 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDid You Get What You Paid For? Rethinking Annotation Cost of Deep Learning Based Computer Aided Detection in Chest Radiographs
Sep 30, 2022As deep networks require large amounts of accurately labeled training data, a strategy to collect sufficiently large and accurate annotations is as important as innovations in recognition methods. This is especially true for building Computer Aided Detection (CAD) systems for chest X-rays where domain expertise of radiologists is required to annotate the presence and location of abnormalities on X-ray images. However, there lacks concrete evidence that provides guidance on how much resource to allocate for data annotation such that the resulting CAD system reaches desired performance. Without this knowledge, practitioners often fall back to the strategy of collecting as much detail as possible on as much data as possible which is cost inefficient. In this work, we investigate how the cost of data annotation ultimately impacts the CAD model performance on classification and segmentation of chest abnormalities in frontal-view X-ray images. We define the cost of annotation with respect to the following three dimensions: quantity, quality and granularity of labels. Throughout this study, we isolate the impact of each dimension on the resulting CAD model performance on detecting 10 chest abnormalities in X-rays. On a large scale training data with over 120K X-ray images with gold-standard annotations, we find that cost-efficient annotations provide great value when collected in large amounts and lead to competitive performance when compared to models trained with only gold-standard annotations. We also find that combining large amounts of cost efficient annotations with only small amounts of expensive labels leads to competitive CAD models at a much lower cost.
C2N: Practical Generative Noise Modeling for Real-World Denoising
Feb 19, 2022
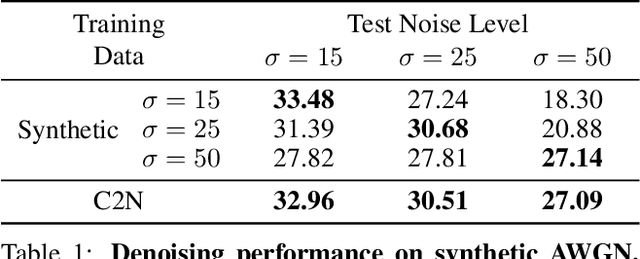
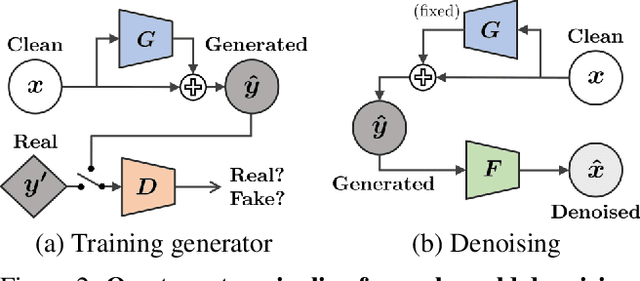

Learning-based image denoising methods have been bounded to situations where well-aligned noisy and clean images are given, or samples are synthesized from predetermined noise models, e.g., Gaussian. While recent generative noise modeling methods aim to simulate the unknown distribution of real-world noise, several limitations still exist. In a practical scenario, a noise generator should learn to simulate the general and complex noise distribution without using paired noisy and clean images. However, since existing methods are constructed on the unrealistic assumption of real-world noise, they tend to generate implausible patterns and cannot express complicated noise maps. Therefore, we introduce a Clean-to-Noisy image generation framework, namely C2N, to imitate complex real-world noise without using any paired examples. We construct the noise generator in C2N accordingly with each component of real-world noise characteristics to express a wide range of noise accurately. Combined with our C2N, conventional denoising CNNs can be trained to outperform existing unsupervised methods on challenging real-world benchmarks by a large margin.