 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Frequency Cepstral Coefficients for Word Mispronunciation Detection
Feb 25, 2016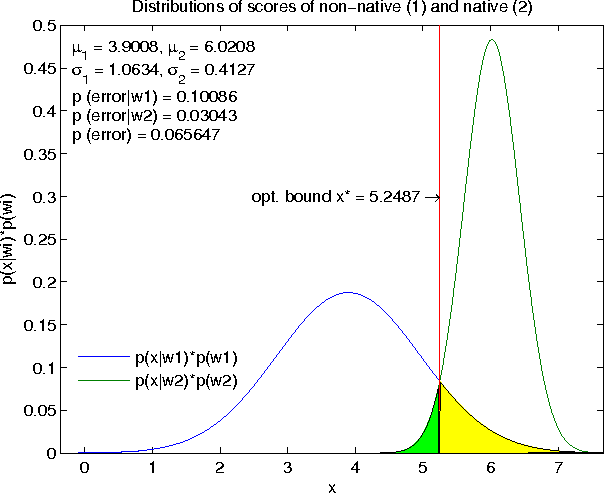
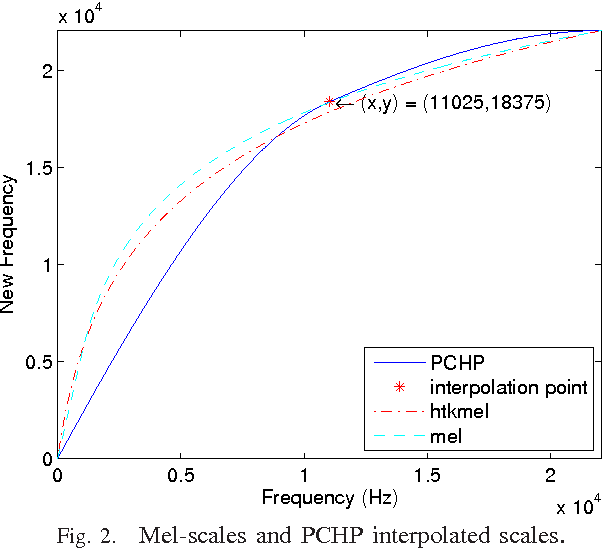
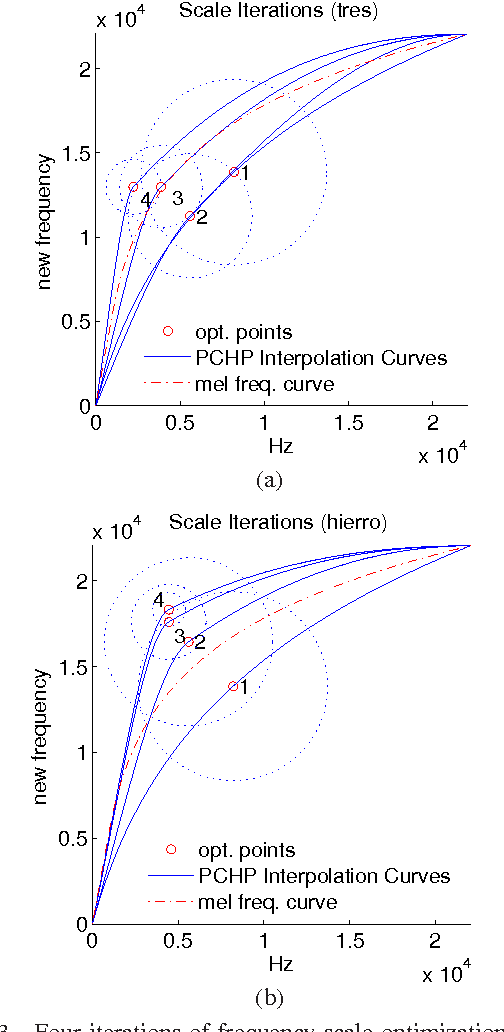
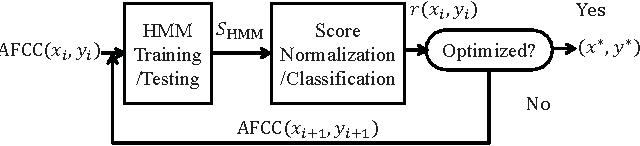
Systems based on automatic speech recognition (ASR) technology can provide important functionality in computer assisted language learning applications. This is a young but growing area of research motivated by the large number of students studying foreign languages. Here we propose a Hidden Markov Model (HMM)-based method to detect mispronunciations. Exploiting the specific dialog scripting employed in language learning software, HMMs are trained for different pronunciations. New adaptive features have been developed and obtained through an adaptive warping of the frequency scale prior to computing the cepstral coefficients. The optimization criterion used for the warping function is to maximize separation of two major groups of pronunciations (native and non-native) in terms of classification rate. Experimental results show that the adaptive frequency scale yields a better coefficient representation leading to higher classification rates in comparison with conventional HMMs using Mel-frequency cepstral coefficients.
PCA Method for Automated Detection of Mispronounced Words
Feb 25, 2016This paper presents a method for detecting mispronunciations with the aim of improving Computer Assisted Language Learning (CALL) tools used by foreign language learners. The algorithm is based on Principle Component Analysis (PCA). It is hierarchical with each successive step refining the estimate to classify the test word as being either mispronounced or correct. Preprocessing before detection, like normalization and time-scale modification, is implemented to guarantee uniformity of the feature vectors input to the detection system. The performance using various features including spectrograms and Mel-Frequency Cepstral Coefficients (MFCCs) are compared and evaluated. Best results were obtained using MFCCs, achieving up to 99% accuracy in word verification and 93% in native/non-native classification. Compared with Hidden Markov Models (HMMs) which are used pervasively in recognition application, this particular approach is computational efficient and effective when training data is limited.
PCA/LDA Approach for Text-Independent Speaker Recognition
Feb 25, 2016Various algorithms for text-independent speaker recognition have been developed through the decades, aiming to improve both accuracy and efficiency. This paper presents a novel PCA/LDA-based approach that is faster than traditional statistical model-based methods and achieves competitive results. First, the performance based on only PCA and only LDA is measured; then a mixed model, taking advantages of both methods, is introduced. A subset of the TIMIT corpus composed of 200 male speakers, is used for enrollment, validation and testing. The best results achieve 100%; 96% and 95% classification rate at population level 50; 100 and 200, using 39-dimensional MFCC features with delta and double delta. These results are based on 12-second text-independent speech for training and 4-second data for test. These are comparable to the conventional MFCC-GMM methods, but require significantly less time to train and operate.
Authorship Attribution Using a Neural Network Language Model
Feb 17, 2016
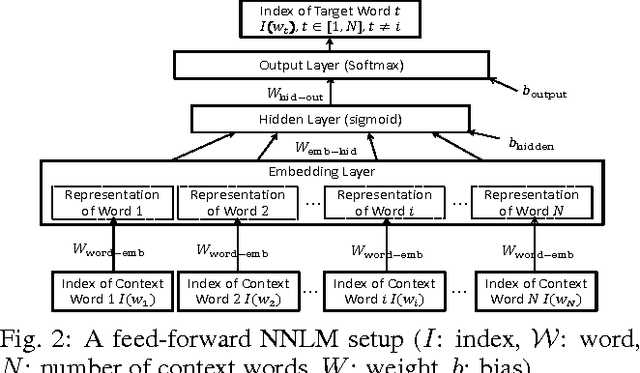
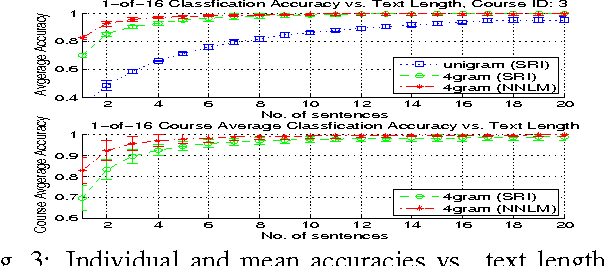
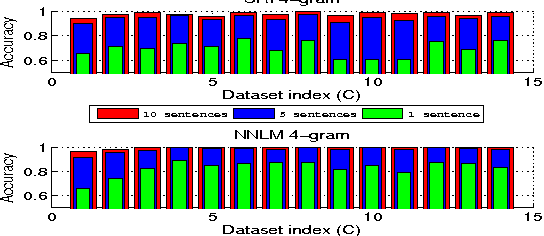
In practice, training language models for individual authors is often expensive because of limited data resources. In such cases, Neural Network Language Models (NNLMs), generally outperform the traditional non-parametric N-gram models. Here we investigate the performance of a feed-forward NNLM on an authorship attribution problem, with moderate author set size and relatively limited data. We also consider how the text topics impact performance. Compared with a well-constructed N-gram baseline method with Kneser-Ney smoothing, the proposed method achieves nearly 2:5% reduction in perplexity and increases author classification accuracy by 3:43% on average, given as few as 5 test sentences. The performance is very competitive with the state of the art in terms of accuracy and demand on test data. The source code, preprocessed datasets, a detailed description of the methodology and results are available at https://github.com/zge/authorship-attribution.