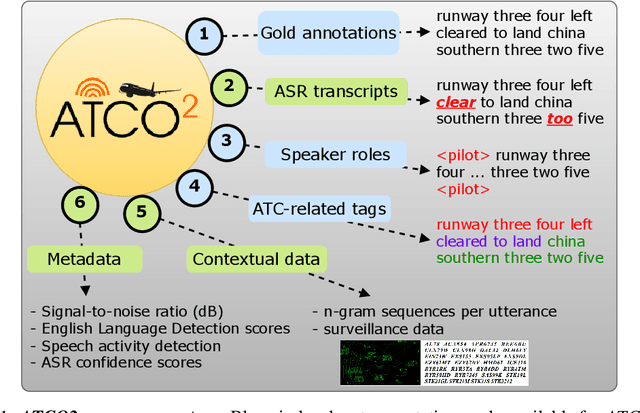
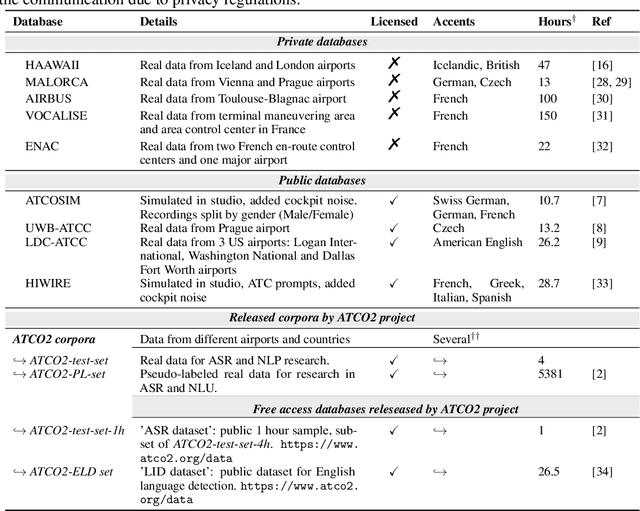

Personal assistants, automatic speech recognizers and dialogue understanding systems are becoming more critical in our interconnected digital world. A clear example is air traffic control (ATC) communications. ATC aims at guiding aircraft and controlling the airspace in a safe and optimal manner. These voice-based dialogues are carried between an air traffic controller (ATCO) and pilots via very-high frequency radio channels. In order to incorporate these novel technologies into ATC (low-resource domain), large-scale annotated datasets are required to develop the data-driven AI systems. Two examples are automatic speech recognition (ASR) and natural language understanding (NLU). In this paper, we introduce the ATCO2 corpus, a dataset that aims at fostering research on the challenging ATC field, which has lagged behind due to lack of annotated data. The ATCO2 corpus covers 1) data collection and pre-processing, 2) pseudo-annotations of speech data, and 3) extraction of ATC-related named entities. The ATCO2 corpus is split into three subsets. 1) ATCO2-test-set corpus contains 4 hours of ATC speech with manual transcripts and a subset with gold annotations for named-entity recognition (callsign, command, value). 2) The ATCO2-PL-set corpus consists of 5281 hours of unlabeled ATC data enriched with automatic transcripts from an in-domain speech recognizer, contextual information, speaker turn information, signal-to-noise ratio estimate and English language detection score per sample. Both available for purchase through ELDA at http://catalog.elra.info/en-us/repository/browse/ELRA-S0484. 3) The ATCO2-test-set-1h corpus is a one-hour subset from the original test set corpus, that we are offering for free at https://www.atco2.org/data. We expect the ATCO2 corpus will foster research on robust ASR and NLU not only in the field of ATC communications but also in the general research community.
How Does Pre-trained Wav2Vec2.0 Perform on Domain Shifted ASR? An Extensive Benchmark on Air Traffic Control Communications
Mar 31, 2022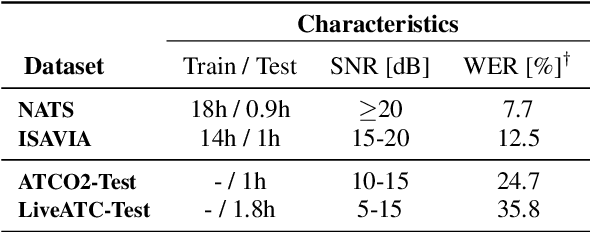
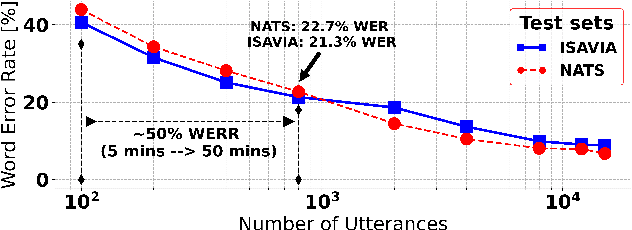
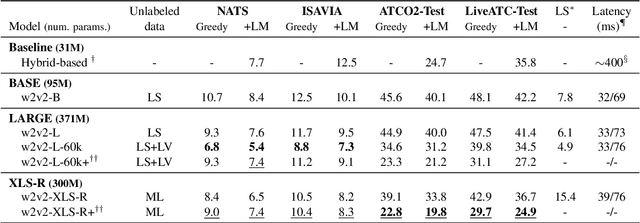
Recent work on self-supervised pre-training focus on leveraging large-scale unlabeled speech data to build robust end-to-end (E2E) acoustic models (AM) that can be later fine-tuned on downstream tasks e.g., automatic speech recognition (ASR). Yet, few works investigated the impact on performance when the data substantially differs between the pre-training and downstream fine-tuning phases (i.e., domain shift). We target this scenario by analyzing the robustness of Wav2Vec2.0 and XLS-R models on downstream ASR for a completely unseen domain, i.e., air traffic control (ATC) communications. We benchmark the proposed models on four challenging ATC test sets (signal-to-noise ratio varies between 5 to 20 dB). Relative word error rate (WER) reduction between 20% to 40% are obtained in comparison to hybrid-based state-of-the-art ASR baselines by fine-tuning E2E acoustic models with a small fraction of labeled data. We also study the impact of fine-tuning data size on WERs, going from 5 minutes (few-shot) to 15 hours.
A two-step approach to leverage contextual data: speech recognition in air-traffic communications
Feb 08, 2022

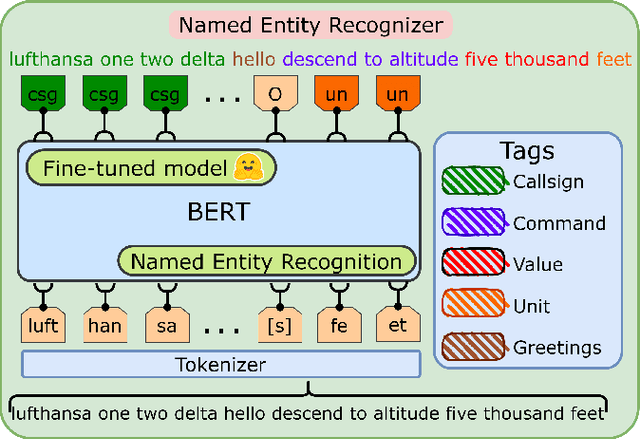
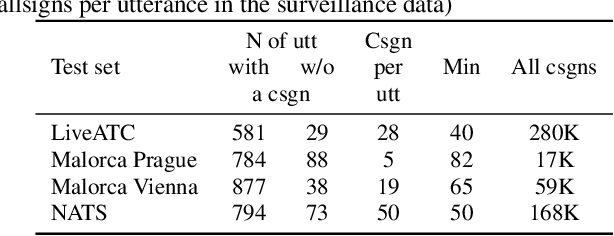
Automatic Speech Recognition (ASR), as the assistance of speech communication between pilots and air-traffic controllers, can significantly reduce the complexity of the task and increase the reliability of transmitted information. ASR application can lead to a lower number of incidents caused by misunderstanding and improve air traffic management (ATM) efficiency. Evidently, high accuracy predictions, especially, of key information, i.e., callsigns and commands, are required to minimize the risk of errors. We prove that combining the benefits of ASR and Natural Language Processing (NLP) methods to make use of surveillance data (i.e. additional modality) helps to considerably improve the recognition of callsigns (named entity). In this paper, we investigate a two-step callsign boosting approach: (1) at the 1 step (ASR), weights of probable callsign n-grams are reduced in G.fst and/or in the decoding FST (lattices), (2) at the 2 step (NLP), callsigns extracted from the improved recognition outputs with Named Entity Recognition (NER) are correlated with the surveillance data to select the most suitable one. Boosting callsign n-grams with the combination of ASR and NLP methods eventually leads up to 53.7% of an absolute, or 60.4% of a relative, improvement in callsign recognition.
* 20XX IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works. arXiv admin note: text overlap with arXiv:2108.12156