 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Virtual Simulation-Pilot Agent for Training of Air Traffic Controllers
Apr 16, 2023In this paper we propose a novel virtual simulation-pilot engine for speeding up air traffic controller (ATCo) training by integrating different state-of-the-art artificial intelligence (AI) based tools. The virtual simulation-pilot engine receives spoken communications from ATCo trainees, and it performs automatic speech recognition and understanding. Thus, it goes beyond only transcribing the communication and can also understand its meaning. The output is subsequently sent to a response generator system, which resembles the spoken read back that pilots give to the ATCo trainees. The overall pipeline is composed of the following submodules: (i) automatic speech recognition (ASR) system that transforms audio into a sequence of words; (ii) high-level air traffic control (ATC) related entity parser that understands the transcribed voice communication; and (iii) a text-to-speech submodule that generates a spoken utterance that resembles a pilot based on the situation of the dialogue. Our system employs state-of-the-art AI-based tools such as Wav2Vec 2.0, Conformer, BERT and Tacotron models. To the best of our knowledge, this is the first work fully based on open-source ATC resources and AI tools. In addition, we have developed a robust and modular system with optional submodules that can enhance the system's performance by incorporating real-time surveillance data, metadata related to exercises (such as sectors or runways), or even introducing a deliberate read-back error to train ATCo trainees to identify them. Our ASR system can reach as low as 5.5% and 15.9% word error rates (WER) on high and low-quality ATC audio. We also demonstrate that adding surveillance data into the ASR can yield callsign detection accuracy of more than 96%.
How Does Pre-trained Wav2Vec2.0 Perform on Domain Shifted ASR? An Extensive Benchmark on Air Traffic Control Communications
Mar 31, 2022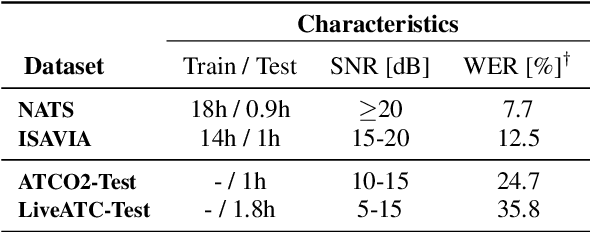
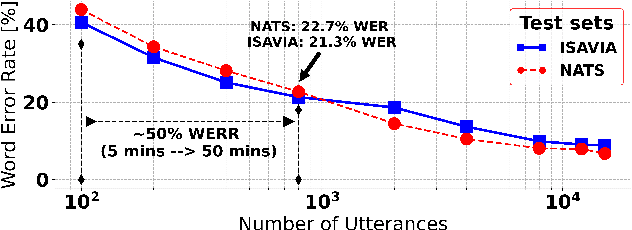
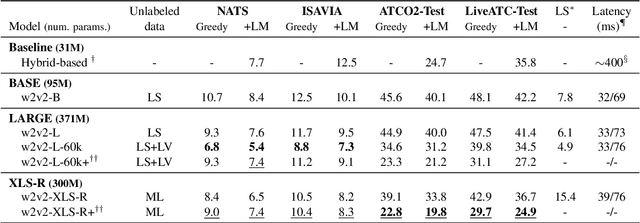
Recent work on self-supervised pre-training focus on leveraging large-scale unlabeled speech data to build robust end-to-end (E2E) acoustic models (AM) that can be later fine-tuned on downstream tasks e.g., automatic speech recognition (ASR). Yet, few works investigated the impact on performance when the data substantially differs between the pre-training and downstream fine-tuning phases (i.e., domain shift). We target this scenario by analyzing the robustness of Wav2Vec2.0 and XLS-R models on downstream ASR for a completely unseen domain, i.e., air traffic control (ATC) communications. We benchmark the proposed models on four challenging ATC test sets (signal-to-noise ratio varies between 5 to 20 dB). Relative word error rate (WER) reduction between 20% to 40% are obtained in comparison to hybrid-based state-of-the-art ASR baselines by fine-tuning E2E acoustic models with a small fraction of labeled data. We also study the impact of fine-tuning data size on WERs, going from 5 minutes (few-shot) to 15 hours.