 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREOcc: Camera-Radar Fusion with Radar Feature Enrichment for 3D Occupancy Prediction
Nov 10, 2025



Vision-based 3D occupancy prediction has made significant advancements, but its reliance on cameras alone struggles in challenging environments. This limitation has driven the adoption of sensor fusion, among which camera-radar fusion stands out as a promising solution due to their complementary strengths. However, the sparsity and noise of the radar data limits its effectiveness, leading to suboptimal fusion performance. In this paper, we propose REOcc, a novel camera-radar fusion network designed to enrich radar feature representations for 3D occupancy prediction. Our approach introduces two main components, a Radar Densifier and a Radar Amplifier, which refine radar features by integrating spatial and contextual information, effectively enhancing spatial density and quality. Extensive experiments on the Occ3D-nuScenes benchmark demonstrate that REOcc achieves significant performance gains over the camera-only baseline model, particularly in dynamic object classes. These results underscore REOcc's capability to mitigate the sparsity and noise of the radar data. Consequently, radar complements camera data more effectively, unlocking the full potential of camera-radar fusion for robust and reliable 3D occupancy prediction.
CRN: Camera Radar Net for Accurate, Robust, Efficient 3D Perception
Apr 03, 2023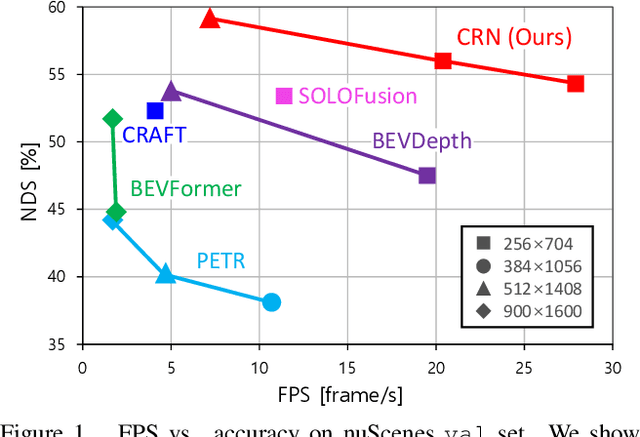
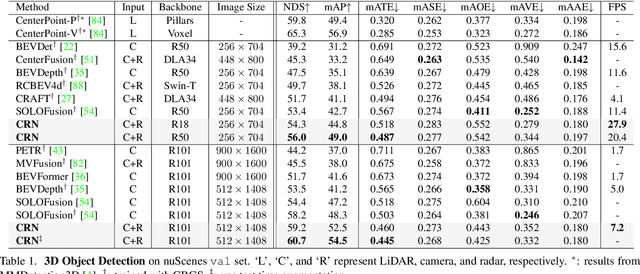
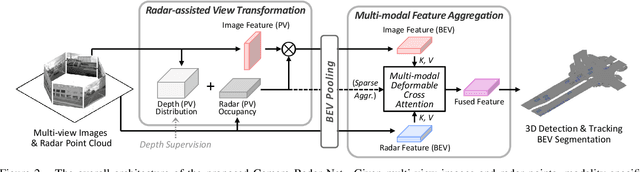
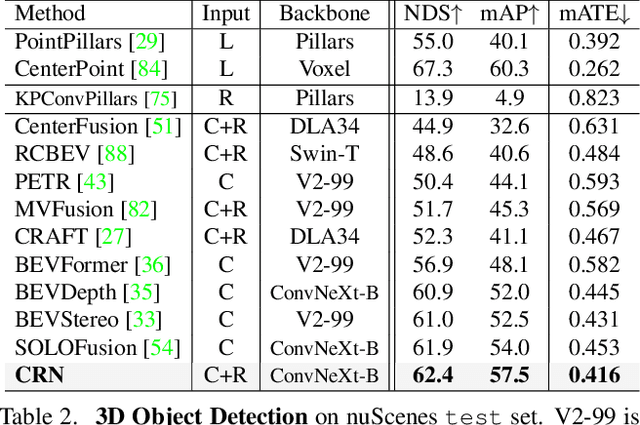
Autonomous driving requires an accurate and fast 3D perception system that includes 3D object detection, tracking, and segmentation. Although recent low-cost camera-based approaches have shown promising results, they are susceptible to poor illumination or bad weather conditions and have a large localization error. Hence, fusing camera with low-cost radar, which provides precise long-range measurement and operates reliably in all environments, is promising but has not yet been thoroughly investigated. In this paper, we propose Camera Radar Net (CRN), a novel camera-radar fusion framework that generates a semantically rich and spatially accurate bird's-eye-view (BEV) feature map for various tasks. To overcome the lack of spatial information in an image, we transform perspective view image features to BEV with the help of sparse but accurate radar points. We further aggregate image and radar feature maps in BEV using multi-modal deformable attention designed to tackle the spatial misalignment between inputs. CRN with real-time setting operates at 20 FPS while achieving comparable performance to LiDAR detectors on nuScenes, and even outperforms at a far distance on 100m setting. Moreover, CRN with offline setting yields 62.4% NDS, 57.5% mAP on nuScenes test set and ranks first among all camera and camera-radar 3D object detectors.
InstaGraM: Instance-level Graph Modeling for Vectorized HD Map Learning
Jan 10, 2023
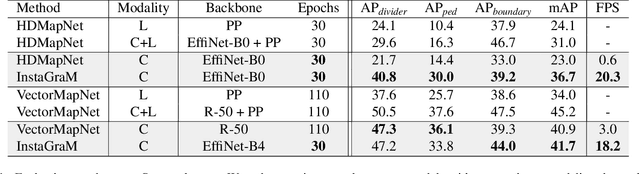
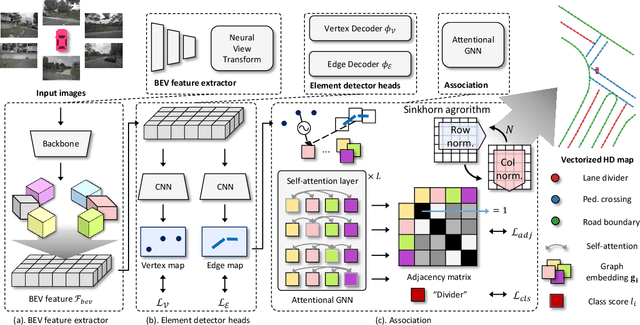
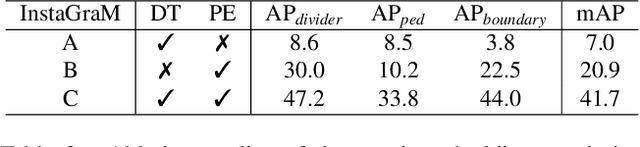
The construction of lightweight High-definition (HD) maps containing geometric and semantic information is of foremost importance for the large-scale deployment of autonomous driving. To automatically generate such type of map from a set of images captured by a vehicle, most works formulate this mapping as a segmentation problem, which implies heavy post-processing to obtain the final vectorized representation. Alternative techniques have the ability to generate an HD map in an end-to-end manner but rely on computationally expensive auto-regressive models. To bring camera-based to an applicable level, we propose InstaGraM, a fast end-to-end network generating a vectorized HD map via instance-level graph modeling of the map elements. Our strategy consists of three main stages: top-view feature extraction, road elements' vertices and edges detection, and conversion to a semantic vector representation. After top-down feature extraction, an encoder-decoder architecture is utilized to predict a set of vertices and edge maps of the road elements. Finally, these vertices along with edge maps are associated through an attentional graph neural network generating a semantic vectorized map. Instead of relying on a common segmentation approach, we propose to regress distance transform maps as they provide strong spatial relations and directional information between vertices. Comprehensive experiments on nuScenes dataset show that our proposed network outperforms HDMapNet by 13.7 mAP and achieves comparable accuracy with VectorMapNet 5x faster inference speed.