 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLynx: Enabling Efficient MoE Inference through Dynamic Batch-Aware Expert Selection
Nov 13, 2024



Mixture-of-Experts (MoE) architectures have recently gained popularity in enabling efficient scaling of large language models. However, we uncover a fundamental tension: while MoEs are designed for selective expert activation, production serving requires request batching, which forces the activation of all experts and negates MoE's efficiency benefits during the decode phase. We present Lynx, a system that enables efficient MoE inference through dynamic, batch-aware expert selection. Our key insight is that expert importance varies significantly across tokens and inference phases, creating opportunities for runtime optimization. Lynx leverages this insight through a lightweight framework that dynamically reduces active experts while preserving model accuracy. Our evaluations show that Lynx achieves up to 1.55x reduction in inference latency while maintaining negligible accuracy loss from baseline model across complex code generation and mathematical reasoning tasks.
Poster: Making Edge-assisted LiDAR Perceptions Robust to Lossy Point Cloud Compression
Sep 08, 2023

Real-time light detection and ranging (LiDAR) perceptions, e.g., 3D object detection and simultaneous localization and mapping are computationally intensive to mobile devices of limited resources and often offloaded on the edge. Offloading LiDAR perceptions requires compressing the raw sensor data, and lossy compression is used for efficiently reducing the data volume. Lossy compression degrades the quality of LiDAR point clouds, and the perception performance is decreased consequently. In this work, we present an interpolation algorithm improving the quality of a LiDAR point cloud to mitigate the perception performance loss due to lossy compression. The algorithm targets the range image (RI) representation of a point cloud and interpolates points at the RI based on depth gradients. Compared to existing image interpolation algorithms, our algorithm shows a better qualitative result when the point cloud is reconstructed from the interpolated RI. With the preliminary results, we also describe the next steps of the current work.
Federated Learning Operations Made Simple with Flame
May 09, 2023



Distributed machine learning approaches, including a broad class of federated learning techniques, present a number of benefits when deploying machine learning applications over widely distributed infrastructures. To realize the expected benefits, however, introduces substantial operational challenges due to required application and configuration-level changes related to deployment-specific details. Such complexities can be greatly reduced by introducing higher-level abstractions -- role and channel -- using which federated learning applications are described as Topology Abstraction Graphs (TAGs). TAGs decouple the ML application logic from the underlying deployment details, making it possible to specialize the application deployment, thus reducing development effort and paving the way for improved automation and tuning. We present Flame, the first system that supports these abstractions, and demonstrate its benefits for several use cases.
Canoe : A System for Collaborative Learning for Neural Nets
Aug 30, 2021


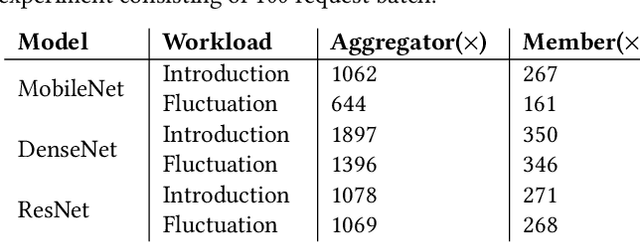
For highly distributed environments such as edge computing, collaborative learning approaches eschew the dependence on a global, shared model, in favor of models tailored for each location. Creating tailored models for individual learning contexts reduces the amount of data transfer, while collaboration among peers provides acceptable model performance. Collaboration assumes, however, the availability of knowledge transfer mechanisms, which are not trivial for deep learning models where knowledge isn't easily attributed to precise model slices. We present Canoe - a framework that facilitates knowledge transfer for neural networks. Canoe provides new system support for dynamically extracting significant parameters from a helper node's neural network and uses this with a multi-model boosting-based approach to improve the predictive performance of the target node. The evaluation of Canoe with different PyTorch and TensorFlow neural network models demonstrates that the knowledge transfer mechanism improves the model's adaptiveness to changes up to 3.5X compared to learning in isolation, while affording several magnitudes reduction in data movement costs compared to federated learning.