 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo View Transform or Not to View Transform: NeRF-based Pre-training Perspective
Mar 30, 2026Neural radiance fields (NeRFs) have emerged as a prominent pre-training paradigm for vision-centric autonomous driving, which enhances 3D geometry and appearance understanding in a fully self-supervised manner. To apply NeRF-based pretraining to 3D perception models, recent approaches have simply applied NeRFs to volumetric features obtained from view transformation. However, coupling NeRFs with view transformation inherits conflicting priors; view transformation imposes discrete and rigid representations, whereas radiance fields assume continuous and adaptive functions. When these opposing assumptions are forced into a single pipeline, the misalignment surfaces as blurry and ambiguous 3D representations that ultimately limit 3D scene understanding. Moreover, the NeRF network for pre-training is discarded during downstream tasks, resulting in inefficient utilization of enhanced 3D representations through NeRF. In this paper, we propose a novel NeRF-Resembled Point-based 3D detector that can learn continuous 3D representation and thus avoid the misaligned priors from view transformation. NeRP3D preserves the pre-trained NeRF network regardless of the tasks, inheriting the principle of continuous 3D representation learning and leading to greater potentials for both scene reconstruction and detection tasks. Experiments on nuScenes dataset demonstrate that our proposed approach significantly improves previous state-of-the-art methods, outperforming not only pretext scene reconstruction tasks but also downstream detection tasks.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
REOcc: Camera-Radar Fusion with Radar Feature Enrichment for 3D Occupancy Prediction
Nov 10, 2025



Vision-based 3D occupancy prediction has made significant advancements, but its reliance on cameras alone struggles in challenging environments. This limitation has driven the adoption of sensor fusion, among which camera-radar fusion stands out as a promising solution due to their complementary strengths. However, the sparsity and noise of the radar data limits its effectiveness, leading to suboptimal fusion performance. In this paper, we propose REOcc, a novel camera-radar fusion network designed to enrich radar feature representations for 3D occupancy prediction. Our approach introduces two main components, a Radar Densifier and a Radar Amplifier, which refine radar features by integrating spatial and contextual information, effectively enhancing spatial density and quality. Extensive experiments on the Occ3D-nuScenes benchmark demonstrate that REOcc achieves significant performance gains over the camera-only baseline model, particularly in dynamic object classes. These results underscore REOcc's capability to mitigate the sparsity and noise of the radar data. Consequently, radar complements camera data more effectively, unlocking the full potential of camera-radar fusion for robust and reliable 3D occupancy prediction.
LabelDistill: Label-guided Cross-modal Knowledge Distillation for Camera-based 3D Object Detection
Jul 14, 2024



Recent advancements in camera-based 3D object detection have introduced cross-modal knowledge distillation to bridge the performance gap with LiDAR 3D detectors, leveraging the precise geometric information in LiDAR point clouds. However, existing cross-modal knowledge distillation methods tend to overlook the inherent imperfections of LiDAR, such as the ambiguity of measurements on distant or occluded objects, which should not be transferred to the image detector. To mitigate these imperfections in LiDAR teacher, we propose a novel method that leverages aleatoric uncertainty-free features from ground truth labels. In contrast to conventional label guidance approaches, we approximate the inverse function of the teacher's head to effectively embed label inputs into feature space. This approach provides additional accurate guidance alongside LiDAR teacher, thereby boosting the performance of the image detector. Additionally, we introduce feature partitioning, which effectively transfers knowledge from the teacher modality while preserving the distinctive features of the student, thereby maximizing the potential of both modalities. Experimental results demonstrate that our approach improves mAP and NDS by 5.1 points and 4.9 points compared to the baseline model, proving the effectiveness of our approach. The code is available at https://github.com/sanmin0312/LabelDistill
InstaGraM: Instance-level Graph Modeling for Vectorized HD Map Learning
Jan 10, 2023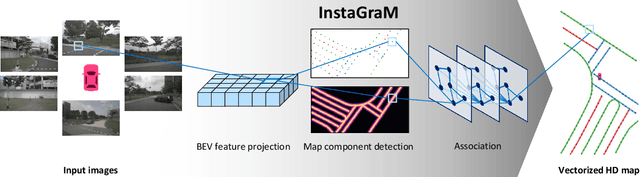
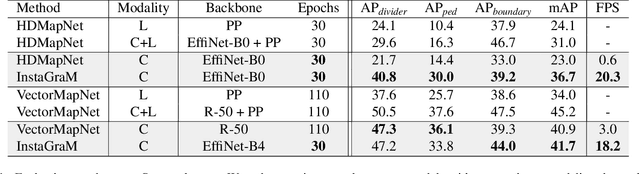
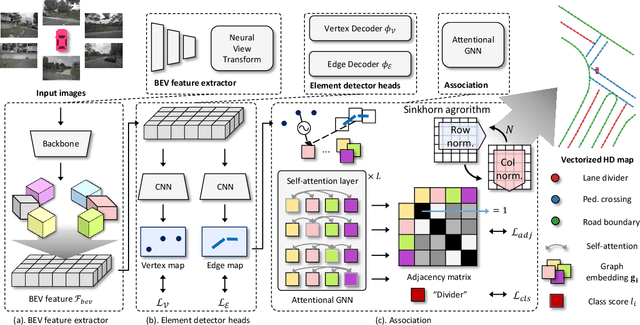
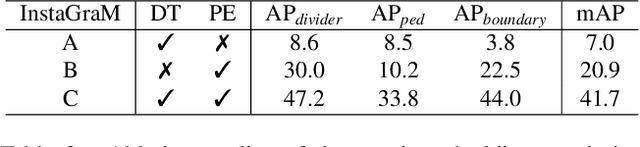
The construction of lightweight High-definition (HD) maps containing geometric and semantic information is of foremost importance for the large-scale deployment of autonomous driving. To automatically generate such type of map from a set of images captured by a vehicle, most works formulate this mapping as a segmentation problem, which implies heavy post-processing to obtain the final vectorized representation. Alternative techniques have the ability to generate an HD map in an end-to-end manner but rely on computationally expensive auto-regressive models. To bring camera-based to an applicable level, we propose InstaGraM, a fast end-to-end network generating a vectorized HD map via instance-level graph modeling of the map elements. Our strategy consists of three main stages: top-view feature extraction, road elements' vertices and edges detection, and conversion to a semantic vector representation. After top-down feature extraction, an encoder-decoder architecture is utilized to predict a set of vertices and edge maps of the road elements. Finally, these vertices along with edge maps are associated through an attentional graph neural network generating a semantic vectorized map. Instead of relying on a common segmentation approach, we propose to regress distance transform maps as they provide strong spatial relations and directional information between vertices. Comprehensive experiments on nuScenes dataset show that our proposed network outperforms HDMapNet by 13.7 mAP and achieves comparable accuracy with VectorMapNet 5x faster inference speed.