 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Feature Enhanced Knowledge Graph Embedding and Spatial Reasoning
Oct 24, 2024

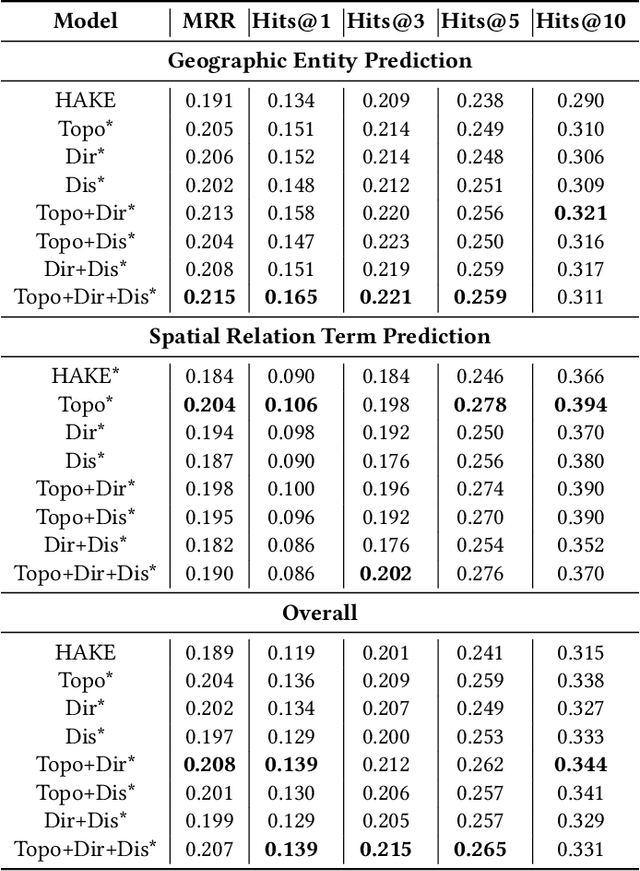

Geospatial Knowledge Graphs (GeoKGs) model geoentities (e.g., places and natural features) and spatial relationships in an interconnected manner, providing strong knowledge support for geographic applications, including data retrieval, question-answering, and spatial reasoning. However, existing methods for mining and reasoning from GeoKGs, such as popular knowledge graph embedding (KGE) techniques, lack geographic awareness. This study aims to enhance general-purpose KGE by developing new strategies and integrating geometric features of spatial relations, including topology, direction, and distance, to infuse the embedding process with geographic intuition. The new model is tested on downstream link prediction tasks, and the results show that the inclusion of geometric features, particularly topology and direction, improves prediction accuracy for both geoentities and spatial relations. Our research offers new perspectives for integrating spatial concepts and principles into the GeoKG mining process, providing customized GeoAI solutions for geospatial challenges.
AutoFAIR : Automatic Data FAIRification via Machine Reading
Aug 07, 2024



The explosive growth of data fuels data-driven research, facilitating progress across diverse domains. The FAIR principles emerge as a guiding standard, aiming to enhance the findability, accessibility, interoperability, and reusability of data. However, current efforts primarily focus on manual data FAIRification, which can only handle targeted data and lack efficiency. To address this issue, we propose AutoFAIR, an architecture designed to enhance data FAIRness automately. Firstly, We align each data and metadata operation with specific FAIR indicators to guide machine-executable actions. Then, We utilize Web Reader to automatically extract metadata based on language models, even in the absence of structured data webpage schemas. Subsequently, FAIR Alignment is employed to make metadata comply with FAIR principles by ontology guidance and semantic matching. Finally, by applying AutoFAIR to various data, especially in the field of mountain hazards, we observe significant improvements in findability, accessibility, interoperability, and reusability of data. The FAIRness scores before and after applying AutoFAIR indicate enhanced data value.
Temporal Generalization Estimation in Evolving Graphs
Apr 07, 2024



Graph Neural Networks (GNNs) are widely deployed in vast fields, but they often struggle to maintain accurate representations as graphs evolve. We theoretically establish a lower bound, proving that under mild conditions, representation distortion inevitably occurs over time. To estimate the temporal distortion without human annotation after deployment, one naive approach is to pre-train a recurrent model (e.g., RNN) before deployment and use this model afterwards, but the estimation is far from satisfactory. In this paper, we analyze the representation distortion from an information theory perspective, and attribute it primarily to inaccurate feature extraction during evolution. Consequently, we introduce Smart, a straightforward and effective baseline enhanced by an adaptive feature extractor through self-supervised graph reconstruction. In synthetic random graphs, we further refine the former lower bound to show the inevitable distortion over time and empirically observe that Smart achieves good estimation performance. Moreover, we observe that Smart consistently shows outstanding generalization estimation on four real-world evolving graphs. The ablation studies underscore the necessity of graph reconstruction. For example, on OGB-arXiv dataset, the estimation metric MAPE deteriorates from 2.19% to 8.00% without reconstruction.
GeoGalactica: A Scientific Large Language Model in Geoscience
Dec 31, 2023

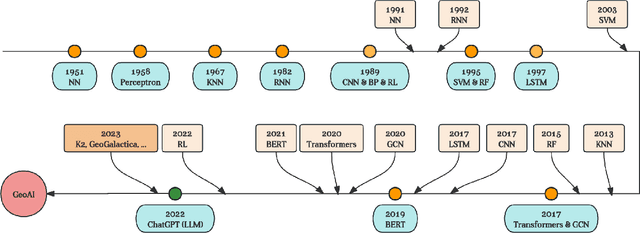
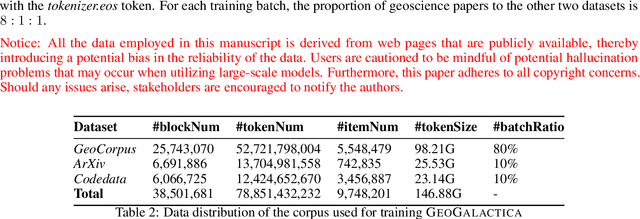
Large language models (LLMs) have achieved huge success for their general knowledge and ability to solve a wide spectrum of tasks in natural language processing (NLP). Due to their impressive abilities, LLMs have shed light on potential inter-discipline applications to foster scientific discoveries of a specific domain by using artificial intelligence (AI for science, AI4S). In the meantime, utilizing NLP techniques in geoscience research and practice is wide and convoluted, contributing from knowledge extraction and document classification to question answering and knowledge discovery. In this work, we take the initial step to leverage LLM for science, through a rather straightforward approach. We try to specialize an LLM into geoscience, by further pre-training the model with a vast amount of texts in geoscience, as well as supervised fine-tuning (SFT) the resulting model with our custom collected instruction tuning dataset. These efforts result in a model GeoGalactica consisting of 30 billion parameters. To our best knowledge, it is the largest language model for the geoscience domain. More specifically, GeoGalactica is from further pre-training of Galactica. We train GeoGalactica over a geoscience-related text corpus containing 65 billion tokens curated from extensive data sources in the big science project Deep-time Digital Earth (DDE), preserving as the largest geoscience-specific text corpus. Then we fine-tune the model with 1 million pairs of instruction-tuning data consisting of questions that demand professional geoscience knowledge to answer. In this technical report, we will illustrate in detail all aspects of GeoGalactica, including data collection, data cleaning, base model selection, pre-training, SFT, and evaluation. We open-source our data curation tools and the checkpoints of GeoGalactica during the first 3/4 of pre-training.
A Multimodal Ecological Civilization Pattern Recommendation Method Based on Large Language Models and Knowledge Graph
Oct 29, 2023



The Ecological Civilization Pattern Recommendation System (ECPRS) aims to recommend suitable ecological civilization patterns for target regions, promoting sustainable development and reducing regional disparities. However, the current representative recommendation methods are not suitable for recommending ecological civilization patterns in a geographical context. There are two reasons for this. Firstly, regions have spatial heterogeneity, and the (ECPRS)needs to consider factors like climate, topography, vegetation, etc., to recommend civilization patterns adapted to specific ecological environments, ensuring the feasibility and practicality of the recommendations. Secondly, the abstract features of the ecological civilization patterns in the real world have not been fully utilized., resulting in poor richness in their embedding representations and consequently, lower performance of the recommendation system. Considering these limitations, we propose the ECPR-MML method. Initially, based on the novel method UGPIG, we construct a knowledge graph to extract regional representations incorporating spatial heterogeneity features. Following that, inspired by the significant progress made by Large Language Models (LLMs) in the field of Natural Language Processing (NLP), we employ Large LLMs to generate multimodal features for ecological civilization patterns in the form of text and images. We extract and integrate these multimodal features to obtain semantically rich representations of ecological civilization. Through extensive experiments, we validate the performance of our ECPR-MML model. Our results show that F1@5 is 2.11% higher compared to state-of-the-art models, 2.02% higher than NGCF, and 1.16% higher than UGPIG. Furthermore, multimodal data can indeed enhance recommendation performance. However, the data generated by LLM is not as effective as real data to a certain extent.
Unveiling Optimal SDG Pathways: An Innovative Approach Leveraging Graph Pruning and Intent Graph for Effective Recommendations
Sep 21, 2023



The recommendation of appropriate development pathways, also known as ecological civilization patterns for achieving Sustainable Development Goals (namely, sustainable development patterns), are of utmost importance for promoting ecological, economic, social, and resource sustainability in a specific region. To achieve this, the recommendation process must carefully consider the region's natural, environmental, resource, and economic characteristics. However, current recommendation algorithms in the field of computer science fall short in adequately addressing the spatial heterogeneity related to environment and sparsity of regional historical interaction data, which limits their effectiveness in recommending sustainable development patterns. To overcome these challenges, this paper proposes a method called User Graph after Pruning and Intent Graph (UGPIG). Firstly, we utilize the high-density linking capability of the pruned User Graph to address the issue of spatial heterogeneity neglect in recommendation algorithms. Secondly, we construct an Intent Graph by incorporating the intent network, which captures the preferences for attributes including environmental elements of target regions. This approach effectively alleviates the problem of sparse historical interaction data in the region. Through extensive experiments, we demonstrate that UGPIG outperforms state-of-the-art recommendation algorithms like KGCN, KGAT, and KGIN in sustainable development pattern recommendations, with a maximum improvement of 9.61% in Top-3 recommendation performance.