 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Source Conversational AI with SpeechBrain 1.0
Jul 02, 2024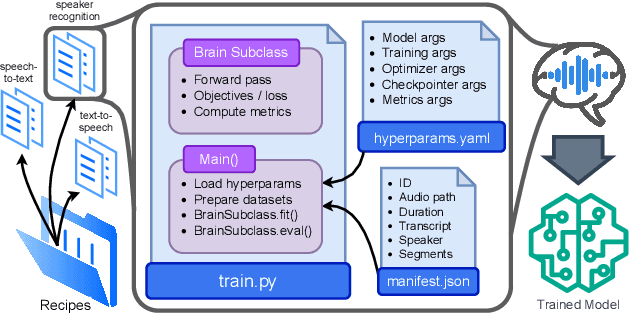

SpeechBrain is an open-source Conversational AI toolkit based on PyTorch, focused particularly on speech processing tasks such as speech recognition, speech enhancement, speaker recognition, text-to-speech, and much more. It promotes transparency and replicability by releasing both the pre-trained models and the complete "recipes" of code and algorithms required for training them. This paper presents SpeechBrain 1.0, a significant milestone in the evolution of the toolkit, which now has over 200 recipes for speech, audio, and language processing tasks, and more than 100 models available on Hugging Face. SpeechBrain 1.0 introduces new technologies to support diverse learning modalities, Large Language Model (LLM) integration, and advanced decoding strategies, along with novel models, tasks, and modalities. It also includes a new benchmark repository, offering researchers a unified platform for evaluating models across diverse tasks
Improving callsign recognition with air-surveillance data in air-traffic communication
Aug 27, 2021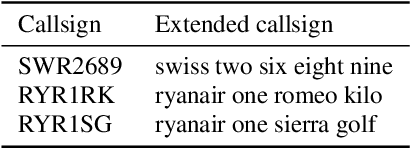
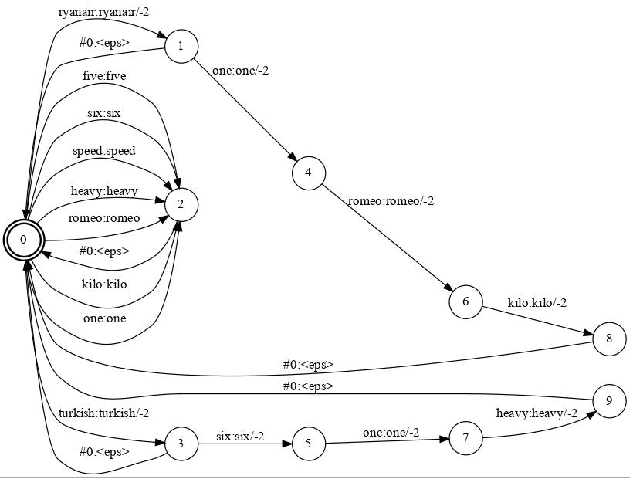
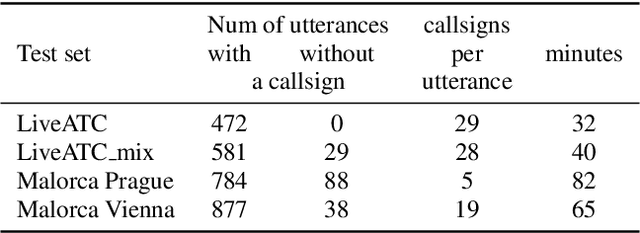
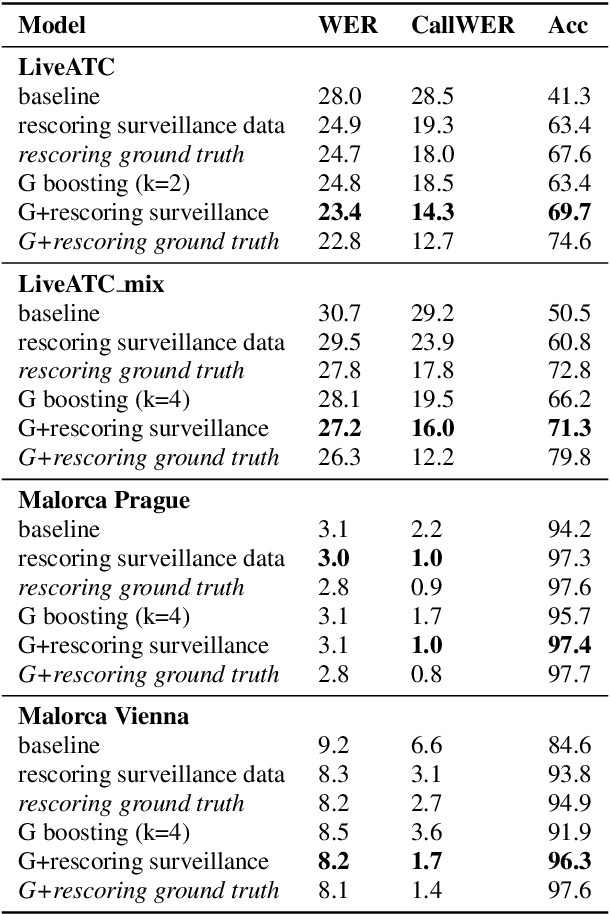
Automatic Speech Recognition (ASR) can be used as the assistance of speech communication between pilots and air-traffic controllers. Its application can significantly reduce the complexity of the task and increase the reliability of transmitted information. Evidently, high accuracy predictions are needed to minimize the risk of errors. Especially, high accuracy is required in recognition of key information, such as commands and callsigns, used to navigate pilots. Our results prove that the surveillance data containing callsigns can help to considerably improve the recognition of a callsign in an utterance when the weights of probable callsign n-grams are reduced per utterance. In this paper, we investigate two approaches: (1) G-boosting, when callsigns weights are adjusted at language model level (G) and followed by the dynamic decoder with an on-the-fly composition, and (2) lattice rescoring when callsign information is introduced on top of lattices generated using a conventional decoder. Boosting callsign n-grams with the combination of two methods allowed us to gain 28.4% of absolute improvement in callsign recognition accuracy and up to 74.2% of relative improvement in WER of callsign recognition.
Automatic Speech Recognition Benchmark for Air-Traffic Communications
Jun 18, 2020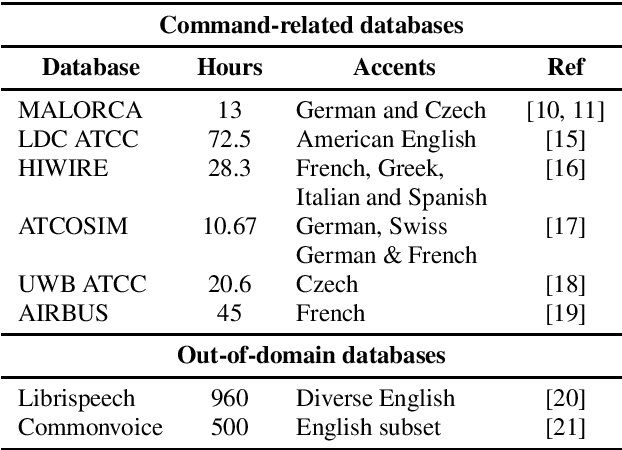
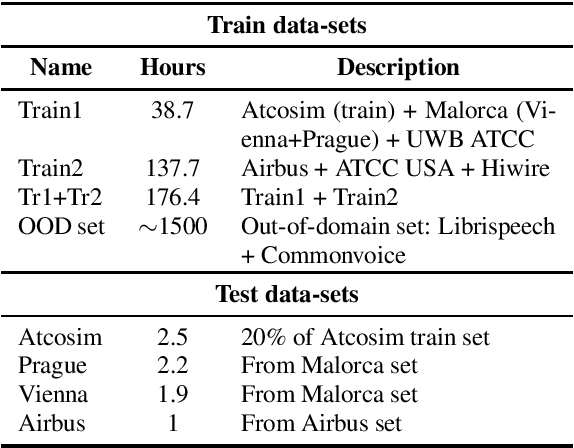
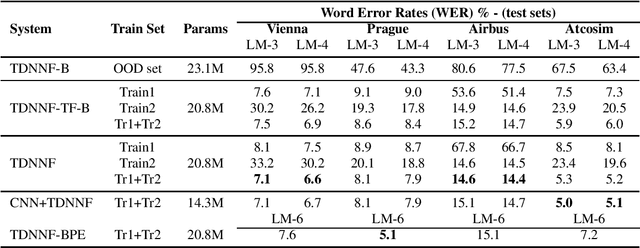
Advances in Automatic Speech Recognition (ASR) over the last decade opened new areas of speech-based automation such as in Air-Traffic Control (ATC) environment. Currently, voice communication and data links communications are the only way of contact between pilots and Air-Traffic Controllers (ATCo), where the former is the most widely used and the latter is a non-spoken method mandatory for oceanic messages and limited for some domestic issues. ASR systems on ATCo environments inherit increasing complexity due to accents from non-English speakers, cockpit noise, speaker-dependent biases, and small in-domain ATC databases for training. Hereby, we introduce CleanSky EC-H2020 ATCO2, a project that aims to develop an ASR-based platform to collect, organize and automatically pre-process ATCo speech-data from air space. This paper conveys an exploratory benchmark of several state-of-the-art ASR models trained on more than 170 hours of ATCo speech-data. We demonstrate that the cross-accent flaws due to speakers' accents are minimized due to the amount of data, making the system feasible for ATC environments. The developed ASR system achieves an averaged word error rate (WER) of 7.75% across four databases. An additional 35% relative improvement in WER is achieved on one test set when training a TDNNF system with byte-pair encoding.