 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech and Natural Language Processing Technologies for Pseudo-Pilot Simulator
Dec 14, 2022



This paper describes a simple yet efficient repetition-based modular system for speeding up air-traffic controllers (ATCos) training. E.g., a human pilot is still required in EUROCONTROL's ESCAPE lite simulator (see https://www.eurocontrol.int/simulator/escape) during ATCo training. However, this need can be substituted by an automatic system that could act as a pilot. In this paper, we aim to develop and integrate a pseudo-pilot agent into the ATCo training pipeline by merging diverse artificial intelligence (AI) powered modules. The system understands the voice communications issued by the ATCo, and, in turn, it generates a spoken prompt that follows the pilot's phraseology to the initial communication. Our system mainly relies on open-source AI tools and air traffic control (ATC) databases, thus, proving its simplicity and ease of replicability. The overall pipeline is composed of the following: (1) a submodule that receives and pre-processes the input stream of raw audio, (2) an automatic speech recognition (ASR) system that transforms audio into a sequence of words; (3) a high-level ATC-related entity parser, which extracts relevant information from the communication, i.e., callsigns and commands, and finally, (4) a speech synthesizer submodule that generates responses based on the high-level ATC entities previously extracted. Overall, we show that this system could pave the way toward developing a real proof-of-concept pseudo-pilot system. Hence, speeding up the training of ATCos while drastically reducing its overall cost.
How Does Pre-trained Wav2Vec2.0 Perform on Domain Shifted ASR? An Extensive Benchmark on Air Traffic Control Communications
Mar 31, 2022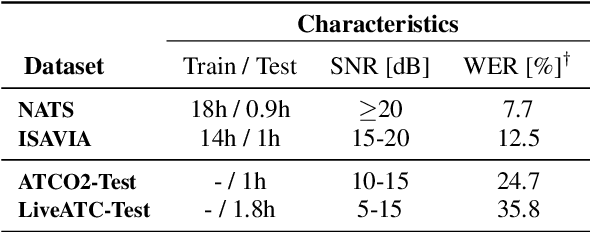
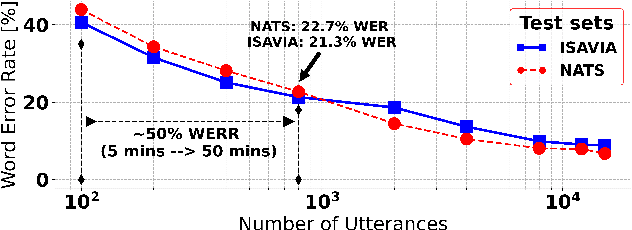
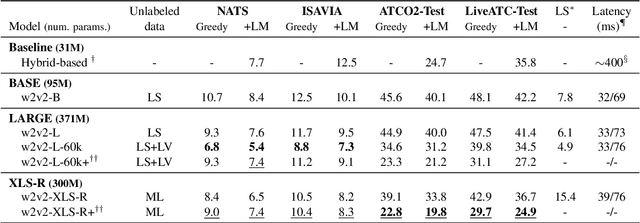
Recent work on self-supervised pre-training focus on leveraging large-scale unlabeled speech data to build robust end-to-end (E2E) acoustic models (AM) that can be later fine-tuned on downstream tasks e.g., automatic speech recognition (ASR). Yet, few works investigated the impact on performance when the data substantially differs between the pre-training and downstream fine-tuning phases (i.e., domain shift). We target this scenario by analyzing the robustness of Wav2Vec2.0 and XLS-R models on downstream ASR for a completely unseen domain, i.e., air traffic control (ATC) communications. We benchmark the proposed models on four challenging ATC test sets (signal-to-noise ratio varies between 5 to 20 dB). Relative word error rate (WER) reduction between 20% to 40% are obtained in comparison to hybrid-based state-of-the-art ASR baselines by fine-tuning E2E acoustic models with a small fraction of labeled data. We also study the impact of fine-tuning data size on WERs, going from 5 minutes (few-shot) to 15 hours.
Grammar Based Identification Of Speaker Role For Improving ATCO And Pilot ASR
Aug 27, 2021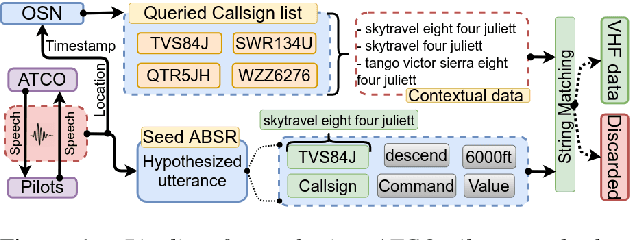
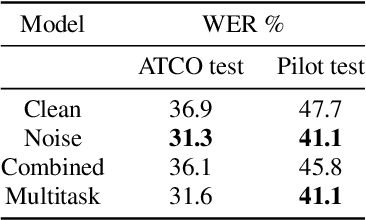
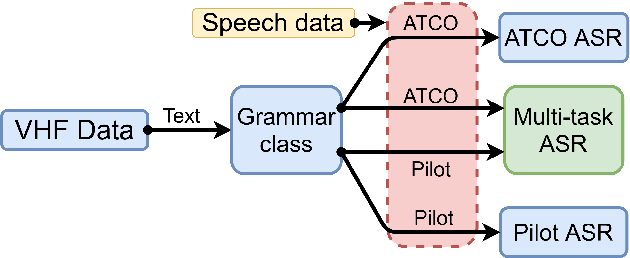
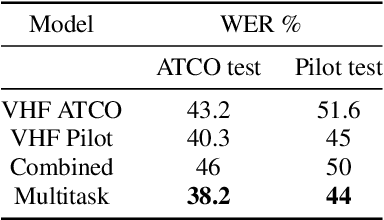
Assistant Based Speech Recognition (ABSR) for air traffic control is generally trained by pooling both Air Traffic Controller (ATCO) and pilot data. In practice, this is motivated by the fact that the proportion of pilot data is lesser compared to ATCO while their standard language of communication is similar. However, due to data imbalance of ATCO and pilot and their varying acoustic conditions, the ASR performance is usually significantly better for ATCOs than pilots. In this paper, we propose to (1) split the ATCO and pilot data using an automatic approach exploiting ASR transcripts, and (2) consider ATCO and pilot ASR as two separate tasks for Acoustic Model (AM) training. For speaker role classification of ATCO and pilot data, a hypothesized ASR transcript is generated with a seed model, subsequently used to classify the speaker role based on the knowledge extracted from grammar defined by International Civil Aviation Organization (ICAO). This approach provides an average speaker role identification accuracy of 83% for ATCO and pilot. Finally, we show that training AMs separately for each task, or using a multitask approach is well suited for this data compared to AM trained by pooling all data.