 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Specific Author Attribution Based on Feedforward Neural Network Language Models
Feb 24, 2016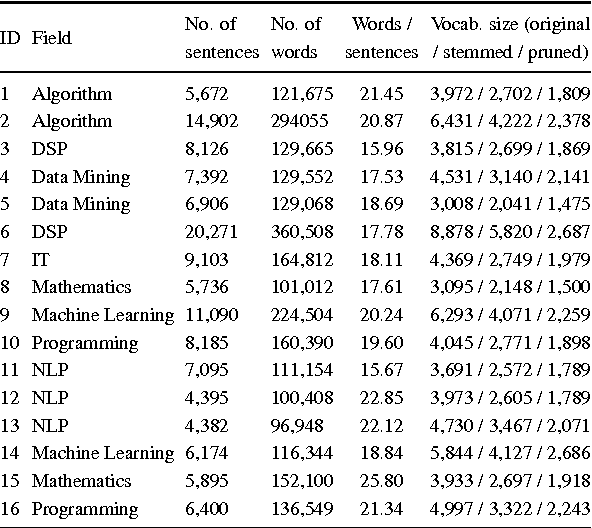
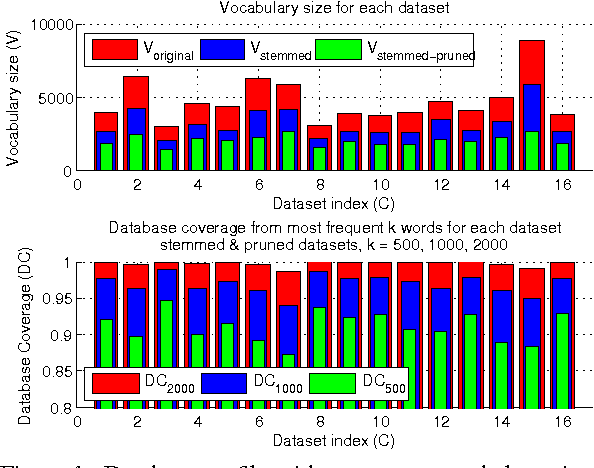
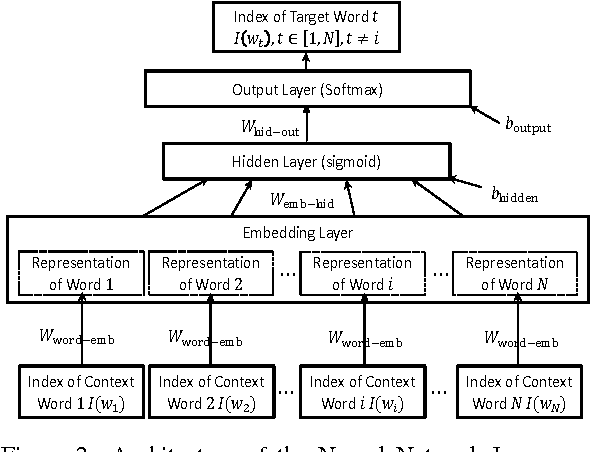
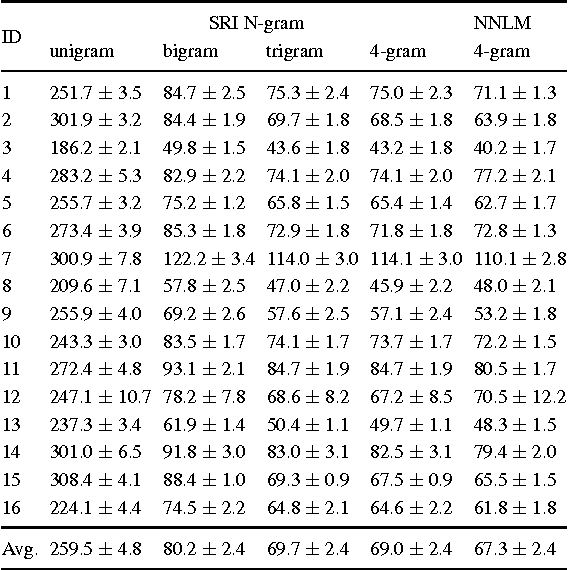
Authorship attribution refers to the task of automatically determining the author based on a given sample of text. It is a problem with a long history and has a wide range of application. Building author profiles using language models is one of the most successful methods to automate this task. New language modeling methods based on neural networks alleviate the curse of dimensionality and usually outperform conventional N-gram methods. However, there have not been much research applying them to authorship attribution. In this paper, we present a novel setup of a Neural Network Language Model (NNLM) and apply it to a database of text samples from different authors. We investigate how the NNLM performs on a task with moderate author set size and relatively limited training and test data, and how the topics of the text samples affect the accuracy. NNLM achieves nearly 2.5% reduction in perplexity, a measurement of fitness of a trained language model to the test data. Given 5 random test sentences, it also increases the author classification accuracy by 3.43% on average, compared with the N-gram methods using SRILM tools. An open source implementation of our methodology is freely available at https://github.com/zge/authorship-attribution/.
Authorship Attribution Using a Neural Network Language Model
Feb 17, 2016
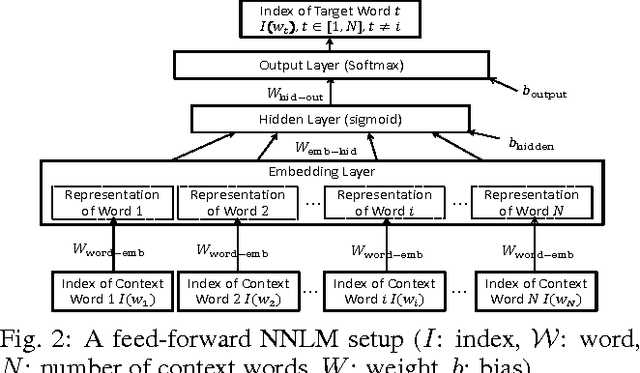
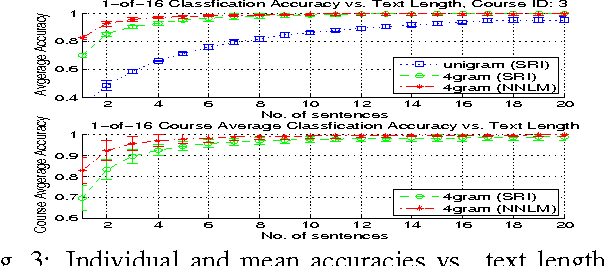
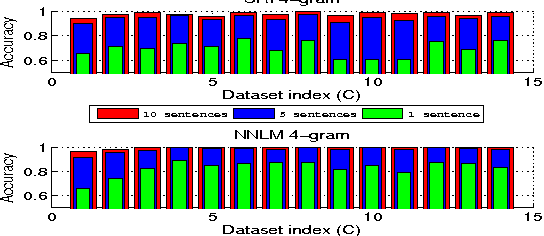
In practice, training language models for individual authors is often expensive because of limited data resources. In such cases, Neural Network Language Models (NNLMs), generally outperform the traditional non-parametric N-gram models. Here we investigate the performance of a feed-forward NNLM on an authorship attribution problem, with moderate author set size and relatively limited data. We also consider how the text topics impact performance. Compared with a well-constructed N-gram baseline method with Kneser-Ney smoothing, the proposed method achieves nearly 2:5% reduction in perplexity and increases author classification accuracy by 3:43% on average, given as few as 5 test sentences. The performance is very competitive with the state of the art in terms of accuracy and demand on test data. The source code, preprocessed datasets, a detailed description of the methodology and results are available at https://github.com/zge/authorship-attribution.