 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does Pre-trained Wav2Vec2.0 Perform on Domain Shifted ASR? An Extensive Benchmark on Air Traffic Control Communications
Mar 31, 2022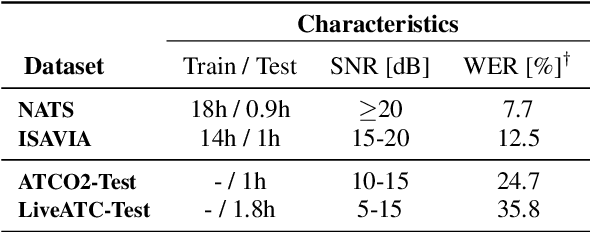
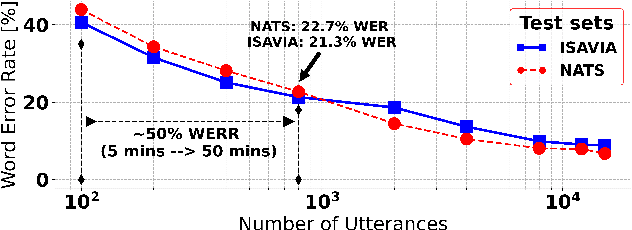
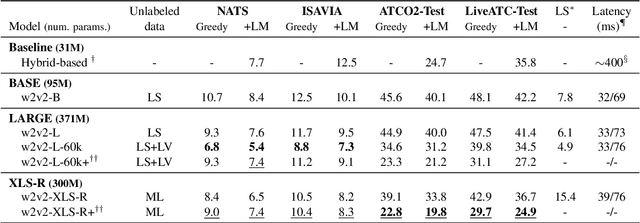
Recent work on self-supervised pre-training focus on leveraging large-scale unlabeled speech data to build robust end-to-end (E2E) acoustic models (AM) that can be later fine-tuned on downstream tasks e.g., automatic speech recognition (ASR). Yet, few works investigated the impact on performance when the data substantially differs between the pre-training and downstream fine-tuning phases (i.e., domain shift). We target this scenario by analyzing the robustness of Wav2Vec2.0 and XLS-R models on downstream ASR for a completely unseen domain, i.e., air traffic control (ATC) communications. We benchmark the proposed models on four challenging ATC test sets (signal-to-noise ratio varies between 5 to 20 dB). Relative word error rate (WER) reduction between 20% to 40% are obtained in comparison to hybrid-based state-of-the-art ASR baselines by fine-tuning E2E acoustic models with a small fraction of labeled data. We also study the impact of fine-tuning data size on WERs, going from 5 minutes (few-shot) to 15 hours.
BERTraffic: A Robust BERT-Based Approach for Speaker Change Detection and Role Identification of Air-Traffic Communications
Oct 12, 2021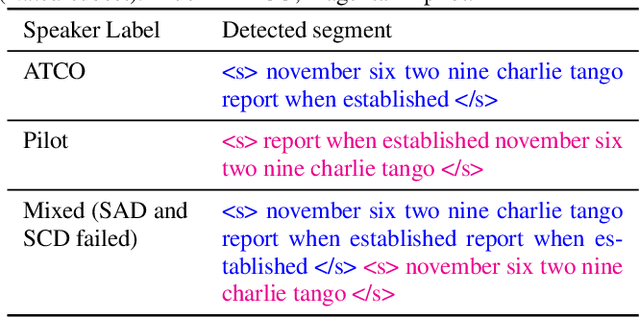
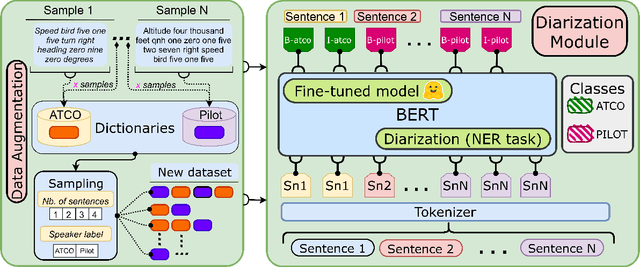
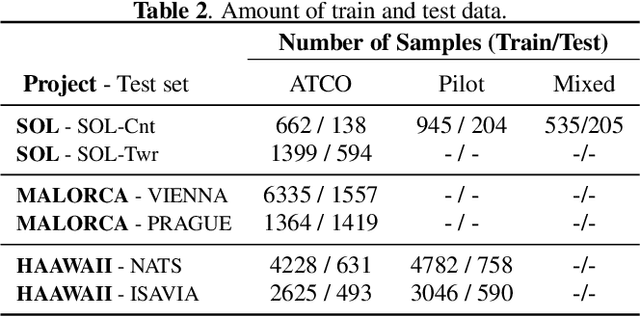
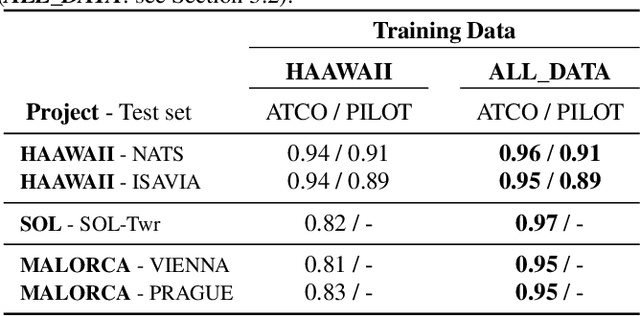
Automatic Speech Recognition (ASR) is gaining special interest in Air Traffic Control (ATC). ASR allows transcribing the communications between air traffic controllers (ATCOs) and pilots. These transcriptions are used to extract ATC command types and named entities such as aircraft callsigns. One common problem is when the Speech Activity Detection (SAD) or diarization system fails and then two or more single speaker segments are in the same recording, jeopardizing the overall system's performance. We developed a system that combines the segmentation of a SAD module with a BERT-based model that performs Speaker Change Detection (SCD) and Speaker Role Identification (SRI) based on ASR transcripts (i.e., diarization + SRI). This research demonstrates on a real-life ATC test set that performing diarization directly on textual data surpass acoustic level diarization. The proposed model reaches up to ~0.90/~0.95 F1-score on ATCO/pilot for SRI on several test sets. The text-based diarization system brings a 27% relative improvement on Diarization Error Rate (DER) compared to standard acoustic-based diarization. These results were on ASR transcripts of a challenging ATC test set with an estimated ~13% word error rate, validating the approach's robustness even on noisy ASR transcripts.
Grammar Based Identification Of Speaker Role For Improving ATCO And Pilot ASR
Aug 27, 2021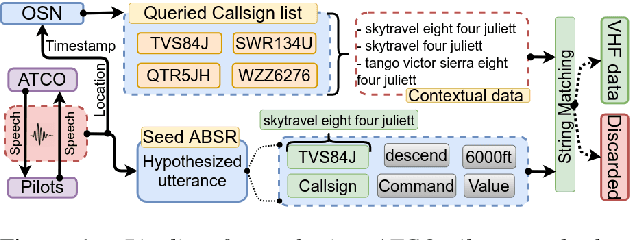
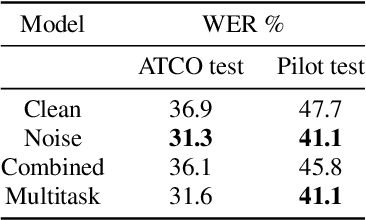
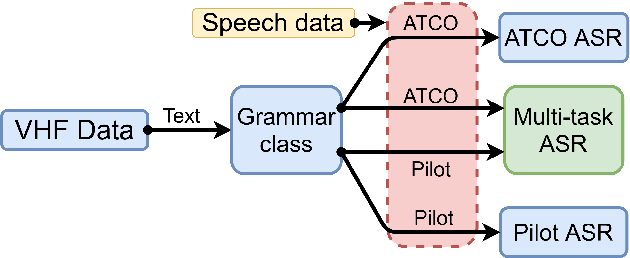
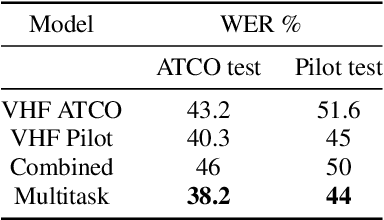
Assistant Based Speech Recognition (ABSR) for air traffic control is generally trained by pooling both Air Traffic Controller (ATCO) and pilot data. In practice, this is motivated by the fact that the proportion of pilot data is lesser compared to ATCO while their standard language of communication is similar. However, due to data imbalance of ATCO and pilot and their varying acoustic conditions, the ASR performance is usually significantly better for ATCOs than pilots. In this paper, we propose to (1) split the ATCO and pilot data using an automatic approach exploiting ASR transcripts, and (2) consider ATCO and pilot ASR as two separate tasks for Acoustic Model (AM) training. For speaker role classification of ATCO and pilot data, a hypothesized ASR transcript is generated with a seed model, subsequently used to classify the speaker role based on the knowledge extracted from grammar defined by International Civil Aviation Organization (ICAO). This approach provides an average speaker role identification accuracy of 83% for ATCO and pilot. Finally, we show that training AMs separately for each task, or using a multitask approach is well suited for this data compared to AM trained by pooling all data.