 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Tubes for Probabilistic Temporal Reach-Avoid-Stay Task in Uncertain Dynamic Environment
Dec 25, 2025In this work, we extend the Spatiotemporal Tube (STT) framework to address Probabilistic Temporal Reach-Avoid-Stay (PrT-RAS) tasks in dynamic environments with uncertain obstacles. We develop a real-time tube synthesis procedure that explicitly accounts for time-varying uncertain obstacles and provides formal probabilistic safety guarantees. The STT is formulated as a time-varying ball in the state space whose center and radius evolve online based on uncertain sensory information. We derive a closed-form, approximation-free control law that confines the system trajectory within the tube, ensuring both probabilistic safety and task satisfaction. Our method offers a formal guarantee for probabilistic avoidance and finite-time task completion. The resulting controller is model-free, approximation-free, and optimization-free, enabling efficient real-time execution while guaranteeing convergence to the target. The effectiveness and scalability of the framework are demonstrated through simulation studies and hardware experiments on mobile robots, a UAV, and a 7-DOF manipulator navigating in cluttered and uncertain environments.
Learning Spatiotemporal Tubes for Temporal Reach-Avoid-Stay Tasks using Physics-Informed Neural Networks
Dec 09, 2025This paper presents a Spatiotemporal Tube (STT)-based control framework for general control-affine MIMO nonlinear pure-feedback systems with unknown dynamics to satisfy prescribed time reach-avoid-stay tasks under external disturbances. The STT is defined as a time-varying ball, whose center and radius are jointly approximated by a Physics-Informed Neural Network (PINN). The constraints governing the STT are first formulated as loss functions of the PINN, and a training algorithm is proposed to minimize the overall violation. The PINN being trained on certain collocation points, we propose a Lipschitz-based validity condition to formally verify that the learned PINN satisfies the conditions over the continuous time horizon. Building on the learned STT representation, an approximation-free closed-form controller is defined to guarantee satisfaction of the T-RAS specification. Finally, the effectiveness and scalability of the framework are validated through two case studies involving a mobile robot and an aerial vehicle navigating through cluttered environments.
Signal Temporal Logic Compliant Co-design of Planning and Control
Jul 17, 2025

This work presents a novel co-design strategy that integrates trajectory planning and control to handle STL-based tasks in autonomous robots. The method consists of two phases: $(i)$ learning spatio-temporal motion primitives to encapsulate the inherent robot-specific constraints and $(ii)$ constructing an STL-compliant motion plan from these primitives. Initially, we employ reinforcement learning to construct a library of control policies that perform trajectories described by the motion primitives. Then, we map motion primitives to spatio-temporal characteristics. Subsequently, we present a sampling-based STL-compliant motion planning strategy tailored to meet the STL specification. The proposed model-free approach, which generates feasible STL-compliant motion plans across various environments, is validated on differential-drive and quadruped robots across various STL specifications. Demonstration videos are available at https://tinyurl.com/m6zp7rsm.
Approximation-free Control of Unknown Euler-Lagrangian Systems under Input Constraints
Jul 02, 2025In this paper, we present a novel funnel-based tracking control algorithm for robotic systems with unknown dynamics and prescribed input constraints. The Euler-Lagrange formulation, a common modeling approach for robotic systems, has been adopted in this study to address the trade-off between performance and actuator safety. We establish feasibility conditions that ensure tracking errors evolve within predefined funnel bounds while maintaining bounded control efforts, a crucial consideration for robots with limited actuation capabilities. We propose two approximation-free control strategies for scenarios where these conditions are violated: one actively corrects the error, and the other stops further deviation. Finally, we demonstrate the robust performance and safety of the approach through simulations and experimental validations. This work represents a significant advancement in funnel-based control, enhancing its applicability to real-world robotics systems with input constraints.
Control Barrier Functions for Prescribed-time Reach-Avoid-Stay Tasks using Spatiotemporal Tubes
Mar 11, 2025Prescribed-time reach-avoid-stay (PT-RAS) specifications are crucial in applications requiring precise timing, state constraints, and safety guarantees. While control carrier functions (CBFs) have emerged as a promising approach, providing formal guarantees of safety, constructing CBFs that satisfy PT-RAS specifications remains challenging. In this paper, we present a novel approach using a spatiotemporal tubes (STTs) framework to construct CBFs for PT-RAS tasks. The STT framework allows for the systematic design of CBFs that dynamically manage both spatial and temporal constraints, ensuring the system remains within a safe operational envelope while achieving the desired temporal objectives. The proposed method is validated with two case studies: temporal motion planning of an omnidirectional robot and temporal waypoint navigation of a drone with obstacles, using higher-order CBFs.
Spatiotemporal Tubes for Temporal Reach-Avoid-Stay Tasks in Unknown Systems
Nov 21, 2024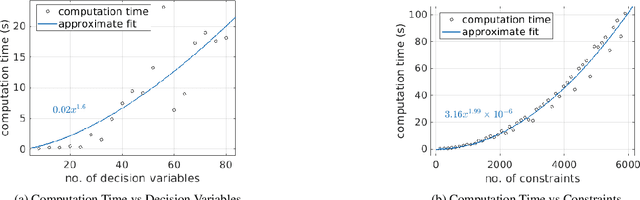

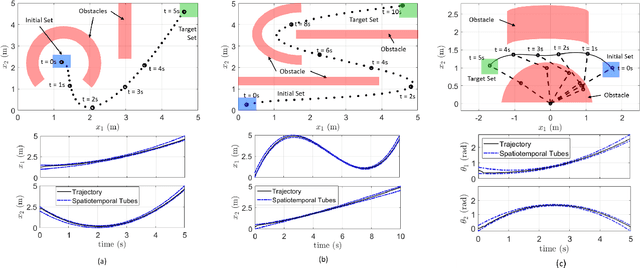
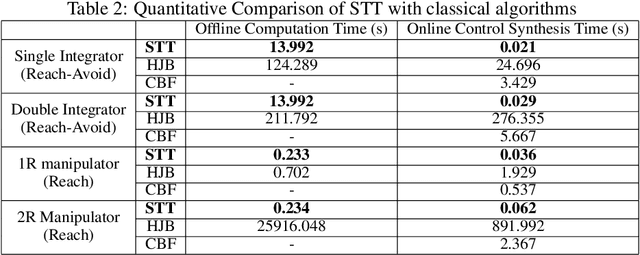
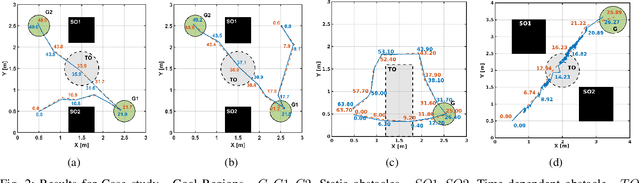
The paper considers the controller synthesis problem for general MIMO systems with unknown dynamics, aiming to fulfill the temporal reach-avoid-stay task, where the unsafe regions are time-dependent, and the target must be reached within a specified time frame. The primary aim of the paper is to construct the spatiotemporal tube (STT) using a sampling-based approach and thereby devise a closed-form approximation-free control strategy to ensure that system trajectory reaches the target set while avoiding time-dependent unsafe sets. The proposed scheme utilizes a novel method involving STTs to provide controllers that guarantee both system safety and reachability. In our sampling-based framework, we translate the requirements of STTs into a Robust optimization program (ROP). To address the infeasibility of ROP caused by infinite constraints, we utilize the sampling-based Scenario optimization program (SOP). Subsequently, we solve the SOP to generate the tube and closed-form controller for an unknown system, ensuring the temporal reach-avoid-stay specification. Finally, the effectiveness of the proposed approach is demonstrated through three case studies: an omnidirectional robot, a SCARA manipulator, and a magnetic levitation system.
RRT* Based Optimal Trajectory Generation with Linear Temporal Logic Specifications under Kinodynamic Constraints
Nov 09, 2024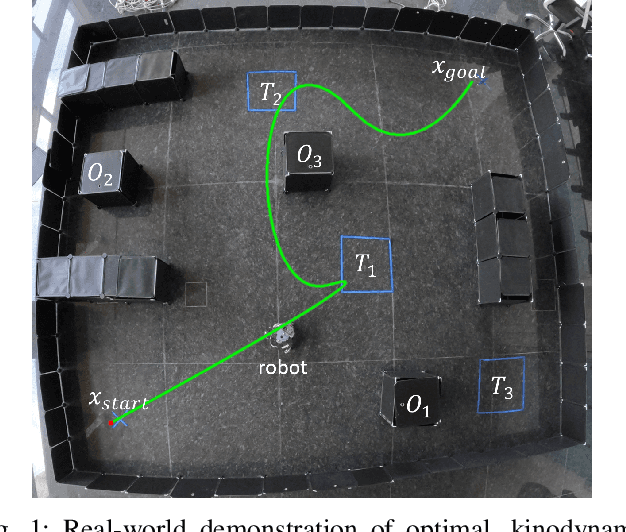
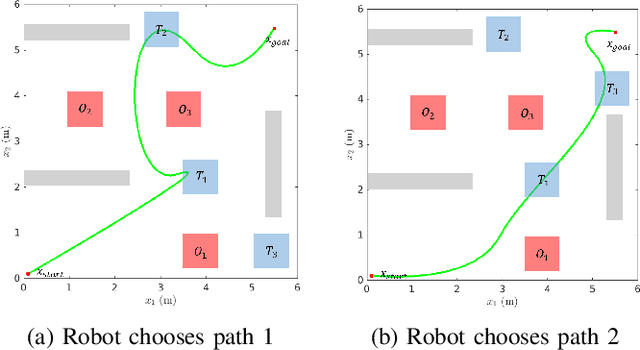
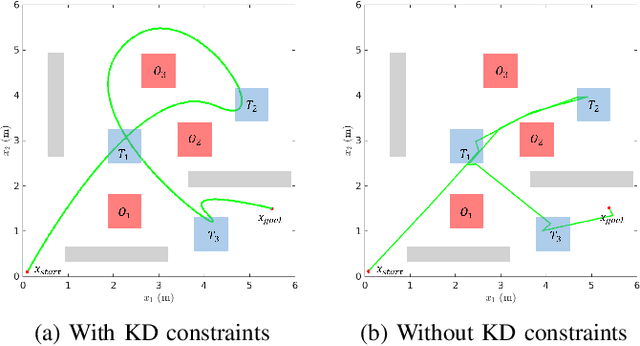
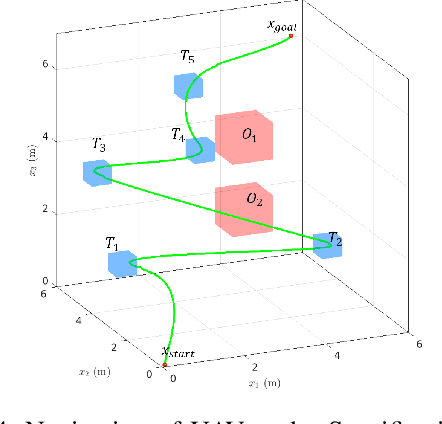
In this paper, we present a novel RRT*-based strategy for generating kinodynamically feasible paths that satisfy temporal logic specifications. Our approach integrates a robustness metric for Linear Temporal Logics (LTL) with the system's motion constraints, ensuring that the resulting trajectories are both optimal and executable. We introduce a cost function that recursively computes the robustness of temporal logic specifications while penalizing time and control effort, striking a balance between path feasibility and logical correctness. We validate our approach with simulations and real-world experiments in complex environments, demonstrating its effectiveness in producing robust and practical motion plans. This work represents a significant step towards expanding the applicability of motion planning algorithms to more complex, real-world scenarios.
Real Time Safety of Fixed-wing UAVs using Collision Cone Control Barrier Functions
Jul 27, 2024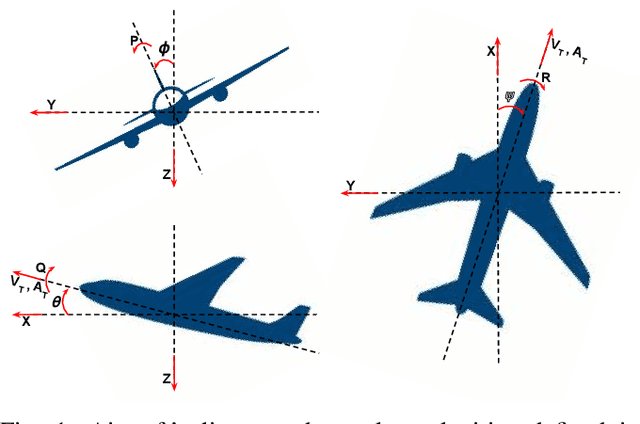
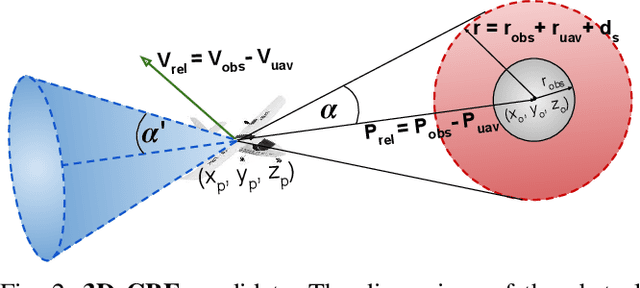
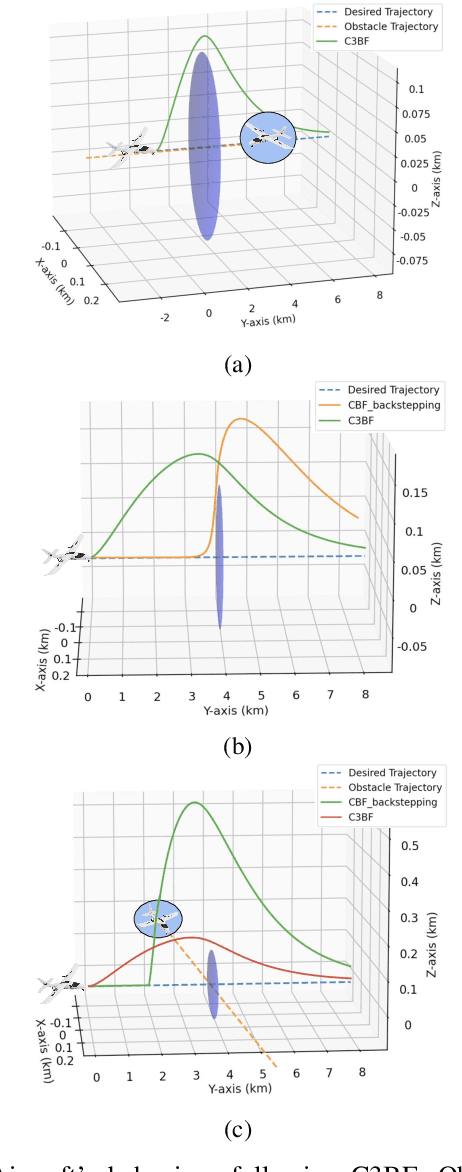
Fixed-wing UAVs have transformed the transportation system with their high flight speed and long endurance, yet their safe operation in increasingly cluttered environments depends heavily on effective collision avoidance techniques. This paper presents a novel method for safely navigating an aircraft along a desired route while avoiding moving obstacles. We utilize a class of control barrier functions (CBFs) based on collision cones to ensure the relative velocity between the aircraft and the obstacle consistently avoids a cone of vectors that might lead to a collision. By demonstrating that the proposed constraint is a valid CBF for the aircraft, we can leverage its real-time implementation via Quadratic Programs (QPs), termed the CBF-QPs. Validation includes simulating control law along trajectories, showing effectiveness in both static and moving obstacle scenarios.
Learning a Formally Verified Control Barrier Function in Stochastic Environment
Mar 28, 2024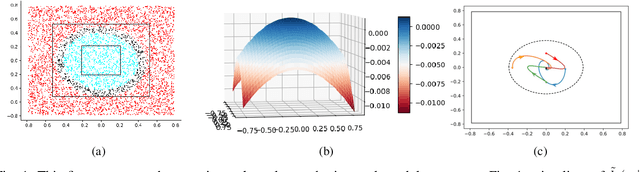
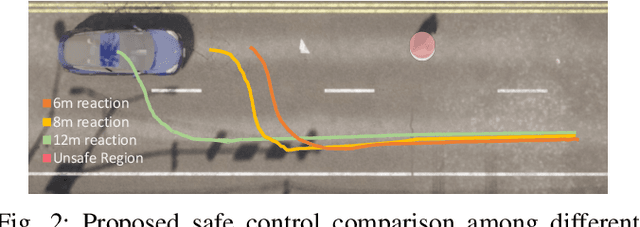
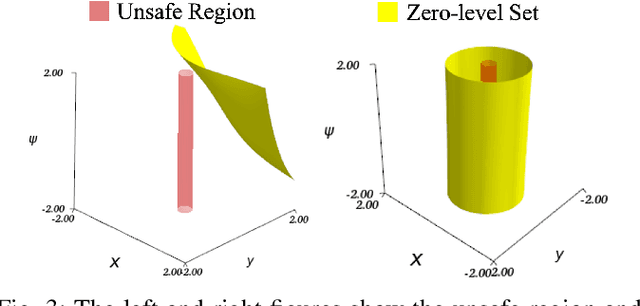
Safety is a fundamental requirement of control systems. Control Barrier Functions (CBFs) are proposed to ensure the safety of the control system by constructing safety filters or synthesizing control inputs. However, the safety guarantee and performance of safe controllers rely on the construction of valid CBFs. Inspired by universal approximatability, CBFs are represented by neural networks, known as neural CBFs (NCBFs). This paper presents an algorithm for synthesizing formally verified continuous-time neural Control Barrier Functions in stochastic environments in a single step. The proposed training process ensures efficacy across the entire state space with only a finite number of data points by constructing a sample-based learning framework for Stochastic Neural CBFs (SNCBFs). Our methodology eliminates the need for post hoc verification by enforcing Lipschitz bounds on the neural network, its Jacobian, and Hessian terms. We demonstrate the effectiveness of our approach through case studies on the inverted pendulum system and obstacle avoidance in autonomous driving, showcasing larger safe regions compared to baseline methods.
A Collision Cone Approach for Control Barrier Functions
Mar 11, 2024
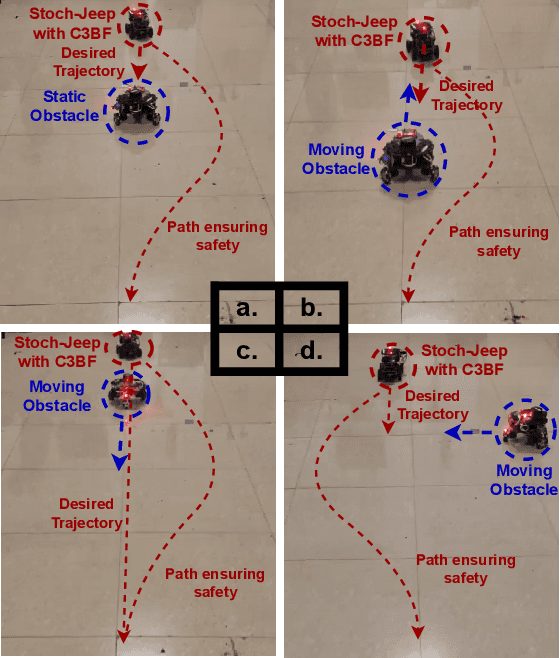
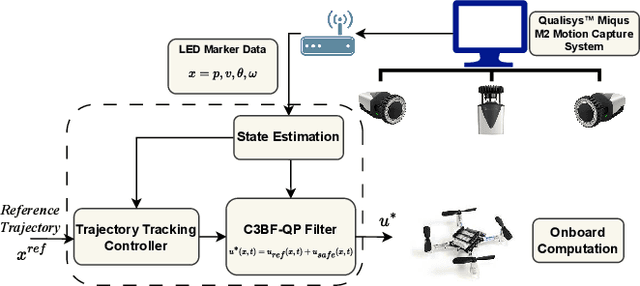
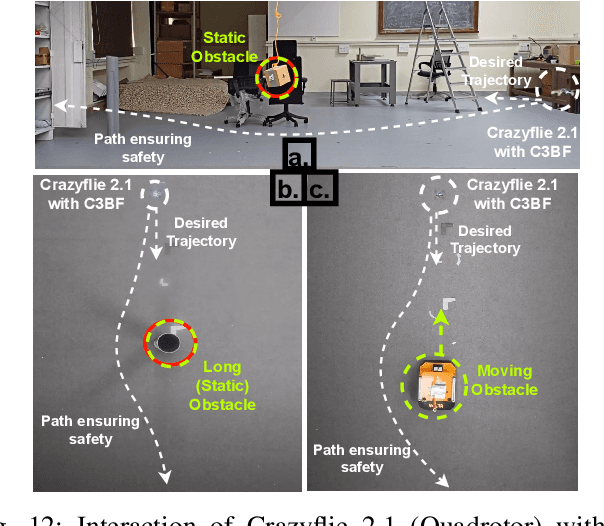
This work presents a unified approach for collision avoidance using Collision-Cone Control Barrier Functions (CBFs) in both ground (UGV) and aerial (UAV) unmanned vehicles. We propose a novel CBF formulation inspired by collision cones, to ensure safety by constraining the relative velocity between the vehicle and the obstacle to always point away from each other. The efficacy of this approach is demonstrated through simulations and hardware implementations on the TurtleBot, Stoch-Jeep, and Crazyflie 2.1 quadrotor robot, showcasing its effectiveness in avoiding collisions with dynamic obstacles in both ground and aerial settings. The real-time controller is developed using CBF Quadratic Programs (CBF-QPs). Comparative analysis with the state-of-the-art CBFs highlights the less conservative nature of the proposed approach. Overall, this research contributes to a novel control formation that can give a guarantee for collision avoidance in unmanned vehicles by modifying the control inputs from existing path-planning controllers.