 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Cluster-Based Speaker Adaptive Training for Deep Neural Network Acoustic Modeling
Paper and Code
Apr 20, 2016
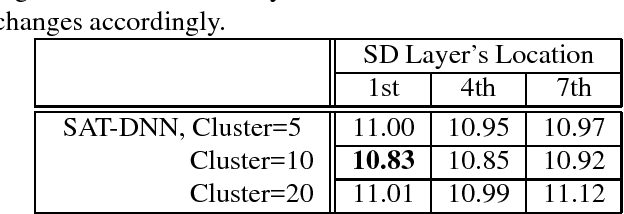

A speaker cluster-based speaker adaptive training (SAT) method under deep neural network-hidden Markov model (DNN-HMM) framework is presented in this paper. During training, speakers that are acoustically adjacent to each other are hierarchically clustered using an i-vector based distance metric. DNNs with speaker dependent layers are then adaptively trained for each cluster of speakers. Before decoding starts, an unseen speaker in test set is matched to the closest speaker cluster through comparing i-vector based distances. The previously trained DNN of the matched speaker cluster is used for decoding utterances of the test speaker. The performance of the proposed method on a large vocabulary spontaneous speech recognition task is evaluated on a training set of with 1500 hours of speech, and a test set of 24 speakers with 1774 utterances. Comparing to a speaker independent DNN with a baseline word error rate of 11.6%, a relative 6.8% reduction in word error rate is observed from the proposed method.