 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneration and Pruning of Pronunciation Variants to Improve ASR Accuracy
Paper and Code
Jun 28, 2016
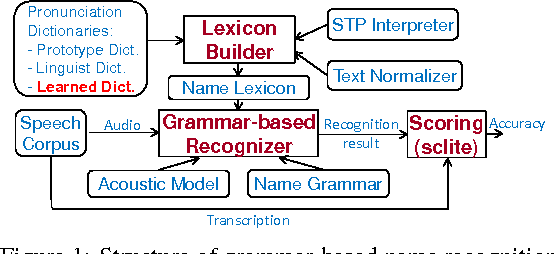
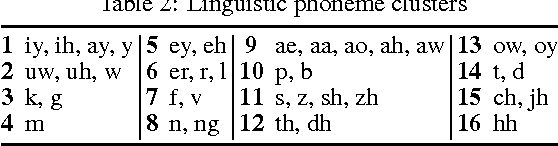
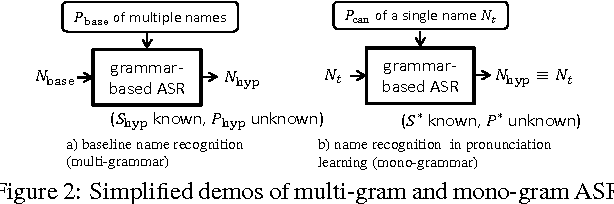
Speech recognition, especially name recognition, is widely used in phone services such as company directory dialers, stock quote providers or location finders. It is usually challenging due to pronunciation variations. This paper proposes an efficient and robust data-driven technique which automatically learns acceptable word pronunciations and updates the pronunciation dictionary to build a better lexicon without affecting recognition of other words similar to the target word. It generalizes well on datasets with various sizes, and reduces the error rate on a database with 13000+ human names by 42%, compared to a baseline with regular dictionaries already covering canonical pronunciations of 97%+ words in names, plus a well-trained spelling-to-pronunciation (STP) engine.