 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge(FL)$^2$: Overcoming Few Labels in Federated Semi-Supervised Learning
Oct 31, 2024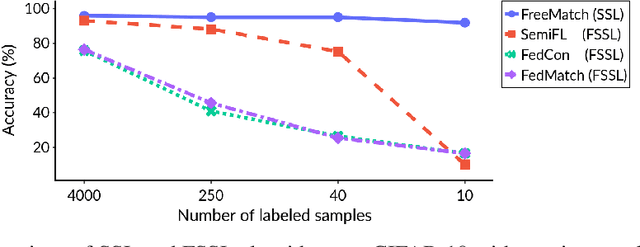
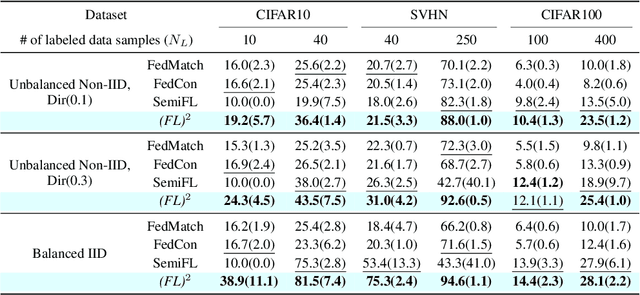
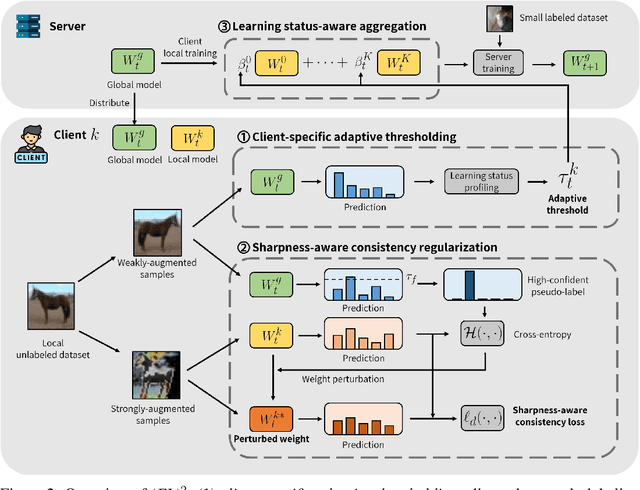

Federated Learning (FL) is a distributed machine learning framework that trains accurate global models while preserving clients' privacy-sensitive data. However, most FL approaches assume that clients possess labeled data, which is often not the case in practice. Federated Semi-Supervised Learning (FSSL) addresses this label deficiency problem, targeting situations where only the server has a small amount of labeled data while clients do not. However, a significant performance gap exists between Centralized Semi-Supervised Learning (SSL) and FSSL. This gap arises from confirmation bias, which is more pronounced in FSSL due to multiple local training epochs and the separation of labeled and unlabeled data. We propose $(FL)^2$, a robust training method for unlabeled clients using sharpness-aware consistency regularization. We show that regularizing the original pseudo-labeling loss is suboptimal, and hence we carefully select unlabeled samples for regularization. We further introduce client-specific adaptive thresholding and learning status-aware aggregation to adjust the training process based on the learning progress of each client. Our experiments on three benchmark datasets demonstrate that our approach significantly improves performance and bridges the gap with SSL, particularly in scenarios with scarce labeled data.
Federated Learning with Incomplete Sensing Modalities
May 20, 2024Many mobile sensing applications utilize data from various modalities, including motion and physiological sensors in mobile and wearable devices. Federated Learning (FL) is particularly suitable for these applications thanks to its privacy-preserving feature. However, challenges such as limited battery life, poor network conditions, and sensor malfunctions can restrict the use of all available modalities for local model training. Additionally, existing multimodal FL systems also struggle with scalability and efficiency as the number of modality sources increases. To address these issues, we introduce FLISM, a framework designed to enable multimodal FL with incomplete modalities. FLISM leverages simulation technique to learn robust representations that can handle missing modalities and transfers model knowledge across clients with varying set of modalities. The evaluation results using three real-world datasets and simulations demonstrate FLISM's effective balance between model performance and system efficiency. It shows an average improvement of .067 in F1-score, while also reducing communication (2.69x faster) and computational (2.28x more efficient) overheads compared to existing methods addressing incomplete modalities. Moreover, in simulated scenarios involving tasks with a larger number of modalities, FLISM achieves a significant speedup of 3.23x~85.10x in communication and 3.73x~32.29x in computational efficiency.
Not All Federated Learning Algorithms Are Created Equal: A Performance Evaluation Study
Mar 26, 2024



Federated Learning (FL) emerged as a practical approach to training a model from decentralized data. The proliferation of FL led to the development of numerous FL algorithms and mechanisms. Many prior efforts have given their primary focus on accuracy of those approaches, but there exists little understanding of other aspects such as computational overheads, performance and training stability, etc. To bridge this gap, we conduct extensive performance evaluation on several canonical FL algorithms (FedAvg, FedProx, FedYogi, FedAdam, SCAFFOLD, and FedDyn) by leveraging an open-source federated learning framework called Flame. Our comprehensive measurement study reveals that no single algorithm works best across different performance metrics. A few key observations are: (1) While some state-of-the-art algorithms achieve higher accuracy than others, they incur either higher computation overheads (FedDyn) or communication overheads (SCAFFOLD). (2) Recent algorithms present smaller standard deviation in accuracy across clients than FedAvg, indicating that the advanced algorithms' performances are stable. (3) However, algorithms such as FedDyn and SCAFFOLD are more prone to catastrophic failures without the support of additional techniques such as gradient clipping. We hope that our empirical study can help the community to build best practices in evaluating FL algorithms.
FedTherapist: Mental Health Monitoring with User-Generated Linguistic Expressions on Smartphones via Federated Learning
Oct 25, 2023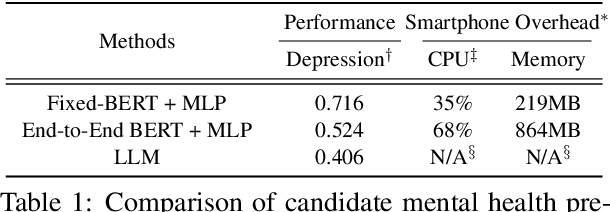
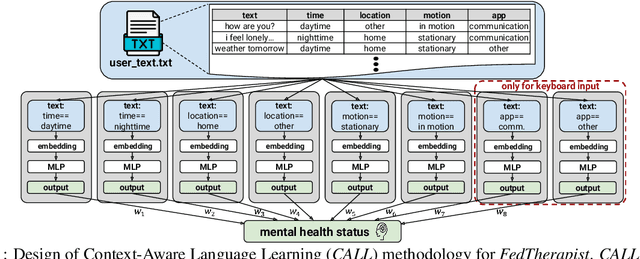
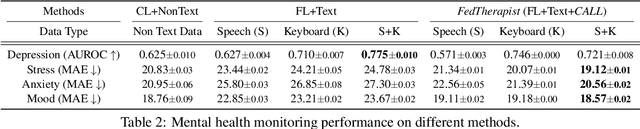
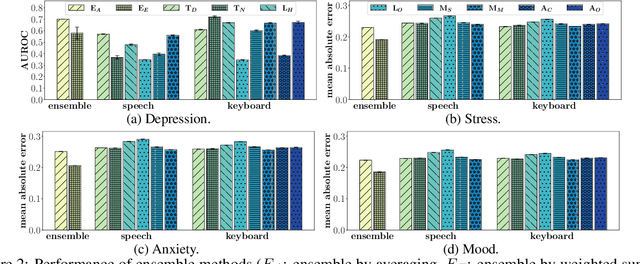
Psychiatrists diagnose mental disorders via the linguistic use of patients. Still, due to data privacy, existing passive mental health monitoring systems use alternative features such as activity, app usage, and location via mobile devices. We propose FedTherapist, a mobile mental health monitoring system that utilizes continuous speech and keyboard input in a privacy-preserving way via federated learning. We explore multiple model designs by comparing their performance and overhead for FedTherapist to overcome the complex nature of on-device language model training on smartphones. We further propose a Context-Aware Language Learning (CALL) methodology to effectively utilize smartphones' large and noisy text for mental health signal sensing. Our IRB-approved evaluation of the prediction of self-reported depression, stress, anxiety, and mood from 46 participants shows higher accuracy of FedTherapist compared with the performance with non-language features, achieving 0.15 AUROC improvement and 8.21% MAE reduction.
Federated Learning Operations Made Simple with Flame
May 09, 2023



Distributed machine learning approaches, including a broad class of federated learning techniques, present a number of benefits when deploying machine learning applications over widely distributed infrastructures. To realize the expected benefits, however, introduces substantial operational challenges due to required application and configuration-level changes related to deployment-specific details. Such complexities can be greatly reduced by introducing higher-level abstractions -- role and channel -- using which federated learning applications are described as Topology Abstraction Graphs (TAGs). TAGs decouple the ML application logic from the underlying deployment details, making it possible to specialize the application deployment, thus reducing development effort and paving the way for improved automation and tuning. We present Flame, the first system that supports these abstractions, and demonstrate its benefits for several use cases.
Sample Selection with Deadline Control for Efficient Federated Learning on Heterogeneous Clients
Jan 05, 2022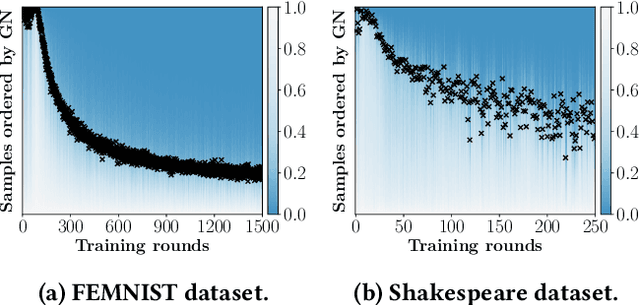
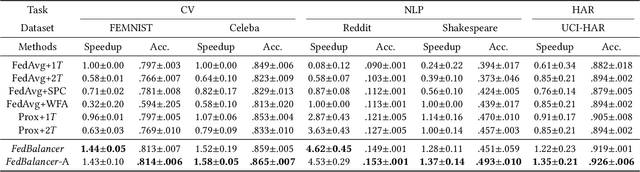
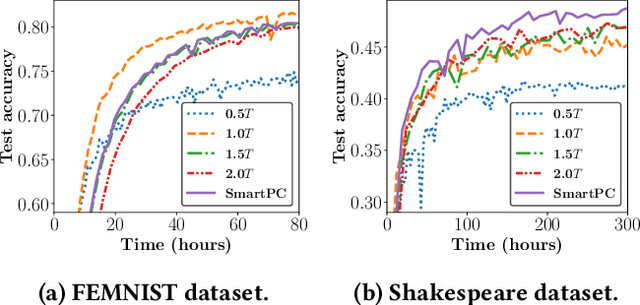
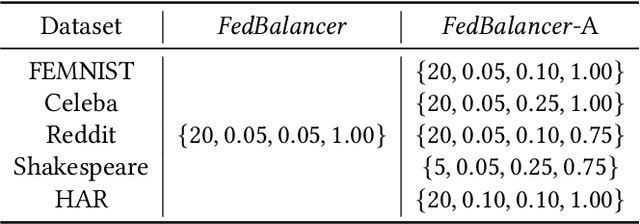
Federated Learning (FL) trains a machine learning model on distributed clients without exposing individual data. Unlike centralized training that is usually based on carefully-organized data, FL deals with on-device data that are often unfiltered and imbalanced. As a result, conventional FL training protocol that treats all data equally leads to a waste of local computational resources and slows down the global learning process. To this end, we propose FedBalancer, a systematic FL framework that actively selects clients' training samples. Our sample selection strategy prioritizes more "informative" data while respecting privacy and computational capabilities of clients. To better utilize the sample selection to speed up global training, we further introduce an adaptive deadline control scheme that predicts the optimal deadline for each round with varying client train data. Compared with existing FL algorithms with deadline configuration methods, our evaluation on five datasets from three different domains shows that FedBalancer improves the time-to-accuracy performance by 1.22~4.62x while improving the model accuracy by 1.0~3.3%. We also show that FedBalancer is readily applicable to other FL approaches by demonstrating that FedBalancer improves the convergence speed and accuracy when operating jointly with three different FL algorithms.