 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Surprising Effectiveness of Masking Updates in Adaptive Optimizers
Feb 17, 2026Training large language models (LLMs) relies almost exclusively on dense adaptive optimizers with increasingly sophisticated preconditioners. We challenge this by showing that randomly masking parameter updates can be highly effective, with a masked variant of RMSProp consistently outperforming recent state-of-the-art optimizers. Our analysis reveals that the random masking induces a curvature-dependent geometric regularization that smooths the optimization trajectory. Motivated by this finding, we introduce Momentum-aligned gradient masking (Magma), which modulates the masked updates using momentum-gradient alignment. Extensive LLM pre-training experiments show that Magma is a simple drop-in replacement for adaptive optimizers with consistent gains and negligible computational overhead. Notably, for the 1B model size, Magma reduces perplexity by over 19\% and 9\% compared to Adam and Muon, respectively.
Scale Invariant Power Iteration
May 23, 2019
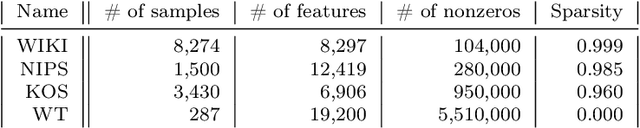
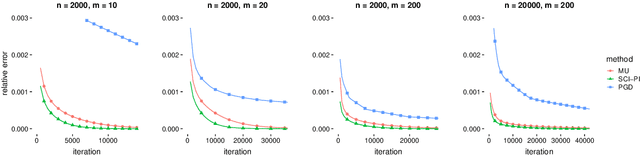
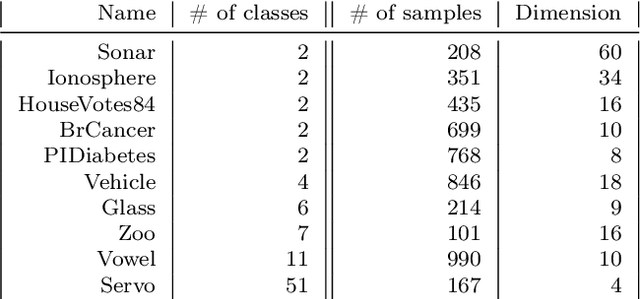
Power iteration has been generalized to solve many interesting problems in machine learning and statistics. Despite its striking success, theoretical understanding of when and how such an algorithm enjoys good convergence property is limited. In this work, we introduce a new class of optimization problems called scale invariant problems and prove that they can be efficiently solved by scale invariant power iteration (SCI-PI) with a generalized convergence guarantee of power iteration. By deriving that a stationary point is an eigenvector of the Hessian evaluated at the point, we show that scale invariant problems indeed resemble the leading eigenvector problem near a local optimum. Also, based on a novel reformulation, we geometrically derive SCI-PI which has a general form of power iteration. The convergence analysis shows that SCI-PI attains local linear convergence with a rate being proportional to the top two eigenvalues of the Hessian at the optimum. Moreover, we discuss some extended settings of scale invariant problems and provide similar convergence results for them. In numerical experiments, we introduce applications to independent component analysis, Gaussian mixtures, and non-negative matrix factorization. Experimental results demonstrate that SCI-PI is competitive to state-of-the-art benchmark algorithms and often yield better solutions.
L1-norm Kernel PCA
Sep 28, 2017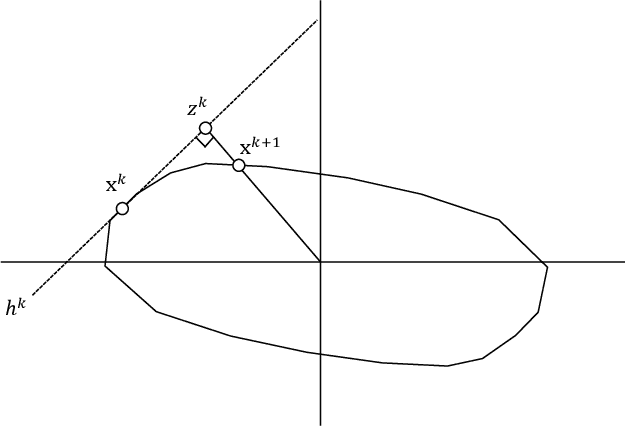
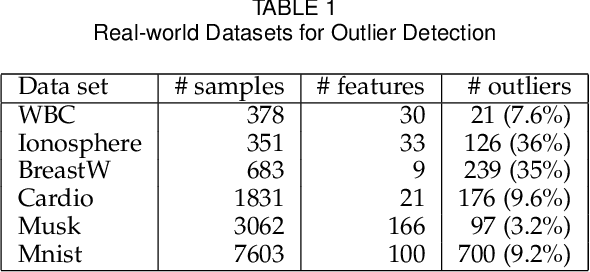
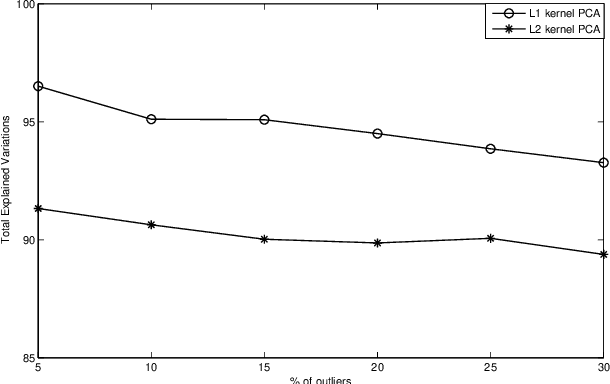
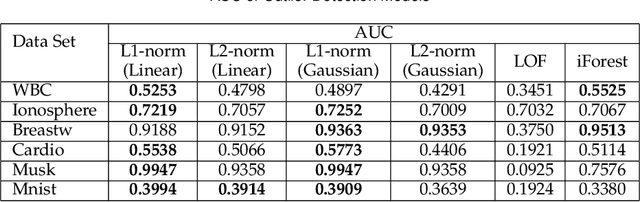
We present the first model and algorithm for L1-norm kernel PCA. While L2-norm kernel PCA has been widely studied, there has been no work on L1-norm kernel PCA. For this non-convex and non-smooth problem, we offer geometric understandings through reformulations and present an efficient algorithm where the kernel trick is applicable. To attest the efficiency of the algorithm, we provide a convergence analysis including linear rate of convergence. Moreover, we prove that the output of our algorithm is a local optimal solution to the L1-norm kernel PCA problem. We also numerically show its robustness when extracting principal components in the presence of influential outliers, as well as its runtime comparability to L2-norm kernel PCA. Lastly, we introduce its application to outlier detection and show that the L1-norm kernel PCA based model outperforms especially for high dimensional data.