 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech and Natural Language Processing Technologies for Pseudo-Pilot Simulator
Dec 14, 2022



This paper describes a simple yet efficient repetition-based modular system for speeding up air-traffic controllers (ATCos) training. E.g., a human pilot is still required in EUROCONTROL's ESCAPE lite simulator (see https://www.eurocontrol.int/simulator/escape) during ATCo training. However, this need can be substituted by an automatic system that could act as a pilot. In this paper, we aim to develop and integrate a pseudo-pilot agent into the ATCo training pipeline by merging diverse artificial intelligence (AI) powered modules. The system understands the voice communications issued by the ATCo, and, in turn, it generates a spoken prompt that follows the pilot's phraseology to the initial communication. Our system mainly relies on open-source AI tools and air traffic control (ATC) databases, thus, proving its simplicity and ease of replicability. The overall pipeline is composed of the following: (1) a submodule that receives and pre-processes the input stream of raw audio, (2) an automatic speech recognition (ASR) system that transforms audio into a sequence of words; (3) a high-level ATC-related entity parser, which extracts relevant information from the communication, i.e., callsigns and commands, and finally, (4) a speech synthesizer submodule that generates responses based on the high-level ATC entities previously extracted. Overall, we show that this system could pave the way toward developing a real proof-of-concept pseudo-pilot system. Hence, speeding up the training of ATCos while drastically reducing its overall cost.
Detecting English Speech in the Air Traffic Control Voice Communication
Apr 06, 2021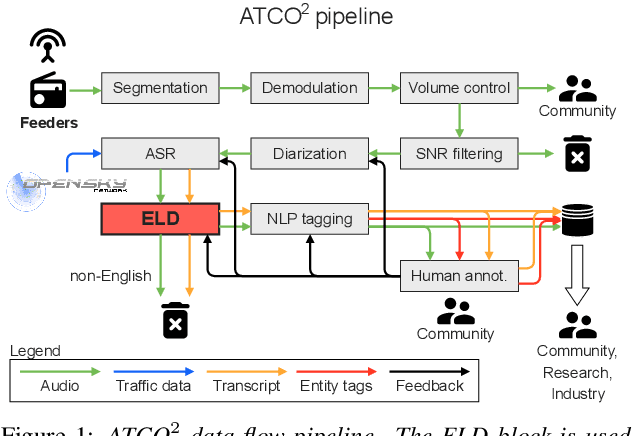
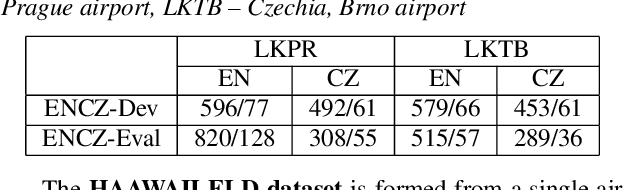
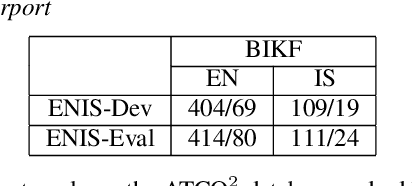

We launched a community platform for collecting the ATC speech world-wide in the ATCO2 project. Filtering out unseen non-English speech is one of the main components in the data processing pipeline. The proposed English Language Detection (ELD) system is based on the embeddings from Bayesian subspace multinomial model. It is trained on the word confusion network from an ASR system. It is robust, easy to train, and light weighted. We achieved 0.0439 equal-error-rate (EER), a 50% relative reduction as compared to the state-of-the-art acoustic ELD system based on x-vectors, in the in-domain scenario. Further, we achieved an EER of 0.1352, a 33% relative reduction as compared to the acoustic ELD, in the unseen language (out-of-domain) condition. We plan to publish the evaluation dataset from the ATCO2 project.
Automatic Speech Recognition Benchmark for Air-Traffic Communications
Jun 18, 2020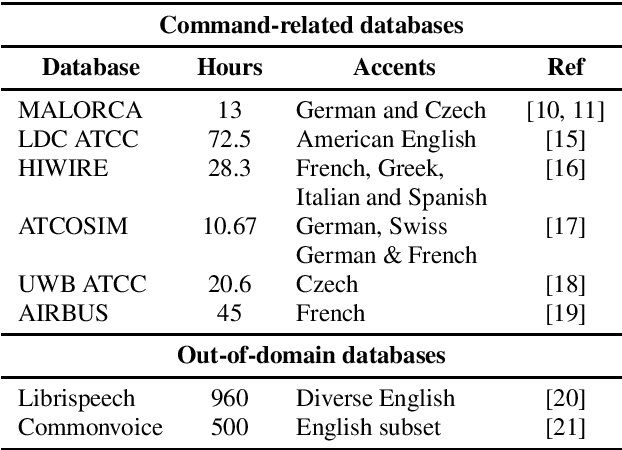
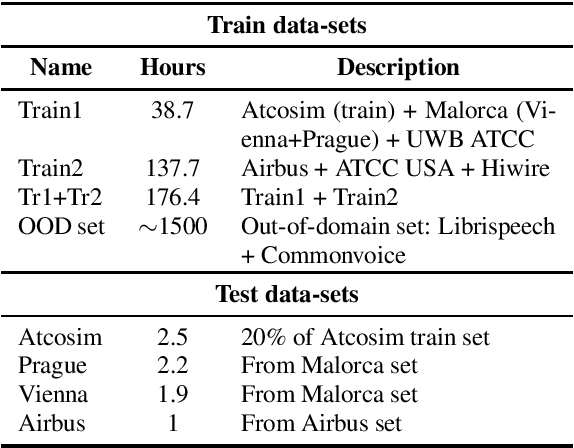
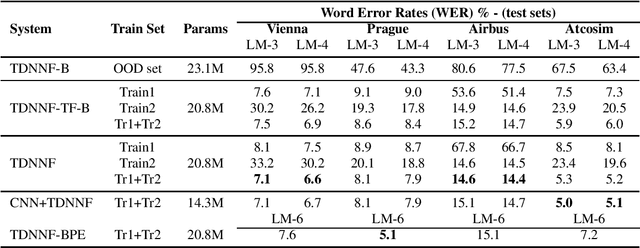
Advances in Automatic Speech Recognition (ASR) over the last decade opened new areas of speech-based automation such as in Air-Traffic Control (ATC) environment. Currently, voice communication and data links communications are the only way of contact between pilots and Air-Traffic Controllers (ATCo), where the former is the most widely used and the latter is a non-spoken method mandatory for oceanic messages and limited for some domestic issues. ASR systems on ATCo environments inherit increasing complexity due to accents from non-English speakers, cockpit noise, speaker-dependent biases, and small in-domain ATC databases for training. Hereby, we introduce CleanSky EC-H2020 ATCO2, a project that aims to develop an ASR-based platform to collect, organize and automatically pre-process ATCo speech-data from air space. This paper conveys an exploratory benchmark of several state-of-the-art ASR models trained on more than 170 hours of ATCo speech-data. We demonstrate that the cross-accent flaws due to speakers' accents are minimized due to the amount of data, making the system feasible for ATC environments. The developed ASR system achieves an averaged word error rate (WER) of 7.75% across four databases. An additional 35% relative improvement in WER is achieved on one test set when training a TDNNF system with byte-pair encoding.
Residual Memory Networks: Feed-forward approach to learn long temporal dependencies
Aug 06, 2018
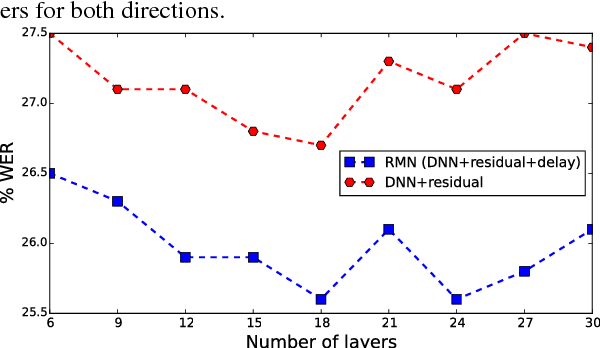
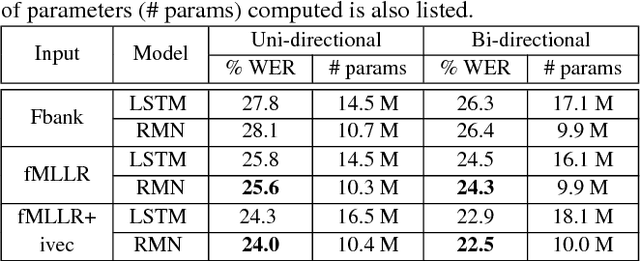
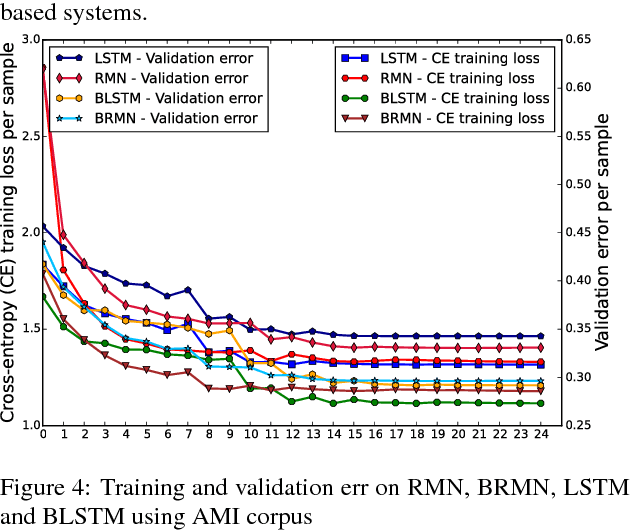
Training deep recurrent neural network (RNN) architectures is complicated due to the increased network complexity. This disrupts the learning of higher order abstracts using deep RNN. In case of feed-forward networks training deep structures is simple and faster while learning long-term temporal information is not possible. In this paper we propose a residual memory neural network (RMN) architecture to model short-time dependencies using deep feed-forward layers having residual and time delayed connections. The residual connection paves way to construct deeper networks by enabling unhindered flow of gradients and the time delay units capture temporal information with shared weights. The number of layers in RMN signifies both the hierarchical processing depth and temporal depth. The computational complexity in training RMN is significantly less when compared to deep recurrent networks. RMN is further extended as bi-directional RMN (BRMN) to capture both past and future information. Experimental analysis is done on AMI corpus to substantiate the capability of RMN in learning long-term information and hierarchical information. Recognition performance of RMN trained with 300 hours of Switchboard corpus is compared with various state-of-the-art LVCSR systems. The results indicate that RMN and BRMN gains 6 % and 3.8 % relative improvement over LSTM and BLSTM networks.