 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning for End-to-End ASR by Averaging Domain Experts
May 12, 2023Continual learning for end-to-end automatic speech recognition has to contend with a number of difficulties. Fine-tuning strategies tend to lose performance on data already seen, a process known as catastrophic forgetting. On the other hand, strategies that freeze parameters and append tunable parameters must maintain multiple models. We suggest a strategy that maintains only a single model for inference and avoids catastrophic forgetting. Our experiments show that a simple linear interpolation of several models' parameters, each fine-tuned from the same generalist model, results in a single model that performs well on all tested data. For our experiments we selected two open-source end-to-end speech recognition models pre-trained on large datasets and fine-tuned them on 3 separate datasets: SGPISpeech, CORAAL, and DiPCo. The proposed average of domain experts model performs well on all tested data, and has almost no loss in performance on data from the domain of original training.
Temporal Attentive Alignment for Large-Scale Video Domain Adaptation
Sep 15, 2019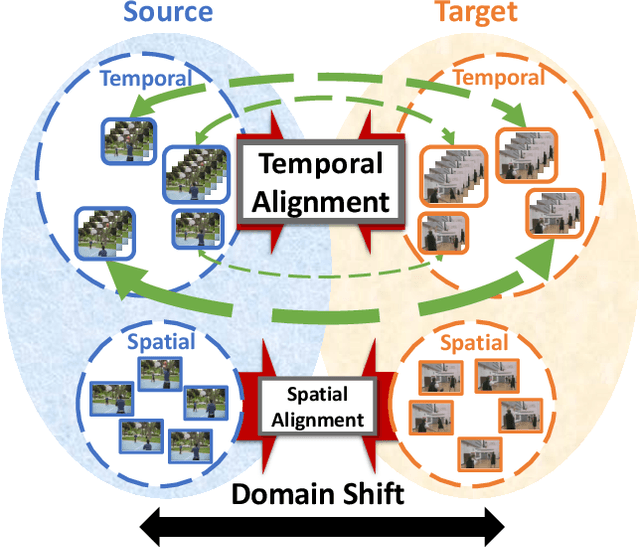

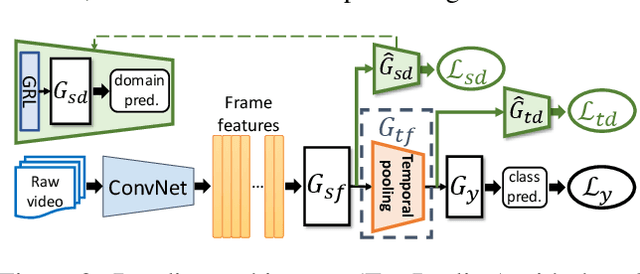
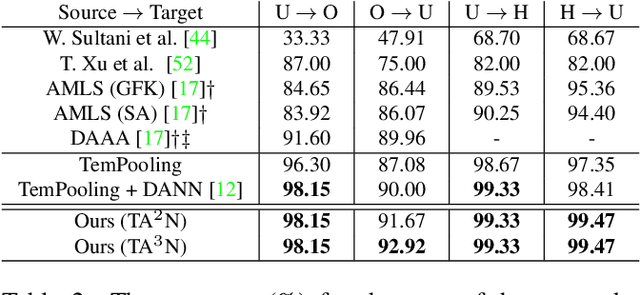
Although various image-based domain adaptation (DA) techniques have been proposed in recent years, domain shift in videos is still not well-explored. Most previous works only evaluate performance on small-scale datasets which are saturated. Therefore, we first propose two large-scale video DA datasets with much larger domain discrepancy: UCF-HMDB_full and Kinetics-Gameplay. Second, we investigate different DA integration methods for videos, and show that simultaneously aligning and learning temporal dynamics achieves effective alignment even without sophisticated DA methods. Finally, we propose Temporal Attentive Adversarial Adaptation Network (TA3N), which explicitly attends to the temporal dynamics using domain discrepancy for more effective domain alignment, achieving state-of-the-art performance on four video DA datasets (e.g. 7.9% accuracy gain over "Source only" from 73.9% to 81.8% on "HMDB --> UCF", and 10.3% gain on "Kinetics --> Gameplay"). The code and data are released at http://github.com/cmhungsteve/TA3N.