 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERTraffic: A Robust BERT-Based Approach for Speaker Change Detection and Role Identification of Air-Traffic Communications
Paper and Code
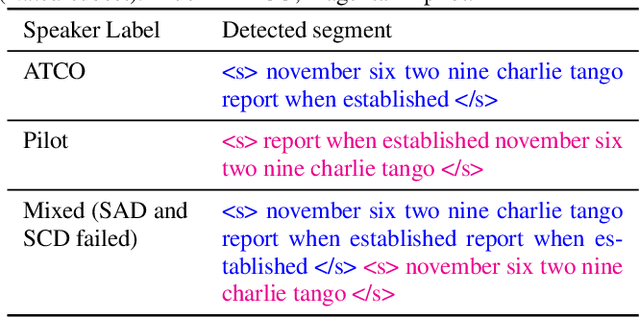
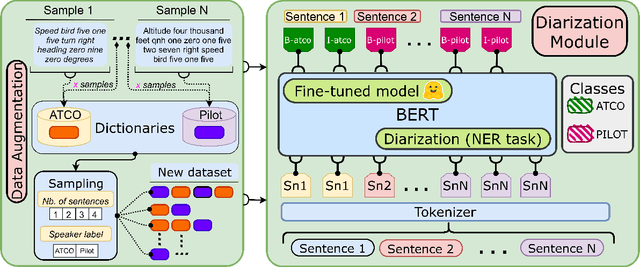
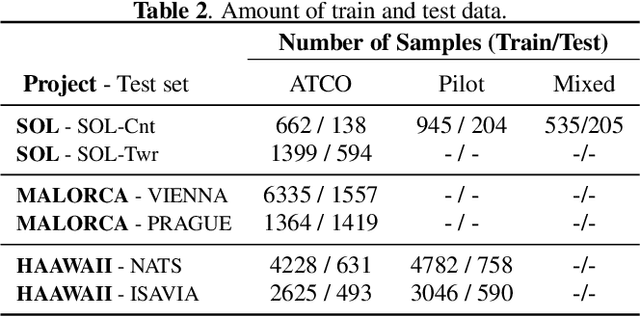
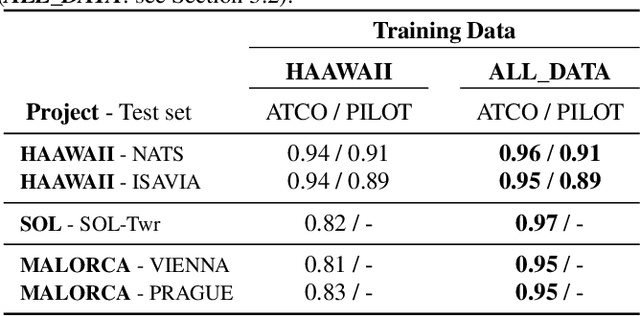
Automatic Speech Recognition (ASR) is gaining special interest in Air Traffic Control (ATC). ASR allows transcribing the communications between air traffic controllers (ATCOs) and pilots. These transcriptions are used to extract ATC command types and named entities such as aircraft callsigns. One common problem is when the Speech Activity Detection (SAD) or diarization system fails and then two or more single speaker segments are in the same recording, jeopardizing the overall system's performance. We developed a system that combines the segmentation of a SAD module with a BERT-based model that performs Speaker Change Detection (SCD) and Speaker Role Identification (SRI) based on ASR transcripts (i.e., diarization + SRI). This research demonstrates on a real-life ATC test set that performing diarization directly on textual data surpass acoustic level diarization. The proposed model reaches up to ~0.90/~0.95 F1-score on ATCO/pilot for SRI on several test sets. The text-based diarization system brings a 27% relative improvement on Diarization Error Rate (DER) compared to standard acoustic-based diarization. These results were on ASR transcripts of a challenging ATC test set with an estimated ~13% word error rate, validating the approach's robustness even on noisy ASR transcripts.