 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does Pre-trained Wav2Vec2.0 Perform on Domain Shifted ASR? An Extensive Benchmark on Air Traffic Control Communications
Mar 31, 2022
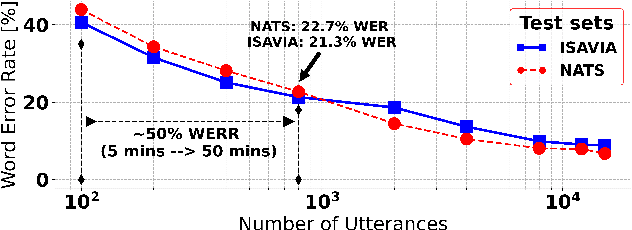
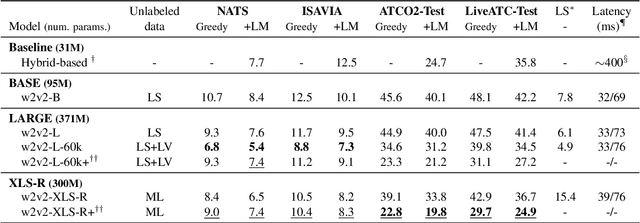
Recent work on self-supervised pre-training focus on leveraging large-scale unlabeled speech data to build robust end-to-end (E2E) acoustic models (AM) that can be later fine-tuned on downstream tasks e.g., automatic speech recognition (ASR). Yet, few works investigated the impact on performance when the data substantially differs between the pre-training and downstream fine-tuning phases (i.e., domain shift). We target this scenario by analyzing the robustness of Wav2Vec2.0 and XLS-R models on downstream ASR for a completely unseen domain, i.e., air traffic control (ATC) communications. We benchmark the proposed models on four challenging ATC test sets (signal-to-noise ratio varies between 5 to 20 dB). Relative word error rate (WER) reduction between 20% to 40% are obtained in comparison to hybrid-based state-of-the-art ASR baselines by fine-tuning E2E acoustic models with a small fraction of labeled data. We also study the impact of fine-tuning data size on WERs, going from 5 minutes (few-shot) to 15 hours.
Automatic Speech Recognition Benchmark for Air-Traffic Communications
Jun 18, 2020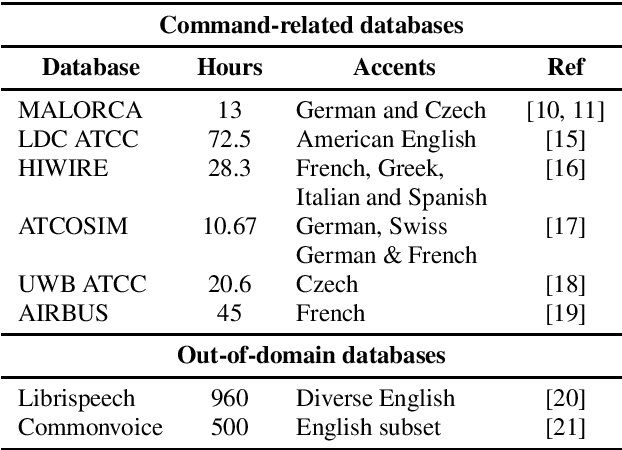
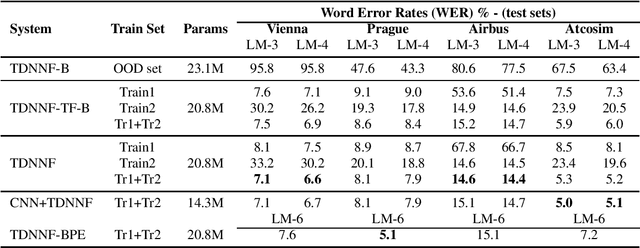
Advances in Automatic Speech Recognition (ASR) over the last decade opened new areas of speech-based automation such as in Air-Traffic Control (ATC) environment. Currently, voice communication and data links communications are the only way of contact between pilots and Air-Traffic Controllers (ATCo), where the former is the most widely used and the latter is a non-spoken method mandatory for oceanic messages and limited for some domestic issues. ASR systems on ATCo environments inherit increasing complexity due to accents from non-English speakers, cockpit noise, speaker-dependent biases, and small in-domain ATC databases for training. Hereby, we introduce CleanSky EC-H2020 ATCO2, a project that aims to develop an ASR-based platform to collect, organize and automatically pre-process ATCo speech-data from air space. This paper conveys an exploratory benchmark of several state-of-the-art ASR models trained on more than 170 hours of ATCo speech-data. We demonstrate that the cross-accent flaws due to speakers' accents are minimized due to the amount of data, making the system feasible for ATC environments. The developed ASR system achieves an averaged word error rate (WER) of 7.75% across four databases. An additional 35% relative improvement in WER is achieved on one test set when training a TDNNF system with byte-pair encoding.